
csstree
A tool set for CSS including fast detailed parser, walker, generator and lexer based on W3C specs and browser implementations
MIT License
Bot releases are visible (Hide)
Published by lahmatiy about 5 years ago
- Dropped support for Node < 8
- Updated dev deps (fixed
npm auditissues) - Reworked build pipeline
- Package provides
dist/csstree.jsanddist/csstree.min.jsnow (instead of singledist/csstree.jsthat was a min version) - Bundle size (min version) reduced from 191Kb to 158Kb due to some optimisations
- Package provides
- Definition syntax
- Renamed
grammarintodefinitionSyntax(named per spec) - Added
compactoption togenerate()method to avoid formatting (spaces) when possible
- Renamed
- Lexer
- Changed
dump()method to produce syntaxes in compact form by default
- Changed
Published by lahmatiy about 5 years ago
- Walker
- Changed implementation to avoid runtime compilation due to CSP issues (see #91, #109)
- Added
find(),findLast()andfindAll()methods (e.g.csstree.find(ast, node => node.type === 'ClassSelector'))
Published by lahmatiy about 5 years ago
This release improves syntax matching by new features and some fixes.
Bracketed range notation
A couple month ago bracketed range notation was added to Values and Units spec. The notation allows restrict numeric values to some range. For example, <integer [0,∞]> is for positive integers, or <number [0,1]> that can be used for an alpha value.
Since the notation is new thing in syntax definition, it isn't used in specs yet. However, there is a PR (https://github.com/w3c/csswg-drafts/pull/3894) that will bring it to some specs. And CSSTree is ready for this.
Right now, the notation helped to remove <number-zero-one>, <number-one-or-greater> and <positive-integer> from generic types and define them using a regular grammar (thanks to the notation).
Low priority type matching
There are at least two productions that has a low priority in matching. It means that such productions give a chance for other production to claim a token, and if no one – claim a token. This release introduce a solution for such productions. It's hardcoded at the moment, but can be exposed if needed (i.e. if there are more such productions).
First production is <custom-ident>. The Values and Units spec states:
When parsing positionally-ambiguous keywords in a property value, a
<custom-ident>production can only claim the keyword if no other unfulfilled production can claim it.
This rule takes place in properties like <'animation'>, <'transition'> and <'list-style'>. Before solves in different ways:
-
<'animation'>– that's not an issue since<'custom-ident'>goes last, however a terms order can be changed in the future -
<'transition'>– there was a patch for<single-transition>that changes order of terms -
<'list-style'>– had no fixes, just didn't work in some cases (see #101)
And now, all those and the rest syntaxes work as expected.
Second production is a bit tricky. It's about "unitless zero" for <length> production. The spec states:
... if a
0could be parsed as either a<number>or a<length>in a property (such asline-height), it must parse as a<number>.
This rule takes place in properties like <'line-height'> or <'flex'>. And now it works per spec too (try it here):
Changes
- Bumped
mdn/datato2.0.4(#99) - Lexer
- Added bracketed range notation support and related refactoring
- Removed
<number-zero-one>,<number-one-or-greater>and<positive-integer>from generic types. In fact, types moved to patch, because those types can be expressed in a regular grammar due to bracketed range notation implemented - Added support for multiple token string matching
- Improved
<custom-ident>production matching to claim the keyword only if no other unfulfilled production can claim it (#101) - Improved
<length>production matching to claim "unitless zero" only if no other unfulfilled production can claim it - Changed lexer's constructor to prevent generic types override when used
- Fixed large
||- and&&-group matching, matching continues from the beginning on term match (#85) - Fixed checking that value has
var()occurrences when value is a string (such values can't be matched on syntax currently and fail with specific error that can be used for ignorance in validation tools) - Fixed
<declaration-value>and<any-value>matching when a value contains a function, parentheses or braces
Published by lahmatiy about 5 years ago
- Tokenizer
- Added
isBOM()function - Added
charCodeCategory()function - Removed
firstCharOffset()function (useisBOM()instead) - Removed
CHARCODEdictionary - Removed
INPUT_STREAM_CODE*dictionaries
- Added
- Lexer
- Allowed comments in matching value (just ignore them like whitespaces)
- Increased iteration count in value matching from 10k up to 15k
- Fixed missed
debugger(#104)
Published by lahmatiy over 5 years ago
- Lexer
- Fixed low priority productions matching by changing an approach for robust one (#103)
Published by lahmatiy over 5 years ago
Changes
- Lexer
- Fixed low priority productions matching in long
||-and&&-groups (#103)
- Fixed low priority productions matching in long
Published by lahmatiy over 5 years ago
This release took too many time to be released. But it was worth the wait, because it unlocks new possibilities and ways for further improvements.
Reworked tokenizer
CSSTree tends to be as close as possible to the specifications in reasonable way. It means that CSSTree deviates from specs because specs are generally targeted for user agents (browsers) rather than source processing tools like CSSTree.
Previously CSSTree's tokenizer used its own token types set, which were selected for better performance and to be convenient enough for building AST. However, this has restricted the further improvement of parser, lexer and even generator, since the basis of CSS is tokens. That's not obvious at first glance, but if you dig deep into specs you'll find that CSS syntax is described in tokens and their productions, serialization relay on tokens, even var() substitution takes place at the level of tokens and so on. Using own token types set means that many rules described in CSS specs can't be implemented as designed. That's why previously CSSTree's tokenizer was actually too far from specs.
In this release tokenizer was reworked to use token type set defined by CSS Syntax Module Level 3. Algorithms described by spec was adopted by tokenizer implementation and code is provided with excerpts from the specification. It allowed to be very close to spec and helped to fix numerous edge cases.
Current deviations from the CSS Syntax Module Level 3:
- No input preprocessing currently. It not a problem actually, since CSS processing tools usually do not do any preprocessing, and looks like it's fine. However, it can be added later via additional option to tokenizer and parser.
- No comments removal. According to spec tokenizer should not produce tokens for comments, or otherwise preserve them in any way. But comments are useful for source processing tools, so it looks reasonable to keep it as a comment token. Probably this will change in the future.
Influence on parser
Changing the token types set led to a significant alteration of parser implementation. Most dramatic changes in AnPlusB and UnicodeRange implementations, because those two microsyntaxes are really hard. Nevertheless, in general, most things became simpler. Also parser continues relaxing on parse stage, more delegating syntax checking to lexer. As a result some parsing errors are no longer occur, so tools using CSSTree have a chance to use AST even for partially invalid CSS.
This release doesn't change AST format. However, the format will be changing for sure in next releases to be closer to token type set. It will reduce more parse errors and increase tools possibilities.
Lexer
Lexer was slightly refactored. Most significant change, syntax matching relies on real CSS tokens produced by a tokenizer rather than generated from AST tokens. In other words, AST is translating to a string and then splitting into tokens by the tokenizer. Consequences of this:
- Since AST is not used directly for token producing and syntax matching, it became completely optional.
- A string can be used as a value for matching (i.e.
lexer.matchProperty('border', 'red 1px dotted')). So parsing into AST is not required anymore, and that's a good news for tools which using CSSTree for a validation and have another AST format or have no AST at all. - Types that is using tokens in their syntax is now can be used for matching. Such syntaxes was omitted from
mdn/databy CSSTree's patch recently. Fortunately, it is no longer needed (difference withmdn/data).
Work on lexer is not completed yet. This version removes some restrictions and its ready for further improvements like at-rules and selectors matching, better mathematical expressions (calc() and friends) support, attr()/toggle()/var() fallback checking, multiple errors, suggestions, improving matching performance and so on.
Change log (commits)
- Bumped
mdn/datato~2.0.3- Removed type removals from
mdn/datadue to lack of some generic types and specific lexer restictions (since lexer was reworked, see below) - Reduced and updated patches
- Removed type removals from
- Tokenizer
- Reworked tokenizer itself to compliment CSS Syntax Module Level 3
-
Tokenizerclass splitted into several abstractions:- Added
TokenStreamclass - Added
OffsetToLocationclass - Added
tokenize()function that createsTokenStreaminstance for given string or updates aTokenStreaminstance passed as second parameter - Removed
Tokenizerclass
- Added
- Removed
Rawtoken type - Renamed
Identifiertoken type toIdent - Added token types:
Hash,BadString,BadUrl,Delim,Percentage,Dimension,Colon,Semicolon,Comma,LeftSquareBracket,RightSquareBracket,LeftParenthesis,RightParenthesis,LeftCurlyBracket,RightCurlyBracket - Replaced
PunctuatorwithDelimtoken type, that excludes specific characters with its own token type likeColon,Semicolonetc - Removed
findCommentEnd,findStringEnd,findDecimalNumberEnd,findNumberEnd,findEscapeEnd,findIdentifierEndandfindUrlRawEndhelper function - Removed
SYMBOL_TYPE,PUNCTUATIONandSTOP_URL_RAWdictionaries - Added
isDigit,isHexDigit,isUppercaseLetter,isLowercaseLetter,isLetter,isNonAscii,isNameStart,isName,isNonPrintable,isNewline,isWhiteSpace,isValidEscape,isIdentifierStart,isNumberStart,consumeEscaped,consumeName,consumeNumberandconsumeBadUrlRemnantshelper functions
- Parser
- Changed parsing algorithms to work with new token type set
- Changed
HexColorconsumption in way to relax checking a value, i.e. nowvalueis a sequence of one or more name chars - Added
&as a property hack - Relaxed
var()parsing to only check that a first arguments is an identifier (not a custom property name as before)
- Lexer
- Reworked syntax matching to relay on token set only (having AST is optional now)
- Extended
Lexer#match(),Lexer#matchType()andLexer#matchProperty()methods to take a string as value, beside AST as a value - Extended
Lexer#match()method to take a string as a syntax, beside of syntax descriptor - Reworked generic types:
- Removed
<attr()>,<url>(moved to patch) and<progid>types - Added types:
- Related to token types:
<ident-token>,<function-token>,<at-keyword-token>,<hash-token>,<string-token>,<bad-string-token>,<url-token>,<bad-url-token>,<delim-token>,<number-token>,<percentage-token>,<dimension-token>,<whitespace-token>,<CDO-token>,<CDC-token>,<colon-token>,<semicolon-token>,<comma-token>,<[-token>,<]-token>,<(-token>,<)-token>,<{-token>and<}-token> - Complex types:
<an-plus-b>,<urange>,<custom-property-name>,<declaration-value>,<any-value>and<zero>
- Related to token types:
- Renamed
<unicode-range>to<urange>as per spec - Renamed
<expression>(IE legacy extension) to<-ms-legacy-expression>and may to be removed in next releases
- Removed
Published by lahmatiy over 6 years ago
A brand new syntax matching
This release brings a brand new syntax matching approach. The syntax matching is important feature that allow CSSTree to provide a meaning of each component in a declaration value, e.g. which component of a declaration value is a color, a length and so on. You can see example of matching result on CSSTree's syntax reference page:
Syntax matching is now based on CSS tokens and uses a state machine approach which fixes all problems it has before (see https://github.com/csstree/csstree/issues/67 for the list of issues).
Token-based matching
Previously syntax matching was based on AST nodes. Beside it possible to make syntax matching such way, it has several disadvantages:
- Synchronising of CSS parsing result (AST) and syntax description tree traverses is quite complicated:
- Every tree represents different things: one node type set for CSS parsing result and another one for syntax description tree
- Some AST nodes consist of several tokens and contain children nodes
- Some AST nodes doesn't contain symbols that will be in output on AST translating to string. For instance,
Functionnode contains a function name and a list of children, but it also produce parentheses that isn't store in AST. This introduces many hacks and workarounds. However, it was not enough since approach doesn't work for nodes likeBrackets. Also it forces matching algorithm to know a lot of about node types and their features.
Starting this release, AST (CSS parse result) is converting to a token stream before matching (using CSSTree's generator with a special decorator function). Syntax description tree is also converting into so called Match graph (see details below). Those tree transformations allow to align both tree to work in the same terms – CSS tokens.
This change make matching algorithm much simpler. Now it know nothing about AST structure, hacks and workarounds were removed. Moreover, syntaxes like <line-names> (contains brackets) and <calc()> (contains operators in nested syntaxes) are now can be matched (previously syntax matching failed for them).
Update syntax AST format
Since syntax matching moved from AST nodes to CSS tokens, syntax description tree format was also changed. For instance, functions is now represented as a token sequence. It allows to handle syntaxes that contains a group with several function tokens inside, like this one:
<color-adjuster> =
[red( | green( | blue( | alpha( | a(] ['+' | '-']? [<number> | <percentage>] ) |
[red( | green( | blue( | alpha( | a(] '*' <percentage> ) |
...
Despite that<color-mod()> syntax was recently removed from CSS Color Module Level 4, such syntaxes can appear in future, since valid (even looks odd).
As the result of format changes, all syntaxes in mdn/data can now be parsed, even invalid from the standpoint of CSS Values and Units Module Level 3 spec syntaxes. Due to this, some errors in syntaxes were found and fixed (https://github.com/mdn/data/pull/221, https://github.com/mdn/data/pull/226). Also some suggestions on syntax optimisation were made (https://github.com/mdn/data/pull/223, https://github.com/mdn/data/issues/230).
Introducing Match graph
As mentioned above, syntax tree is now transforming to Match graph. This happens on first match for a syntax and then reused. Match graph represents a graph of simple actions (states) and transitions between them. Some complicated thing, like multipliers, are translating in a set of nodes and edges. You can explore which a match graph is building for any syntax on CSSTree's syntax reference page, e.g. the match graph for <'animation-name'>:
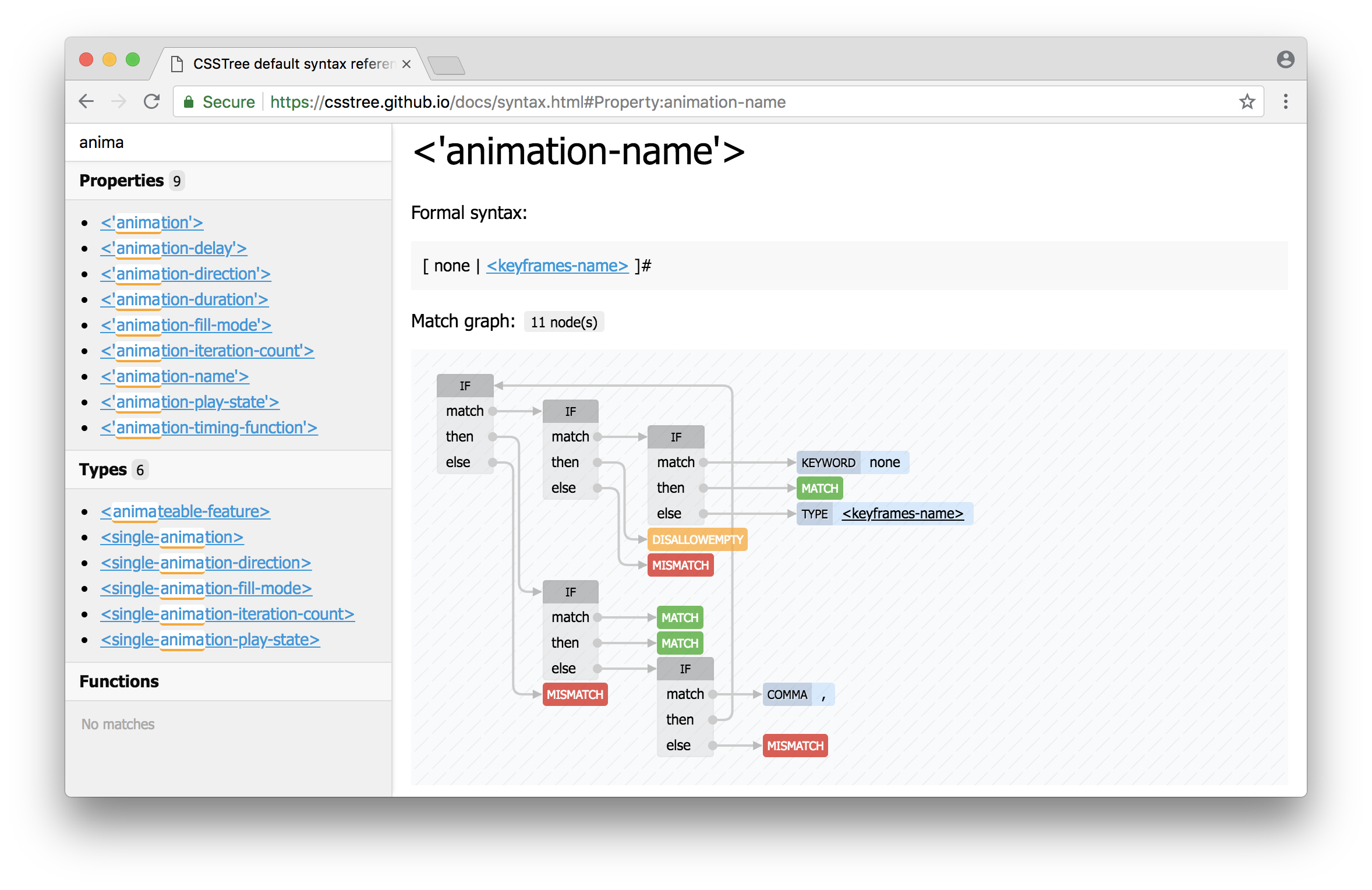
There were some challenges during implementation, most notable of them:
-
&&-and||-groups. Actually it was a technical blocker that suspended moving to match graph. Finally, a solution was found: split a groups in smaller one by removing a term one by one. For example,a && b && ccan be represented as following (pseudo code):
if match a
then [b && c]
else if match b
then [a && c]
else if match c
then [a && b]
else MISMATCH
So, a size of groups is reducing by one on each step, then we process the smaller groups until a group consists of a single term.
a && b
=
if match a
then if match b
then MATCH
else MISMATCH
else if match b
then if match a
then MATCH
else MISMATCH
else MISMATCH
It works fine, but for small groups only. Since it produces at least N! (factorial) nodes, where N is a number of terms in a group. Hopefully, there are not so many syntaxes that contain a group with a big number of terms for &&- or ||- group. However, font-variant syntax contains a group of 20 terms, that means at least 2,432,902,008,176,640,000 nodes in a graph. It's huge and we can't create such number of object due a memory limit. So, alternative solution for groups greater than 5 terms was introduced, it uses special buffer and iterate terms in a loop. The solution is not ideal, but there are just 9 such groups (with 6 or more terms) across all syntaxes, so it should be ok for now.
- A comma. The task turned out to be a tough nut to crack, because of specific rules. For example, if we have a syntax like that:
a?, b?, c?
We can match a, b, c, a, c, b, b, c and so on. But input like , b, c, a, , c or a, is not allowed. In other words, comma must not be hanged and must not be followed by an another comma. And when comma is matching to an input, it should notify a positive match even there is no a comma token in the input. This was a blocker that could cancel the whole approach.
Nevertheless, the problem was solved in elegant way, by checking adjacent tokens for a several patterns. It most non-trivial part of new syntax matching, several lines of code works well only with along other parts of implementation, so may looks like a magic.
Using state machine
Another improvement in syntax matching is replacing a recursion-based algorithm with a state machine approach. This allowed to check all possible alternatives during the syntax matching. Previously if nothing matched by a chosen path, algorithm just exited with a mismatch result. New algorithm is returning back to a branching point and choose an alternative path when possible. This fixes following:
- Syntaxes with alternative paths, like
<bg-position>.
<bg-position> =
[ left | center | right | top | bottom | <length-percentage> ] |
[ left | center | right | <length-percentage> ] [ top | center | bottom | <length-percentage> ] |
[ center | [ left | right ] <length-percentage>? ] && [ center | [ top | bottom ] <length-percentage>? ]
This syntax didn't work before, since it defines shortest form first and matching fell in this path with no chance to use an alternative path. However, reverse order of groups in this syntax makes it work with old algorithm.
Another example is a new syntax for <rgb()>:
rgb() = rgb( <percentage>{3} [ / <alpha-value> ]? ) |
rgb( <number>{3} [ / <alpha-value> ]? ) |
rgb( <percentage>#{3} , <alpha-value>? ) |
rgb( <number>#{3} , <alpha-value>? )
Old algorithm doesn't exit from a function content when matched a function, and can't handle such syntaxes. To make matching work for syntaxes like this one, an adoption is required (by a patch as workaround). Now patches are not required.
Matching for syntaxes not compatible with greedy algorithms. For instance, syntax of composes (CSS Modules) is defined as <custom-ident>+ from <string>, and old matching algorithm failed on it because from is a valid value for <custom-ident> and it's capturing by <custom-ident>+ with no alternatives. New algorithm is not greedy, on first try it takes a minimum count of tokens allowed by a syntax and increases that count if possible on each returning in the branching point. Syntaxes like composes can be matched now as well.
A state machine approach gives some other benefits like a precise error locations. Previously, location of a problem could be confusing:
SyntaxMatchError: Mismatch
syntax: ...
value: rgb(1,2)
------------^
And now it's more helpful:
SyntaxMatchError: Mismatch
syntax: ...
value: rgb(1,2)
---------------^
Further improvements on syntax matching can improve error handling and probably provide some sort of suggestions.
Performance
New syntax matching approach requires more memory and time, because of AST to token stream transformation and checking all possible alternatives. However, new approach is more effective itself and have a room for further optimisations. Usually it takes the same or ~50% more time (depending on syntax and a matching value) compared with previous algorithm. So that's not a big deal.
The main goal the release was make it all works, so not every possible optimisation were implemented and more will come in next releases.
Other changes
- Lexer
- Syntax matching was completely reworked. Now it's token-based and uses state machine. Public API has not changed. However, some internal data structures have changed. Most significant change in syntax match result tree structure, it's became token-based instead of node-based.
- Grammar
- Changed grammar tree format:
- Added
Tokennode type to represent a single code point (<delim-token>) - Added
Multiplierthat wraps a single node (termproperty) - Added
AtKeywordto represent<at-keyword-token> - Removed
SlashandPercentnode types, they are replaced for a node withTokentype - Changed
Functionto represent<function-token>with no children - Removed
multiplierproperty fromGroup
- Added
- Changed
generate()method:- Method takes an
optionsas second argument now (generate(node, forceBraces, decorator)->generate(node, options)). Two options are supported:forceBracesanddecorator - When a second parameter is a function it treats as
decorateoption value, i.e.generate(node, fn)->generate(node, { decorate: fn }) - Decorate function invokes with additional parameter – a reference to a node
- Method takes an
- Changed grammar tree format:
- Tokenizer
- Renamed
Atruleconst toAtKeyword
- Renamed
Published by lahmatiy over 6 years ago
- Renamed
lexer.grammar.translate()method intogenerate() - Fixed
<'-webkit-font-smoothing'>and<'-moz-osx-font-smoothing'>syntaxes (#75) - Added vendor keywords for
<'overflow'>property syntax (#76) - Pinned
mdn-datato~1.1.0and fixed issues with some updated property syntaxes
Published by lahmatiy almost 7 years ago
Most of the changes of this release relate to rework of generator and walker. Instead of plenty methods there just single method for each one: generate() for the generator and walk() for the walker. Both methods take two arguments ast and options (optional for the generator). This makes API much simpler (see details about API in Translate AST to string and AST traversal):

Also List class API was extended, and some utils methods such as keyword() and property() were changed to be more useful.
Generator
- Changed node's
generate()methods invocation, methods now take a node as a single argument and context (i.e.this) that have methods:chunk(),node()andchildren() - Renamed
translate()togenerate()and changed to takeoptionsargument - Removed
translateMarkup(ast, enter, leave)method, usegenerate(ast, { decorator: (handlers) => { ... }})instead - Removed
translateWithSourceMap(ast), usegenerate(ast, { sourceMap: true })instead - Changed to support for children as an array
Walker
- Changed
walk()to take anoptionsargument instead of handler, withenter,leave,visitandreverseoptions (walk(ast, fn)is still works and equivalent towalk(ast, { enter: fn })) - Removed
walkUp(ast, fn), usewalk(ast, { leave: fn }) - Removed
walkRules(ast, fn), usewalk(ast, { visit: 'Rule', enter: fn })instead - Removed
walkRulesRight(ast, fn), usewalk(ast, { visit: 'Rule', reverse: true, enter: fn })instead - Removed
walkDeclarations(ast, fn), usewalk(ast, { visit: 'Declaration', enter: fn })instead - Changed to support for children as array in most cases (
reverse: truewill fail on arrays since they have noforEachRight()method)
Misc
- List
- Added
List#forEach()method - Added
List#forEachRight()method - Added
List#filter()method - Changed
List#map()method to return aListinstance instead ofArray - Added
List#push()method, similar toList#appendData()but returns nothing - Added
List#pop()method - Added
List#unshift()method, similar toList#prependData()but returns nothing - Added
List#shift()method - Added
List#prependList()method - Changed
List#insert(),List#insertData(),List#appendList()andList#insertList()methods to return a list that performed an operation
- Added
- Changed
keyword()method- Changed
namefield to include a vendor prefix - Added
basenamefield to contain a name without a vendor prefix - Added
customfield that contain atruewhen keyword is a custom property reference
- Changed
- Changed
property()method- Changed
namefield to include a vendor prefix - Added
basenamefield to contain a name without any prefixes, i.e. a hack and a vendor prefix
- Changed
- Added
vendorPrefix()method - Added
isCustomProperty()method
Published by lahmatiy almost 7 years ago
This journey started a couple months ago with 1.0.0-alpha20, which added tolerant parsing mode as experimental feature, available behind tolerant option. During 5 releases, the feature was tested on various data, numerous errors and edge cases were fixed. The last necessary changes were made in this release, which makes the feature ready for use. So, I proud to say, CSSTree parser is tolerant to errors by default now.
That's the significant change, and this meets CSS Syntax Module Level 3, which says:
When errors occur in CSS, the parser attempts to recover gracefully, throwing away only the minimum amount of content before returning to parsing as normal. This is because errors aren’t always mistakes - new syntax looks like an error to an old parser, and it’s useful to be able to add new syntax to the language without worrying about stylesheets that include it being completely broken in older UAs.
In other words, spec compliant CSS parser should be able to parse any text as a CSS with no errors. CSSTree is now such parser! 🎉
The only thing the CSSTree parser departs from the specification is that it doesn't throw away bad content, but wraps it in the Raw nodes, which allows processing it later. This discrepancy is due to the fact that the specification is written for UA that extract meaning from CSS, so incomprehensible parts simply do not make sense to them and can be ignored. CSSTree has a wider range of tasks, and most of them are related to the processing of the source code. These are tasks such as locating errors, error correction, preprocessing, and so on.
Tolerant mode means you don't need to wrap csstree.parse() into try/catch. To collect parse errors onParseError handler should be set in parse options:
var csstree = require('css-tree');
csstree.parse('I must! be tolerant to errors', {
onParseError: function(e) {
console.error(e.formattedMessage);
}
});
// Parse error: Unexpected input
// 1 |I must! be tolerant to errors
// -------------^
// Parse error: LeftCurlyBracket is expected
// 1 |I must! be tolerant to errors
// ------------------------------------^
If you need old parser behaviour, just throw an exception inside onParseError handler, that immediately stops a parsing:
try {
csstree.parse('I must! be tolerant to errors', {
onParseError: function(e) {
throw e;
}
});
} catch(e) {
console.error(e.formattedMessage);
}
// Parse error: Unexpected input
// 1 |I must! be tolerant to errors
// -------------^
Changes
- Tokenizer
- Added
Tokenizer#isBalanceEdge()method - Removed
Tokenizer.endsWith()method
- Added
- Parser
- Made the parser tolerant to errors by default
- Removed
tolerantparser option (no parsing modes anymore) - Removed
propertyparser option (a value parsing does not depend on property name anymore) - Canceled error for a handing semicolon in a block
- Canceled error for unclosed
Brackets,FunctionandParentheseswhen EOF is reached - Fixed error when prelude ends with a comment for at-rules with custom prelude consumer
- Relaxed at-rule parsing:
- Canceled error when EOF is reached after a prelude
- Canceled error for an at-rule with custom block consumer when at-rule has no block (just don't apply consumer in that case)
- Canceled error on at-rule parsing when it occurs outside prelude or block (at-rule is converting to
Rawnode) - Allowed for any at-rule to have a prelude and a block, even if it's invalid per at-rule syntax (the responsibility for this check is moved to lexer, since it's possible to construct a AST with such errors)
- Made a declaration value a safe parsing point (i.e. error on value parsing lead to a value is turning into
Rawnode, not a declaration as before) - Excluded surrounding white spaces and comments from a
Rawnode that represents a declaration value - Changed
Valueparse handler to return a node only with typeValue(previously it returned aRawnode in some cases) - Fixed issue with
onParseError()is not invoked on parse errors on selector and declaration value - Changed using of
onParseError()to stop parsing if handler throws an exception
- Lexer
- Changed
grammar.walk()to invoke passed handler on entering to node rather than on leaving the node - Improved
grammar.walk()to take a walk handler pair as an object, i.e.walk(node, { enter: fn, leave: fn }) - Changed
Lexer#match*()methods to take a node of any type, but with achildrenfield - Added
Lexer#match(syntax, node)method - Fixed
Lexer#matchType()method to stop return a positive result for the CSS wide keywords
- Changed
Published by lahmatiy about 7 years ago
- Parser
- Added fallback node as argument to
onParseError()handler - Fixed raw consuming in tolerant mode when selector is invalid (greedy consuming and redundant warnings)
- Fixed exception in tolerant mode caused by unknown at-rule with unclosed block
- Changed handling of semicolons:
- Hanging semicolon inside declaration blocks raises an error or turns into a
Rawnode in tolerant mode instead of being ignored - Semicolon outside of declaration blocks opens a
Rulenode as part of selector instead of being ignored
- Hanging semicolon inside declaration blocks raises an error or turns into a
- Aligned
parseAtrulePreludebehaviour toparseRulePrelude- Removed
Rawnode wraping intoAtrulePreludewhenparseAtrulePreludeis disabled - Removed error emitting when at-rule has a custom prelude customer but no prelude is found (it should be validated by a lexer later)
- Removed
- Added fallback node as argument to
- Generator
- Fixed performance issue with
translateWithSourceMap(), flattening the string (because of mixing building string and indexing into it) turned it into a quadratic algorithm (approximate numbers can be found in the quiz created by this case)
- Fixed performance issue with
- Added support for a single solidus hack for
property() - Minor fixes for custom errors
Published by lahmatiy about 7 years ago
- Improved CSSTree to be stable for standart build-in objects extension (#58)
- Parser
- Renamed rule's
selectortoprelude. The reasons: spec names this part so, and this branch can contain not a selector only (SelectorList) but also a raw payload (Raw). What's changed:- Renamed
Rule.selectortoRule.prelude - Renamed
parseSelectorparser option toparseRulePrelude - Removed option for selector parse in
SelectorList
- Renamed
- Renamed rule's
- Lexer
- Fixed undefined positions in a error when match a syntax to empty or white space only value
- Improved
Lexer#checkStructure()- Return a warning as an object with node reference and message
- No exception on unknown node type, return a warning instead
Published by lahmatiy about 7 years ago
- Fixed
Tokenizer#getRawLength()'s false positive balance match to the end of input in some cases (#56) - Rename walker's entry point methods to be the same as CSSTree exposed methods (i.e.
walk(),walkUp()etc) - Rename at-rule's
expressiontoprelude(since spec names it so)-
AtruleExpressionnode type →AtrulePrelude -
Atrule.expressionfield →Atrule.prelude -
parseAtruleExpressionparser's option →parseAtrulePrelude -
atruleExpressionparse context →atrulePrelude -
atruleExpressionwalk context reference →atrulePrelude
-
Published by lahmatiy about 7 years ago
- Parser
- Fixed exception on parsing of unclosed
{}-blockin tolerant mode - Added tolerant mode support for
DeclarationList - Added standalone entry point, i.e. default parser can be used via
require('css-tree/lib/parser')(#47)
- Fixed exception on parsing of unclosed
- Generator
- Changed generator to produce
+nwhenAnPlusB.ais+1to be "round-trip" with parser - Added standalone entry point, i.e. default generators can be used via
require('css-tree/lib/generator')
- Changed generator to produce
- Walker
- Added standalone entry point, i.e. default walkers can be used via
require('css-tree/lib/walker')(#47)
- Added standalone entry point, i.e. default walkers can be used via
- Lexer
- Added
defaultkeyword to the list of invalid values for<custom-ident>(since it reversed per spec)
- Added
- Convertors (
toPlainObject()andfromPlainObject()) moved tolib/convertor(entry point isrequire('css-tree/lib/convertor'))
Published by lahmatiy about 7 years ago
- Tokenizer
- Added
Rawtoken type - Improved tokenization of
url()with raw as url to be more spec complient - Added
Tokenizer#balancearray computation on token layout - Added
Tokenizer#getRawLength()to compute a raw length with respect of block balance - Added
Tokenizer#getTokenStart(offset)method to get token start offset by token index - Added
idxandbalancefields to each token ofTokenizer#dump()method result
- Added
- Parser
- Added
onParseErroroption - Reworked node parsers that consume a
Rawnode to use a new approach. Since now aRawnode builds inparser#Raw()function onlу - Changed semantic of
parser#Raw(), it takes 5 parameters now (it might to be changed in future) - Changed
parser#tolerantParse()to pass a start token index to fallback function instead of source offset - Fixed
AtruleExpressionconsumption in tolerant mode - Atrule handler to convert an empty
AtruleExpressionnode intonull - Changed
AtruleExpressionhandler to always return a node (before it could return anullin some cases)
- Added
- Lexer
- Fixed comma match node for
#multiplier - Added reference name to
SyntaxReferenceError
- Fixed comma match node for
- Additional fixes on custom errors
- Reduced possible corruption of base config by
syntax.fork()
Published by lahmatiy about 7 years ago
- Tokenizer
- Added
Atruletoken type (<at-rule-token>per spec) - Added
Functiontoken type (<function-token>per spec) - Added
Urltoken type - Replaced
Tokenizer#getTypes()method withTokenizer#dump()to get all tokens as an array - Renamed
Tokenizer.TYPE.WhitespacetoTokenizer.TYPE.WhiteSpace - Renamed
Tokenizer.findWhitespaceEnd()toTokenizer.findWhiteSpaceEnd()
- Added
- Parser
- Added initial implementation of tollerant mode (turn on by passing
tolerant: trueoption). In this mode parse errors are never occour and any invalid part of CSS turns into aRawnode. Current safe points:Atrule,AtruleExpression,Rule,SelectorandDeclaration. Feature is experimental and further improvements are planned. - Changed
Atrule.expressionto contain aAtruleExpressionnode ornullonly (other node types is wrapping into aAtruleExpressionnode) - Renamed
AttributeSelector.operatortoAttributeSelector.matcher
- Added initial implementation of tollerant mode (turn on by passing
- Generator
-
translate()method is now can take a function as second argument, that recieves every generated chunk. When no function is passed, default handler is used, it concats all the chunks and method returns a string.
-
- Lexer
- Used mdn/data package as source of lexer's grammar instead of local dictionaries
- Added
xunit to<resolution>generic type - Improved match tree:
- Omited Group (sequences) match nodes
- Omited empty match nodes (for terms with
zero or moremultipliers) - Added
ASTNodenode type to contain a reference to AST node - Fixed node duplication (uncompleted match were added to tree)
- Added AST node reference in match nodes
- Added comma match node by
#multiplier
- Grammar
- Changed
translate()function to get a handler as third argument (optional). That handler recieves result of node traslation and can be used for decoration purposes. See example - Added
SyntaxParseErrorto grammar export - Reworked group and multipliers representation in syntax tree:
- Replaced
SequenceforGroupnode type (Sequencenode type removed) - Added
explicitboolean property forGroup - Only groups can have a multiplier now (other node types is wrapping into a single term implicit group when multiplier is applied)
- Renamed
nonEmptyGroup's property todisallowEmpty - Added optimisation for syntax tree by dropping redundant root
Groupwhen it contains a singleGroupterm (return thisGroupas a result)
- Replaced
- Changed
- Changed lexer's match functionality
- Changed
Lexer#matchProperty()andLexer#matchType()to return an object instead of match tree. A match tree stores inmatchedfield when AST is matched to grammar successfully, otherwise an error inerrorfield. The result object also has some methods to test AST node against a match tree:getTrace(),isType(),isProperty()andisKeyword() - Added
Lexer#matchDeclaration()method - Removed
Lexer#lastMatchError(error stores in match result object inerrorfield)
- Changed
- Added initial implementation of search for AST segments (new lexer methods:
Lexer#findValueSegments(),Lexer#findDeclarationValueSegments()andLexer#findAllSegments) - Implemented
SyntaxReferenceErrorfor unknown property and type references
- Renamed field in resulting object of
property()function:variable→custom - Fixed issue with readonly properties (e.g.
lineandcolumn) ofErrorand exception on attempt to write in iOS Safari
Published by lahmatiy over 7 years ago
- Extended
Listclass with new methods:List#prepend(item)List#prependData(data)List#insertData(data)List#insertList(list)List#replace(item, itemOrList)
Published by lahmatiy over 7 years ago
- Added
atrulewalk context (#39) - Changed a result of generate method for
AnPlusB,AttributeSelector,Function,MediaFeatureandRatio(1e95877) - Fixed typo in
Listexception messages (@strarsis, #42) - Improved tokenizer to convert an input to a string
Published by lahmatiy over 7 years ago
Extensibility
The main goal of CSSTree is to provide standard CSS parsing as good as possible. However, use cases has shown that it would be useful to easily extend the syntax to make possible experimenting with new CSS modules and features. Therefore, in this release CSSTree is making the first step towards extensibility through a new concept called syntax.
Syntax is a set of tools: parser, walkers, lexer, generators and other functions to deal with some variant of CSS syntax. By default it's a standard CSS syntax with implementators features (e.g. hacks and extensions). This syntax may be extended by fork() method, which returns a new syntax (fork) with modified functionality (when needed) but the same API.
The approach allows to experiment with new CSS features that haven't been implemented yet by browsers, and provide support for CSS extensions (like CSS Modules, and even SCSS or Less syntaxes) at a new level. To reach that goal syntax is described in a declarative way with minimal efforts from the developer. Initial CSS syntax definition speaks for itself. It will be completed and improved in upcoming releases.
Real Web CSS
It's hard enough to understand how good a parser is. There are several problems here, the most notable is the lack of appropriate test suites to test the parser across specs and implementations. As you may know, adoption of CSS is not consistent by browsers, it's changing so fast and don't forget about legacy. Too many things we should care about.
That's the reason why Real Web CSS project was created. The project’s scripts take Alexa Top 250 websites, crawl their CSS, and try to parse and validate them. The results can be found in this table. As you can see there are various issues around the Web, many of websites have a broken CSS and validation warnings. Although this test also has revealed weaknesses of CSSTree and most them were fixed by this release.
This simple test on real Web CSS already showed many problems on sites and CSSTree. And that's just a beginning. We believe it will help to make Web and CSSTree better.
Changes
- Implemented new concept of
syntax- Changed main
exportsto expose a default syntax - Defined initial CSS syntax
- Implemented
createSyntax()method to create a new syntax from scratch - Implemented
fork()method to create a new syntax based on given via extension
- Changed main
- Parser
- Implemented
mediaQueryListandmediaQueryparsing contexts - Implemented
CDOandCDCnode types - Implemented additional declaration property prefix hacks (
#and+) - Added support for UTF-16LE BOM
- Added support for
@font-faceat-rule - Added
chroma()to legacy IE filter functions - Improved
HexColorto consume hex only - Improved support for
\0and\9hacks (#2) - Relaxed number check for
Ratioterms- Allowed fractal values as a
Ratioterm - Disallowed zero number as a
Ratioterm
- Allowed fractal values as a
- Changed important clause parsing
- Allowed any identifier for important (to support hacks like
!ie) - Store
trueforimportantfield in case identifier equals toimportantand string otherwise
- Allowed any identifier for important (to support hacks like
- Fixed parse error formatted message rendering to take into account tabs
- Removed exposing of
Parserclass - Removed
readSelectorSequence(),readSequenceFallback()andreadSelectorSequenceFallbackmethods - Used single universal sequence consumer for
AtruleExpression,SelectorandValue
- Implemented
- Generator
- Reworked generator to use auto-generated functions based on syntax definition (additional work to be done in next releases)
- Implemented
translateMarkup(ast, before, after)method for complex cases - Reworked
translateWithSourceMapto be more flexible (based ontranslateMarkup, additional work to be done in next releases)
- Walker
- Reworked walker to use auto-generated function based on syntax definition (additional work to be done in next releases)
- Lexer
- Prepared for better extensibility (additional work to be done in next releases)
- Implemented
checkStructure(ast)method to check AST structure based on syntax definition - Update syntax dictionaries to latest
mdn/data- Add missing
<'offset-position'>syntax - Extended
<position>property with-webkit-sticky(@sergejmueller, #37)
- Add missing
- Improved mismatch error position
- Implemented script (
gen:syntax) to generate AST format reference page (docs/ast.md) using syntax definition

