
ludwig
Low-code framework for building custom LLMs, neural networks, and other AI models
APACHE-2.0 License
Published by tgaddair over 1 year ago
What's Changed
- Fixed confidence_penalty by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3158
- Fixed set explanations by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3163
- Bump to hummingbird 0.4.8 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3165
- Unpin pyarrow by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3171
- Make Horovod an optional dependency when using Ray by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3172
- Cherry-pick sample ratio changes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3176
- Fix TorchVision channel preprocessing (#3173) by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3178
- Bump Ludwig to v0.7.1 (#3179) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3180
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.7...v0.7.1
Published by tgaddair over 1 year ago
Key Highlights
- Pretrained Vision Models: we’ve added 20 additional TorchVision pretrained models as image encoders, including: AlexNet, EfficientNet, MobileNet v3, and GoogleLeNet.
- Image Augmentation: Ludwig v0.7 also introduces image augmentation, artificially increasing the size of the training dataset by applying a randomized set of transformations to each batch of images during training.
- 50x Faster Fine-Tuning via Automatic Mixed Precision (AMP) Training, Cached Encoder Embeddings, Approximate Training Set evaluation, and automatic batch sizing by default to maximize throughput.
- New Distributed Training Strategies: Distributed Data Parallel (DDP) and Fully Sharded Data Parallel (FSDP)
- Ray 2.0, 2.1, 2.2 and 2.3 support
- A new Ludwig profiler for benchmarking various CPU/GPU performance metrics, as well as comparing different Ludwig model runs.
- Revamped Ludwig datasets API with an even larger number of datasets out of the box.
- API annotations within Ludwig for contributors and Python users
- Schemification of the entire Ludwig Config object for better validation and checks upfront.
What's Changed
- Fix ray nightly import by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2196
- Restructured split config and added datetime splitting by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2132
- enh: Implements
InferenceModuleas a pipelined module with separate preprocessor, predictor, and postprocessor modules by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2105 - Explicitly pass data credentials when reading binary files from a RayBackend by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2198
- MlflowCallback: do not end run on_trainer_train_teardown by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2201
- Fail hyperopt with full import error when Ray not installed by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2203
- Make convert_predictions() backend-aware by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2200
- feat: MVP for explanations using Integrated Gradients from captum by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2205
- [Torchscript] Adds GPU-enabled input types for Vector and Timeseries by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2197
- feat: Added model type GBM (LightGBM tree learner), as an alternative to ECD by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2027
- [Torchscript] Parallelized Text/Sequence Preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2206
- feat: Adding feature type shared parameter capability for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2133
- Bump up version to 0.6.dev. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2209
- Define
FloatOrAutoandIntegerOrAutoschema fields, and use them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2219 - Define a dataclass for parameter metadata. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2218
- Add explicit handling for zero-length image byte buffers to avoid cryptic errors by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2210
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2231
- Create dataset util to form repeatable train/vali/test split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2159
- Bug fix: Use safe rename which works across filesystems when writing checkpoints by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2225
- Add parameter metadata to the trainer schema. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2224
- Add an explicit call to merge_wtih_defaults() when loading a config from a model directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2226
- Fixes flaky test test_datetime_split[dask] by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2232
- Fixes prediction saving for models with Set output by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2211
- Make ExpectedImpact JSON serializable by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2233
- standardised quotation marks, added missing word by @Marvjowa in https://github.com/ludwig-ai/ludwig/pull/2236
- Add boolean postprocessing to dataset type inference for automl by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2193
- Update get_repeatable_train_val_test_split to handle non-stratified split w/ no existing split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2237
- Update R2 score to handle single sample computation by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2235
- Input/Output Feature Schema Refactor by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2147
- Fix nan in entmax loss and flaky sparsemax/entmax loss tests by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2238
- Fix preprocessing dataset split API backwards compatibility upgrade bug. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2239
- Removing duplicates in constants from recent PRs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2240
- Add attention scores of the vit encoder as an additional return value by @Dennis-Rall in https://github.com/ludwig-ai/ludwig/pull/2192
- Unnest Audio Feature Preprocessing Config by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2242
- Fixed handling of invalud number values to treat as missing values by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2247
- Support saving numpy predictions to remote FS by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2245
- Use global constant for description.json by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2246
- Removed import warnings when LightGBM and Ray not requested by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2249
- Adds ability to read images from numpy files and numpy arrays by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2212
- Hyperopt steps per epoch not being computed correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2175
- Fixed splitting when providing pre-split inputs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2248
- Added Backwards Compatibility for Audio Feature Preprocessing by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2254
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2256
- Fix: Don't skip saving the model if the save path already exists. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2264
- Load best weights outside of finally block, since load may throw an exception by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2268
- Reduce number of distributed tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2270
- [WIP] Adds
inference_utils.pyby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2213 - Run github checks for pushes and merges to *-stable. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2266
- Add ludwig logo and version to CLI help text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2258
- Add hyperopt_statistics.json constant by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2276
- fix: Make
BaseTrainerConfigan abstract class by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2273 - [Torchscript] Adds
--deviceargument toexport_torchscriptCLI command by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2275 - Use pytest tmpdir fixture wherever temporary directories are used in tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2274
- adding configs used in benchmarking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2263
- Fixes #2279 by @noahlh in https://github.com/ludwig-ai/ludwig/pull/2284
- adding hardware usage and software packages tracker by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2195
- benchmarking utils by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2260
- dataclasses for summarizing benchmarking results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2261
- Benchmarking core by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2262
- Fixed default eval_batch_size when setting batch_size=auto by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2286
- Remove obsolete postprocess_inference_graph function. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2267
- [Torchscript] Adds BERT tokenizer + partial HF tokenizer support by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2272
- Support passing ground_truth as df for visualizations by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2281
- catching urllib3 exception by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2294
- Run pytest workflow on release branches. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2291
- Save checkpoint if train_steps is smaller than batcher's steps_per_epoch by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2298
- Fix typo in amazon review datasets: s/review_tile/review_title by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2300
- Refactor non-distributed automl utils into a separate directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2296
- Don't skip normalization in TabNet during inference on a single row. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2299
- Fix error in postproc_predictions calculation in model.evaluate() by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2304
- Test for parameter updates in Ludwig components by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2194
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2311
- Use warnings to suppress repeated logs for failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2312
- Use ray dataset and drop type casting in binary_feature prediction post processing for speedup by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2293
- Add size_bytes to DatasetInfo and DataSource by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2306
- Fixes TensorDtype TypeError in Ray nightly by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2320
- Add configuration section for global feature parameters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2208
- Ensures unit tests are deleting artifacts during teardown by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2310
- Fixes unit test that had empty Dask partitions after splitting by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2313
- Serve json numpy encoding by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2316
- fix: Mlflow config being injected in hyperopt config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2321
- Update tests that use preprocessing to match new defaults config structure by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2323
- Bump test timeout to 60 minutes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2325
- Set a default value for size_bytes in DatasetInfo by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2331
- Pin nightly versions to fix CI by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2327
- Log number of failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2317
- Add test with encoder dependencies for global defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2342
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2334
- Add wine quality notebook to demonstrate using config defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2333
- fix: GBM tests failing after new release from upstream dependency by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2347
- fix: restore overwrite of eval_batch_size on GBM schema by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2345
- Removes empty partitions after dropping rows and splitting datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2328
- fix: Properly serialize
ParameterMetadatato JSON by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2348 - Test for parameter updates in Ludwig Components - Part 2 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2252
- refactor: Replace bespoke marshmallow fields that accept multiple types with a new 'combinatorial'
OneOfFieldthat accepts other fields as arguments. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2285 - Use Ray Datasets to read binary files in parallel by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2241
- typos: Update README.md by @andife in https://github.com/ludwig-ai/ludwig/pull/2358
- Respect the resource requests in RayPredictor by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2359
- Resource tracker threading by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2352
- Allow writing init_config results to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2364
- Fixed export_mlflow command to not assume an existing registered_model_name by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2369
- fix: Fixes to serialization, and update to allow set repo location. by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2367
- Add amazon employee access challenge kaggle dataset by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2349
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2362
- Wrap read of cached training set metadata in try/except for robustness by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2373
- Reduce dropout prob in test_conv1d_stack by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2380
- fever: change broken download links by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2381
- Add default split config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2379
- Fix CI: Skip failing ray GBM tests by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2391
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2389
- Triton ensemble export by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2251
- Fix: Random dataset splitting with 0.0 probability for optional validation or test sets. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2382
- Print final training report as tabulated text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2383
- Add Ray 2.0 to CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2337
- add GBM configs to benchmarking by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2395
- Optional artifact logging for MLFlow by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2255
- Simplify ludwig.benchmarking.benchmark API and add ludwig benchmark CLI by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2394
- rename kaggle_api_key to kaggle_key by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2384
- use new URL for yosemite dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2385
- Encoder refactor V2 by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2370
- re-enable GBM tests after new lightgbm-ray release by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2393
- Added option to log artifact location while creating mlflow experiment by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2397
- Treat dataset columns as object dtype during first pass of handle_missing_values by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2398
- fix: ParameterMetadata JSON serialization bug by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2399
- Adds registry to organize backward compatibility updates around versions and config sections by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2335
- Include split column in explanation df by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2405
- Fix AimCallback to model_name as Run.name by @alberttorosyan in https://github.com/ludwig-ai/ludwig/pull/2413
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2410
- Hotfix: features eligible for shared params hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2417
- Nest FC Params in Decoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2400
- Hyperopt Backwards Compatibility by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2419
- Investigating test_resnet_block_layer intermittent test failure by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2414
- fix: Remove duplicate option from
cell_typefield schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2428 - Test for parameter updates in Ludwig Combiners - Part 3 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2332
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2430
- Hotfix: Proc column missing in output feature schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2435
- Nest hyperopt parameters into decoder object by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2436
- Fix: Make the twitter bots modeling example runnable by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2433
- Add MLG-ULB creditcard fraud dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2425
- Bugfix: non-number inputs to GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2418
- GBM: log intermediate progress by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2421
- Fix: Upgrade ludwig config before schema validation by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2441
- Log warning for calibration if validation set is trivially small by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2440
- Fixes calibration and adds example scripts by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2431
- Add medical no-show appointments dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2387
- Added conditional check for UNK token insertion into category feature vocab by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2429
- Ensure synthetic dataset unit tests to clean up extra files. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2442
- Added feature specific parameter test for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2329
- Fixed version transformation to accept user configs without ludwig_version by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2424
- Fix mulitple partition predict by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2422
- Cache jsonschema validator to reduce memory pressure by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2444
- [tests] Added more explicit lifecycle management to Ray clusters during tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2447
- Fix: explicit keyword args for seaborn plot fn by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2454
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2453
- Extended hyperopt to support nested configuration block parameters by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2445
- Consolidate missing value strategy to only include bfill and ffill by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2457
- fix: Switched Learning Rate to NonNegativeFloat Field by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2446
- Support GitHub Codespaces by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2463
- Enh: quality-of-life improvements for
export_torchscriptby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2459 - Disables
batch_size: autofor CPU-only training by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2455 - buxfix: triton model version as a string by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2461
- Updating images to Ray 2.0.0 and CUDA 11.3 by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2390
- Loss, Split, and Defaults Schema Additions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2439
- More precise resource usage tracking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2363
- Summarizing performance metrics and resource usage results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2372
- Better gbm defaults based on benchmarking results by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2466
- Infer single distinct value columns as category instead of binary by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2467
- fix: Add explicit schema in to_parquet() during saving predictions by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2420
- Publish docker images from release branches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2470
- Add backwards-compatibility logic for model progress tracker by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2468
- Backwards compatibility for class_weights by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2469
- Test for parameter updates in Ludwig Decoders - Part 4 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2354
- Fixed backwards compatibility for training_set_metadata and bfill by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2472
- Fixed backwards compatibility for models with level metadata in saved configs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2475
- Fix profiler: account for missing values when running in docker by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2477
- Add L-BFGS optimizer by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2478
- fix: Automatically assign title to OneOfOptionsField by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2480
- fix: handle 'numerical' entries in preprocessing config during backwards compatibility upgrade by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2484
- fix: mark update_class_weights_in_features transformation for version 0.6 by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2481
- Fixed usage of checkpoints for AutoML in Ray 2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2485
- [fix flaky test] Relax loss constraint for unit tests for lbfgs optimizer. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2486
- Fixed stratified splitting with Dask by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1883
- Replace custom Union marshmallow fields with Oneof fields, and default allow_none=True everywhere. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2482
- Resource isolation for dataset preprocessing on ray backends by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2404
- Pin transformers < 4.22 until issues resolved by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2495
- Fix flaky ray nightly image test by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2493
- Added workflow to auto cherry-pick into release branches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2500
- Enable hyperopt to be launched from a ray client by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2501
- GBM: support hyperopt by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2490
- Fixes saved_weights_in_checkpoint docstring, mark as internal only by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2506
- Fix test length of predictions by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2507
- Fixed support for distributed datasets in create_auto_config by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2508
- Config-first Datasets API (ludwig.datasets refactor) by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2479
- Add in-memory dataset size calculation to dataset statistics by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2509
- Surfacing dataset statistics in hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2515
- Adds multimodal benchmark datasets from AutoGluon paper by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2512
- Adds goodbooks dataset by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2514
- GBM: correctly compute early stopping by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2517
- Fixes mnist dataset image files not exporting by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2520
- Fix get_best_model in hyperopt for Ray 1.12 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2527
- Populate Parameter Metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2503
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2532
- Update README to be consistent with ludwig.ai home page. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2530
- Add missing declarative ML image in README by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2533
- fix: Add missing titles/descriptions to various schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2516
- Cleanup: move to per-module loggers instead of the global logging object. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2531
- Updated schedule logic for placement groups for ray backend by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2523
- Nit: Parameter update tests grammar. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2537
- Hyperopt: Log warning with num_extra_trials if all grid search parameters and num_samples > 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2535
- Adds model configs to ludwig.datasets by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2540
- ZScore Normalization Failure When Using Constant Value Number Feature by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2543
- Adds class names to calibration plot title, reformats Brier scores as grouped bar chart by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2545
- Pin ray nightly version to avoid new test failures by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2548
- Added tests for init_config and render_config CLI commands by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2551
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2554
- Ensure bfill/ffill leave no residual NaNs in the dataset during preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2553
- Comprehensive configs: Explicitly list and save all parameter values for input and output features in configs. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2460
- Fixing SettingWithCopyWarning when using
get_repeatable_train_val_test_splitby @abidwael in https://github.com/ludwig-ai/ludwig/pull/2562 - Replace numerical with number in dataset zoo configs. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2558
- Benchmarking toolkit wrap up by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2462
- Migrate to Raincloud plots for hyperopt report by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2561
- Remove global torchtext version-specific tokenizer availability warnings. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2547
- Only create hyperopt pair plots when there is more than 1 parameter by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2560
- fix: Limit frequency array to top_n_classes in F1 viz by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2565
- int: unpin Dask version by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2550
- Fixed typehint and removed unused utility function by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2570
- AutoML: stratify imbalanced datasets by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2525
- Use Ray Air Checkpoint to sync files between trial workers by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2577
- GBM bugfix: matching predictions LightGBM, hummingbird by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2574
- specify seed in RayDataset shuffling by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2566
- update logging message when
early_stop: -1by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2585 - update docker with torch wheel by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2584
- Refactors test_ray.py to minimize duplicate training jobs by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2573
- Explanation API and feature importance for GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2564
- Remove duplicate option by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2593
- Quick fix: Don't show calibration validation set warnings unless calibration is actually enabled by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2595
- Fixed issue when uploading output directory artifacts to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2598
- Add API Annotations to Ludwig by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2596
- Tweaks to the README (forward-ported from release-0.6) by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2603
- Extend test coverage for non-conventional booleans by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2601
- Fix assertions in training_determinism tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2606
- Ensure no ghost ray instances are running in tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2607
- Allow explicitly plumbing through nics by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2605
- bug: fix relative import in optimizers.py by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2600
- GBM: increase boosting_rounds_per_checkpoint to reduce evaluation overhead by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2612
- regression tests: add GBM model trained on v0.6.1 by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2611
- Relax test constraint to reduce flakiness in test_ray by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2610
- Add splitter that deterministically splits on an ID column by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2615
- fix(explain): missing columns for fixed split by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2616
- Fixed hyperopt trial syncing to remote filesystems for Ray 2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2617
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2622
- feat: adds
max_batch_sizeto auto batch size functionality by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2579 - Set commonly used parameters by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2619
- Factor out defaults mixin change by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2628
- Add type to custom combiner by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2627
- Remove hyperopt from config when running train through cli by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2631
- Ensure resource availability for ray datasets workloads when running on cpu clusters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2524
- Speed up horovod hyperopt tests and solve OOMs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2599
- [explain] add API annotations by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2635
- Added storage backend API to allow injecting dynamic credentials by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2630
- Update version to 0.7.dev by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2625
- Unpin Ray nightly in CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2614
- Skip Horovod 0.26 installation, add packaging to requirements.txt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2642
- [Annotations] Callbacks by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2641
- Fix automl by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2639
- accepting dictionary as input to
benchmarking.benchmarkby @abidwael in https://github.com/ludwig-ai/ludwig/pull/2626 - Fixed automl APIs to work with remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2650
- Adds minimum split size, ensures random split is never smaller than minimum for local backend by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2623
- Categorical passthrough encoder training failure fix by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2649
- Changes learning_curves to use "step" or "epoch" as x-axis label. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2578
- Remove Trainer
typeParam by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2647 - Model performace in GitHub actions by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2568
- Fixed race condition in schema validation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2653
- Fixed --gpu_memory_limit in CLI to interpret as fraction of GPU memory by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2658
- Stopgap solution for test_training_determinism by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2665
- Added min and max to sample ratio by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2655
- Set internal only flags by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2659
- Add support for running pytest github action locally with act by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2661
- Enforcing a 1 to 1 matching in names between Ludwig datasets and AutoGluon paper by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2666
- Added default arg to get_schema by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2667
- remove duplicate
news_popularitydataset by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2668 - Switch defaults to use mixins and improve test by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2669
- Documents running local tests with act by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2672
- Config Object by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2426
- Unpin protobuf by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2673
- Check vocab size of category features, error out if only one category. Also adds error.py for custom error types. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2670
- Ordered Schema by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2671
- Fix Regression Test Configs by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2678
- Testing always() inside expansion in condition by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2681
- Add protos to the Ludwig project: DatasetProfile messages and Whylogs messages. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2674
- Allow Ray Tune callbacks to be passed into hyperopt and log model config by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2640
- Check for nans before testing equality in test_training_determinism by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2687
- Set saved_weights_in_checkpoint on encoder, not input feature by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2690
- Use fully rendered config dictionary when accessing model.config by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2685
- bug: Set
additionalPropertiestoTruefor preprocessing schemas. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2620 - Bump support for torch 1.11.0 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2691
- Fix validator for reduce_learning_rate_on_plateau by @carlogrisetti in https://github.com/ludwig-ai/ludwig/pull/2692
- Use TensorArray to speed up writing predictions with Ray by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2684
- Dataset size checks in preprocess_for_training by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2688
- Remove Duplicate Schema Fields by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2679
- Speed up tune_batch_size by using synthetic batches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2680
- Add
bucketing_fieldParam to Trainer by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2694 - Fix InputDataError to be serializeable by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2695
- Adds PublicAPI annotation to api.py by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2698
- Cleanup: move to per-module loggers instead of the global logging object. (2) by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2699
- Adds Ray implementation of IntegratedGradientsExplainer that distributes across cluster resources by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2697
- Fixed bug with non-category outputs in RayIntegratedGradientsExplainer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2702
- Fix example values for max_batch_size in trainer parameter metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2705
- Fix incorrect internal_only flags on audio feature metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2704
- add customer churn datasets by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2703
- Add Kaggle test splits by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2675
- Fix ComparatorCombiner by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2689
- Actually print the torchinfo summary in print_model_summary() by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2696
- Add H&M fashion recommendation dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2708
- Fix GBM ray nightly test by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2676
- Adds DeveloperAPI and PublicAPI annotations to AutoML by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2701
- Remove obsolete v0 whylogs callback. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2713
- fill_value / computed_fill_value fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2714
- Add path to RayDataset by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2716
- Fixed Horovod to be an optional import when doing Hyperopt by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2717
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2722
- Adds annotation to download_one method in benchmarks by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2712
- fix: Prevent shared parameter_metadata instances between
defaultsand_features. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2715 - Added ngram tokenizer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2723
- Revert "Add H&M fashion recommendation dataset (#2708)" by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2724
- Optimize search space for hyperopt tests to decrease test durations by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2730
- Add custom to_dask() to infer Dask metadata from Datasets schema. by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2728
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2735
- Bump Ludwig to Ray 2.0 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2729
- Parameter Metadata Updates by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2736
- Removes some vestigial code and replaces Tensorflow with PyTorch in comments by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2731
- @DeveloperAPI annotations for backend module by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2707
- int: Refactor
test_ray.pyto limit number of full train jobs by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2637 - BaseTrainer: add empty barrier() by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2734
- Use whylogs to generate dataset profiles for pandas and dask dataframes. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2710
- Add IntegerOptions marshmallow field by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2739
- Downgrade to Ray 2.0 in CI to get green Ludwig CIs again. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2742
- Adds @DeveloperAPI annotations to combiner classes by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2744
- Use clearer error messages in ludwig serving, and enable serving to work with configs that have stratified splitting on target columns. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2740
- Update Ray GPU Docker image to CUDA 11.6 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2747
- Fix https://github.com/ludwig-ai/ludwig/issues/1735 by @herrmann in https://github.com/ludwig-ai/ludwig/pull/2746
- Enable dataset window autosizing by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2721
- Downgrade to PyTorch 1.12.1 in Docker to due to NCCL + CUDA compatibility by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2750
- Replicate ludwig type inference, using the whylogs dataset profile. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2743
- fix:
Encountered unknown symbol 'foo'warning in Category feature preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2662 - Expand ~ in dataset download paths by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2754
- Updates twitter bots example to new datasets API by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2753
- fix: refactor
IntegerOptionsfield by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2755 - Added ray datasets repartitioning in cases of multiple train workers by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2756
- fix: Fix metadata object-to-JSON serialization for oneOf fields and add full schema serialization test. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2758
- refactor: Add
ProtectedStringfield (alias ofStringOptionsthat only allows one string) by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2757 - [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2761
- Updates ludwig docker readme by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2760
- Annotates ludwig.datasets API by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2751
- Annotate MLFlow callback, and utility functions by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2749
- Drishi sarcasmdataset 1 by @drishi in https://github.com/ludwig-ai/ludwig/pull/2725
- Add local_rank to BaseTrainer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2766
- Public datasets by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2752
- Fix typo by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2767
- Correctly infer bool and object types in autoML by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2765
- feat: Hyperopt schema v0, part 1: Move output feature metrics from feature classes to feature configs. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2759
- Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2769
- Add ray version to runners by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2771
- Annotate Ludwig encoders and decoders by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2773
- Move preprocess callbacks inside model.preprocess by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2772
- Fix benchmark tests, update latest metrics, and use the local backend for GBM benchmark tests by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2748
- Ensure correct output reduction for text encoders like MT5 and add warning messages when not supported by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2774
- CVE-2007-4559 Patch by @TrellixVulnTeam in https://github.com/ludwig-ai/ludwig/pull/2770
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2776
- Fix double counting of training loss by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2775
- feat: Hyperopt schema v0, part 2: Make
BaseMarshmallowConfigabstract by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2779 - feat: Hyperopt schema v0, part 3: Enable optional min/max support for
FloatTupleMarshmallowFieldfields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2780 - feat: Hyperopt schema v0, part 4: Add and use new hyperopt registry, search algorithm instantiation by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2781
- Added exponential retry for mlflow, remote dataset loading by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2738
- Add synthetic test data integration test utils, and use them for loss value decrease tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2789
- feat: Hyperopt schema v0, part 5: Add basic search algorithm, scheduler, executor, and hyperopt schemas. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2784
- Add benchmark as a pytest marker to avoid warnings. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2786
- feat: Hyperopt schema v0, part 6: Enable new hyperopt schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2785
- Add sentencepiece as a requirement, which is necessary for some hf models like mt5. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2782
- [Annotations] Ludwig data modules by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2793
- [Annotations] Add DeveloperAPI annotations to Ludwig utils - Part 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2794
- [Annotations] Annotations for Ludwig's utils - Part 2 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2797
- [Annotations] Add annotations for schema module (part 1) - Model Config, Split, Trainer, Optimizers, Utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2798
- [Annotations] Annotate Schema Part 2: decoders, encoders, defaults, combiners, loss and preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2799
- Add new data utility functions for buffers and files, and rename registry by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2796
- [Annotations] Ludwig Schema - Part 3: Features, Hyperopt and Metadata by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2800
- [Annotations] Add annotations for Ludwig's data utils (file readers) by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2795
- Proceed with model training even if saving preprocessed data fails. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2783
- Improve warnings about backwards compatibility and dataset splitting. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2788
- Generate structural change warnings and log_once functionality by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2801
- Broadcast progress tracker dict to all workers by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2804
- Start fresh training run if files for resuming training are missing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2787
- LIghtGBMRayTrainer repartition datasets with fewer blocks than Ray actors by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2806
- Add InterQuartileTransformer normalization strategy for Number Features by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2805
- Add negative sampling to ludwig.data by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2711
- Rectify output features in dataset config by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2768
- int: Add JSON markup to support unique input feature names. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2792
- int: Replace
StringOptionsusage withProtectedStringin split schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2808 - int: Replace
StringOptionswithProtectedStringfor combiner schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2809 - refactor: Replace
StringOptionswithProtectedStringfor encoder/decoder schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2810 - Upload Datasets to Remote Location by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2764
- [Annotations] Annotate AutoML utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2812
- [Annotations] Ludwig Visualizations by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2813
- [Annotations] Logging Level Registry by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2814
- refactor: Replace
StringOptionswithProtectedStringfor loss/hyperopt schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2816 - Define custom Ludwig types and replace Dict[str, Any] type hints with them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2556
- Config Object Bug Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2817
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2803
- AutoML libraries that use DatasetProfile instead of DatasetInfo by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2802
- Remove Sentencepiece by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2821
- fix: account for
max_batch_sizeconfig param in batch size tuning on cpu by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2693 - [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2823
- refactor: Add filtering based on
model_typefor feature, combiner, and model type schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2815 - [TorchScript] Add user-defined HF Bert tokenizers by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2733
- [Annotations] Move feature registries into accessor functions by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2818
- [Annotations] Encoder and Decoder Registries by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2819
- Speed Up Ray Image Tests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2828
- fix: Restrict allowed top-level config keys by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2826
- Moves image decoding out of Ray Datasets to Dask Dataframe by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2737
- Improve type hints and remove dead code for DatasetLoader module by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2833
- Update stratified split with a more specific exception for underpopulated classes by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2831
- Add Ludwig contributors to README by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2835
- Fix key error in AutoML model select by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2824
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2836
- Drop incomplete batches for Ray and Pandas to prevent Batchnorm computation errors by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2778
- Catch and surface Runtime exceptions during preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2839
- fix: Mark
widthandheightasinternal_onlyfor image encoders by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2842 - Select best batch size to maximize training throughput by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2843
- Make batch_size=auto more consistent by using median of 5 steps by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2846
- Make trainable=False default for all pretrained models by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2844
- fix: Add back missing split fields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2848
- Pin scikit-learn<1.2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2850
- text_encoder: RoBERTa max_sequence_length by @rudolfolah in https://github.com/ludwig-ai/ludwig/pull/2852
- Fix TorchText version in tokenizers ahead of torch 1.13.0 upgrade by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2838
- Fix
trainable=Falseto freeze all params for HF encoders by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2855 - Add support for automatic mixed precision (AMP) training by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2857
- Evaluate training set in the training loop by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2856
- Extend parameter guidance documentation for regularization, and add explicit maxes to Non-Negative floats by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2849
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2860
- Fixes for the roberta encoder: explicitly set max sequence length, and fix output shape computation by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2861
- Enables Set output feature on Ray by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2791
- Add go module for dataset profile protos. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2834
- fix: Upgrade
expected_impactfortrainabletoMEDIUMon all encoders. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2865 - support stratified split with low cardinality features by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2863
- fix: load spacy model for lemmatization in
EnglishLemmatizeFilterTokenizerto work by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2868 - Token-level explanations by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2864
- Replace
learning rate: autowith feature type and encoder-based heuristics by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2854 - Set RayBackend Config to use single worker for tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2853
- Remove
_to_tensors_fnfrom Ray Datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2866 - Remove ludwig-dev Dockerfile by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2873
- Support Ray GPU image with Torch 1.13 and CUDA 11.6 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2869
- Use native LightGBM for intermittent eval during training by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2829
- Set default validation metrics based on the output feature type. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2820
- Auto resize images for ViTEncoder when use_pretrained is True or False by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2862
- TLE Backwards Compatibility Fixes by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2875
- Do not drop batch size dimension for single inputs by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2878
- Save GBM after training if not previously saved by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2880
- Fix TLE - Pt. 2 by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2881
- Tle fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2883
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2885
- Convert schema metadata to YAML by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2884
- Automatically infer vector_size for vector features when not provided by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2888
- Support MLFlowCallback logging to an existing run by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2892
- Fix dataset synthesizer by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2894
- Add a clear error message about invalid column names in GBM datasets by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2879
- Explicitly track all metrics related to the best evaluation in the progress tracker. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2827
- Added DistributedStrategy interface with support for DDP by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2890
- Adopt PyTorch official LRScheduler API by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2877
- Annotate Confusion Matrix with updated cmap by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2899
- Dynamically resize confusion matrix and f1 plots by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2900
- Update backward compatibility tests for LR progress tracker changes made in #2877. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2904
- fix: Fix vague initializer JSON schema titles. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2909
- Support Distributed Training And Ray Tune with Ray 2.1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2709
- Expand vision models to support pre-trained models by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2408
- Add ECD Descriptions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2897
- Simplify titanic example to read config in-line, and skip saving processed input. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2912
- Adds quick fix for pretrained models not loading by modifying state_dict keys on load. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2911
- fix: Schema split conditions should pass in [TYPE] and not string by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2917
- Refactor metrics and metric tables and support adding more in-training metrics. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2901
- Updated AutoML configs for latest schema and added validation tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2921
- Adds backwards compatibility for legacy image encoders by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2916
- Pin Torch to
>=1.13.0by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2914 - Hyperopt invalid GBM config by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2926
- Store mlflow tracking URI to ensure consistency across processes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2927
- Update automl heuristics for fine-tuning and multi-modal tasks by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2922
- Bump torch version for benchmark tests by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2929
- Fix signing key by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2928
- Adds safe_move_directory to fs_utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2931
- Added separate AutoML APIs for feature inference and config generation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2932
- Dynamic resizing for Confusion Matrix, Brier, F1 Plot, etc. by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2936
- Raise RuntimeError only for category output features with vocab size 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2923
- Bump min python to 3.8 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2930
- Evaluate training set in the training loop (GBM) by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2907
- [automl] Exclude text fields with low avg words by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2941
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2944
- Fix pre-commit by removing manually specified blacken-docs dep. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2949
- Rotate Brier Plot X-axis labels to 45 degree angle by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2948
- Retry HuggingFace pretrained model download on failure by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2951
- Disable AUROC for CATEGORY features. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2950
- Deactivate GBM random forest boosting type by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2954
- Make batch_size=auto the default by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2845
- Twitter bots test small improvements by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2955
- Disable bagging when using GOSS GBM boosting type by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2956
- Add missing standardize_image key to metadata by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2946
- Integrated Gradients: reset sample_ratio to 1.0 if set by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2945
- Increase CI pytest time out to 75 minutes by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2958
- Add
sacremosesas a dependency for transformer_xl encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2961 - Move all config validation to its own standalone module,
config_validation. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2959 - Fixes longformer encoder by passing in pretrained_kwargs correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2963
- Expected Impact Calibration by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2960
- Update Camembert by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2966
- fix: Fix
epochssuggested range by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2965 - fix: enable binary dense encoder by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2957
- GBM DART boosting type incopatible with early stopping by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2964
- Improving metadata config descriptions by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/2933
- Fix ludwig-gpu image by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2974
- Skip test_ray_outputs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2935
- Enable custom HF BERT models with default tokenizer config by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2973
- Update CamemBERT in schema by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2975
- Set reduce_output to sum for XLM encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2972
- Skipped mercedes_benz_greener.ecd.yaml benchmark test by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2980
- Add sentencepiece as a requirement for MT5 text encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2967
- Disable CTRL Encoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2976
- MT5 reduce_output can't be cls_pooled - set to sum by default by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2981
- Populate hyperopt defaults using schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2968
- Revert "Add sentencepiece as a requirement for MT5 text encoder (#2967)" and disable MT5 Encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2982
- Change default reduce_output strategy to sum for CamemBERT by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2984
- Set
max_failuresfor Tuner to 0 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2987 - Fix TLE OOM for BERT-like models by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2990
- Reorder Advanced Parameters by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2979
- [Hyperopt] Modify _get_best_model_path to grab it from the Checkpoint object with ExperimentAnalysis by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2985
- GBM: disable goss boosting type by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2986
- Adds HuggingFace pretrained encoder unit tests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2962
- [Hyperopt] Set default num_samples based on parameter space by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2997
- LR Scheduler Adjustments by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2996
- fix: Force populate combiner registry inside of
get_schemafunction. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2970 - fix: Fix validation and serialization for
BooleanandOneOfOptionsFieldfields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2992 - Ray 2.2 compatibility by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2910
- Compute fixed text embeddings (e.g., BERT) during preprocessing by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2867
- Use iloc to fetch first audio value. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3006
- Fix Internal Only Param by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3008
- Ludwig Dataclass by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3005
- Cap batch_size=auto at 128 for CPU training by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3007
- Added ghost batch norm option for concat combiner by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3001
- Refactored norm layer and added additional norm at the start of the FCStack by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3011
- Fix assignment that undoes tensor move to CPU by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3012
- [Explain] Detach inputs before numpy processing by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3014
- Handle CUDA OOMs in explanations with retry and batch size halving by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3015
- fix: Remove
ecd_ray_legacymodel type alias. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/3013 - Explain fixes by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3016
- Remove
nullGBM trainer config options by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2989 - Disable reuse_actors in hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3017
- Skip Sarcos dataset during benchmark tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3020
- Explain: improve docstring about IntegratedGradient baseline for number features by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3018
- Upgrade isort to fix pre-commit. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3027
- Limit batch size tuning to ≤20% of dataset size by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3003
- [schema] Mark skip internal only by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3022
- Add specificity metric for binary features by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3025
- Added FSDP distributed strategy by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3026
- Move
on_batch_endcallback to omit eval from batch duration during benchmarking by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2898 - Set 0.7.beta by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3028
- Added missing file for fsdp by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3033
- Cleaning up seed / random_seed usage discrepancy by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/3021
- Filter Competitions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3032
- Hyperopt Quick Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3034
- Expected Impact and Ordering for GBM Params by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3038
- Transformer Encoder - Representation Parameter Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2999
- Enables a new GitHub Action for
slowtests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3029 - Skip BOHB test when using hyperopt with ray + horovod by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3036
- Fix gradient clipping typo by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3039
- Fix checkpoint loading for HuggingFace encoders by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3010
- Schema Polishing by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3041
- Address some warnings when running hyperopt tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3040
- Removed log spam from distributed loader by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3042
- [Hyperopt] Fix get_best_model_path by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3043
- Bump Ludwig images to Ray 2.2.0 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3023
- Revert "Bump Ludwig images to Ray 2.2.0 (#3023)" by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3044
- add httpx as required by starlette>=0.21.0 by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3047
- Raise exceptions from async batch producer thread on the main thread by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3050
- Set zscore normalization as the default normalization strategy for number features by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3051
- Fix TLE: safe divide by zero + normalize at sequence level by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3046
- Fix
fill_with_modewhen using Dask by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3054 - Refactored ModelConfig object into a Marshmallow schema by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2906
- Fix LR reduce on plateau interaction with base LR decay by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3056
- Update schema to correctly reflect supported missing value strategies for different feature types by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3053
- Improve observability when using cached datasets during preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3058
- Quick fix for cached logging by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3060
- Remove passthrough encoder from sequence and text features encoder registry by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3061
- Remove RNN invalid cell types from the schema by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3062
- Round confusion matrix numbers to 3 decimal places by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3065
- Fixed handling of {} hyperopt config section by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3064
- Deflake
test_tune_batch_size_lr_cpuby @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3067 - Feature: Data Augmentation for Image Input Features by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2925
- Update transformer
hidden_size / num_headserror message by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3066 - Add MPS device support by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3072
- Require env var LUDWIG_USE_MPS to enable MPS by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3074
- Generate proc_column only after all preprocessing parameters are merged in to prevent incorrect cached dataset reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3069
- Remove duplicate validation field validation. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3070
- Remove previous ModelConfig implementation and refactor to use
__post_init__by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3083 - Set RunConfig verbosity to 0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3085
- Fix default image on image read failure by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3073
- Add Precision Recall curves to Ludwig by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3084
- Log number of rows dropped by
DROP_ROWSstrategy by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3087 - Allow providing a Ludwig dataset as a URI of the form
ludwig://<dataset>by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3082 - Fixed augmentation schema check by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3090
- XLNet: disable "uni" attention type by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3097
- Only show drop row logging if rows are dropped by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3094
- Upgrade torchmetrics to 0.11.1. Add ROC metrics for category features. Add sequence accuracy, char error rate, and perplexity metrics for text features. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3035
- Disallow certain config parameters from accepting
nullas a value by @abidwael in https://github.com/ludwig-ai/ludwig/pull/3079 - Deflake the lbgfs optimizer test by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3100
- Use
window_size_bytes: autoto specify automatic windowing by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3076 - Use proc col hash for checksum computation by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3095
- Fixed ethos_binary dataset to threshold the label at 0.5 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3102
- Add -1 as a valid negative class for binary type inference by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3101
- GBM: remove distributed=False from RayDMatrix by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3099
- Switch combiner num_fc_layers to expected impact 3 by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3103
- Add a registry of additional config checks to check inter-parameter incompatibilities. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3024
- Adds config parameters to replace outliers via a missing_value_strategy by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3080
- Fixed serialization and deserialization of augmentation configuration by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/3096
- Unregister CTRL and MT5 encoders since they have tensor placement and sentencepiece segfault issues by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3106
- Pin torch nightly to Feb 13, 2023 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3110
- Resize confusion matrix properly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3109
- Fold all validation into ModelConfig. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3104
- fix: add pytest to hashfiles to be more selective about caching by @abidwael in https://github.com/ludwig-ai/ludwig/pull/3113
- Disable XLM Text Encoder because of host memory pressure issues by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3108
- Bump ludwig docker image ray220 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3111
- Remove XLM encoder from slow encoders test by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3114
- Added additional dropout to concat by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3116
- Update field descriptions for ludwig-docs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3123
- Transformer divisibility error validation by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3105
- fix: Updated Learning Rate decay_rate to use corresponding Metadata. by @martindavis in https://github.com/ludwig-ai/ludwig/pull/3128
- refactor: Use
TypeSelectionto power optimizer field by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/3071 - refactor: Add separate ECD and GBM defaults schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/3124
- Skip batch norm when chunk size is 1 in GhostBatchNorm by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3119
- Fix tests to be compliant with latest version of whylogs by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3131
- Make positive class weight a float. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3133
- feat: Raise deprecation warnings for unknown parameters by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/3118
- Align sequence encoder descriptions with ludwig-docs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3135
- [Explain] always return global and row-level explanations by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3132
- Update benchmark tests by @abidwael in https://github.com/ludwig-ai/ludwig/pull/3115
- [Hyperopt] Load checkpoints directly from the object store in Ray 2.2 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3037
- Decouple loss schema from implementation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3141
- Adds non-slow HF unit test to validate constant value by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3130
- Updated decoder and loss schemas, removed dep from schema -> loss_modules by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3140
- Init minimal config by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3143
- Updated HF long descriptions by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3144
- Disallow GPU tensors in GBM training and eval by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3139
- Not default to adding
Noneas accepted tuple forFloatRangeTupleDataclassFieldby @abidwael in https://github.com/ludwig-ai/ludwig/pull/3146 - Ray 2.3 Compatibility by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3009
- Unpin pyarrow by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3149
- Update Ludwig version to 0.7 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3148
New Contributors
- @Marvjowa made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2236
- @Dennis-Rall made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2192
- @abidwael made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2263
- @noahlh made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2284
- @jeffkinnison made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2316
- @andife made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2358
- @alberttorosyan made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2413
- @herrmann made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2746
- @drishi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2725
- @TrellixVulnTeam made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2770
- @rudolfolah made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2852
- @martindavis made their first contribution in https://github.com/ludwig-ai/ludwig/pull/3128
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6.4...v0.7
Published by justinxzhao over 1 year ago
What's Changed
- Fix ray nightly import by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2196
- Restructured split config and added datetime splitting by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2132
- enh: Implements
InferenceModuleas a pipelined module with separate preprocessor, predictor, and postprocessor modules by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2105 - Explicitly pass data credentials when reading binary files from a RayBackend by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2198
- MlflowCallback: do not end run on_trainer_train_teardown by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2201
- Fail hyperopt with full import error when Ray not installed by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2203
- Make convert_predictions() backend-aware by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2200
- feat: MVP for explanations using Integrated Gradients from captum by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2205
- [Torchscript] Adds GPU-enabled input types for Vector and Timeseries by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2197
- feat: Added model type GBM (LightGBM tree learner), as an alternative to ECD by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2027
- [Torchscript] Parallelized Text/Sequence Preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2206
- feat: Adding feature type shared parameter capability for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2133
- Bump up version to 0.6.dev. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2209
- Define
FloatOrAutoandIntegerOrAutoschema fields, and use them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2219 - Define a dataclass for parameter metadata. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2218
- Add explicit handling for zero-length image byte buffers to avoid cryptic errors by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2210
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2231
- Create dataset util to form repeatable train/vali/test split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2159
- Bug fix: Use safe rename which works across filesystems when writing checkpoints by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2225
- Add parameter metadata to the trainer schema. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2224
- Add an explicit call to merge_wtih_defaults() when loading a config from a model directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2226
- Fixes flaky test test_datetime_split[dask] by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2232
- Fixes prediction saving for models with Set output by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2211
- Make ExpectedImpact JSON serializable by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2233
- standardised quotation marks, added missing word by @Marvjowa in https://github.com/ludwig-ai/ludwig/pull/2236
- Add boolean postprocessing to dataset type inference for automl by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2193
- Update get_repeatable_train_val_test_split to handle non-stratified split w/ no existing split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2237
- Update R2 score to handle single sample computation by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2235
- Input/Output Feature Schema Refactor by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2147
- Fix nan in entmax loss and flaky sparsemax/entmax loss tests by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2238
- Fix preprocessing dataset split API backwards compatibility upgrade bug. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2239
- Removing duplicates in constants from recent PRs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2240
- Add attention scores of the vit encoder as an additional return value by @Dennis-Rall in https://github.com/ludwig-ai/ludwig/pull/2192
- Unnest Audio Feature Preprocessing Config by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2242
- Fixed handling of invalud number values to treat as missing values by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2247
- Support saving numpy predictions to remote FS by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2245
- Use global constant for description.json by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2246
- Removed import warnings when LightGBM and Ray not requested by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2249
- Adds ability to read images from numpy files and numpy arrays by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2212
- Hyperopt steps per epoch not being computed correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2175
- Fixed splitting when providing pre-split inputs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2248
- Added Backwards Compatibility for Audio Feature Preprocessing by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2254
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2256
- Fix: Don't skip saving the model if the save path already exists. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2264
- Load best weights outside of finally block, since load may throw an exception by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2268
- Reduce number of distributed tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2270
- [WIP] Adds
inference_utils.pyby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2213 - Run github checks for pushes and merges to *-stable. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2266
- Add ludwig logo and version to CLI help text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2258
- Add hyperopt_statistics.json constant by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2276
- fix: Make
BaseTrainerConfigan abstract class by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2273 - [Torchscript] Adds
--deviceargument toexport_torchscriptCLI command by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2275 - Use pytest tmpdir fixture wherever temporary directories are used in tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2274
- adding configs used in benchmarking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2263
- Fixes #2279 by @noahlh in https://github.com/ludwig-ai/ludwig/pull/2284
- adding hardware usage and software packages tracker by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2195
- benchmarking utils by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2260
- dataclasses for summarizing benchmarking results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2261
- Benchmarking core by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2262
- Fixed default eval_batch_size when setting batch_size=auto by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2286
- Remove obsolete postprocess_inference_graph function. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2267
- [Torchscript] Adds BERT tokenizer + partial HF tokenizer support by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2272
- Support passing ground_truth as df for visualizations by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2281
- catching urllib3 exception by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2294
- Run pytest workflow on release branches. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2291
- Save checkpoint if train_steps is smaller than batcher's steps_per_epoch by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2298
- Fix typo in amazon review datasets: s/review_tile/review_title by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2300
- Refactor non-distributed automl utils into a separate directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2296
- Don't skip normalization in TabNet during inference on a single row. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2299
- Fix error in postproc_predictions calculation in model.evaluate() by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2304
- Test for parameter updates in Ludwig components by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2194
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2311
- Use warnings to suppress repeated logs for failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2312
- Use ray dataset and drop type casting in binary_feature prediction post processing for speedup by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2293
- Add size_bytes to DatasetInfo and DataSource by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2306
- Fixes TensorDtype TypeError in Ray nightly by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2320
- Add configuration section for global feature parameters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2208
- Ensures unit tests are deleting artifacts during teardown by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2310
- Fixes unit test that had empty Dask partitions after splitting by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2313
- Serve json numpy encoding by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2316
- fix: Mlflow config being injected in hyperopt config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2321
- Update tests that use preprocessing to match new defaults config structure by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2323
- Bump test timeout to 60 minutes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2325
- Set a default value for size_bytes in DatasetInfo by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2331
- Pin nightly versions to fix CI by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2327
- Log number of failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2317
- Add test with encoder dependencies for global defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2342
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2334
- Add wine quality notebook to demonstrate using config defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2333
- fix: GBM tests failing after new release from upstream dependency by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2347
- fix: restore overwrite of eval_batch_size on GBM schema by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2345
- Removes empty partitions after dropping rows and splitting datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2328
- fix: Properly serialize
ParameterMetadatato JSON by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2348 - Test for parameter updates in Ludwig Components - Part 2 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2252
- refactor: Replace bespoke marshmallow fields that accept multiple types with a new 'combinatorial'
OneOfFieldthat accepts other fields as arguments. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2285 - Use Ray Datasets to read binary files in parallel by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2241
- typos: Update README.md by @andife in https://github.com/ludwig-ai/ludwig/pull/2358
- Respect the resource requests in RayPredictor by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2359
- Resource tracker threading by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2352
- Allow writing init_config results to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2364
- Fixed export_mlflow command to not assume an existing registered_model_name by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2369
- fix: Fixes to serialization, and update to allow set repo location. by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2367
- Add amazon employee access challenge kaggle dataset by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2349
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2362
- Wrap read of cached training set metadata in try/except for robustness by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2373
- Reduce dropout prob in test_conv1d_stack by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2380
- fever: change broken download links by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2381
- Add default split config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2379
- Fix CI: Skip failing ray GBM tests by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2391
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2389
- Triton ensemble export by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2251
- Fix: Random dataset splitting with 0.0 probability for optional validation or test sets. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2382
- Print final training report as tabulated text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2383
- Add Ray 2.0 to CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2337
- add GBM configs to benchmarking by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2395
- Optional artifact logging for MLFlow by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2255
- Simplify ludwig.benchmarking.benchmark API and add ludwig benchmark CLI by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2394
- rename kaggle_api_key to kaggle_key by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2384
- use new URL for yosemite dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2385
- Encoder refactor V2 by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2370
- re-enable GBM tests after new lightgbm-ray release by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2393
- Added option to log artifact location while creating mlflow experiment by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2397
- Treat dataset columns as object dtype during first pass of handle_missing_values by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2398
- fix: ParameterMetadata JSON serialization bug by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2399
- Adds registry to organize backward compatibility updates around versions and config sections by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2335
- Include split column in explanation df by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2405
- Fix AimCallback to model_name as Run.name by @alberttorosyan in https://github.com/ludwig-ai/ludwig/pull/2413
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2410
- Hotfix: features eligible for shared params hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2417
- Nest FC Params in Decoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2400
- Hyperopt Backwards Compatibility by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2419
- Investigating test_resnet_block_layer intermittent test failure by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2414
- fix: Remove duplicate option from
cell_typefield schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2428 - Test for parameter updates in Ludwig Combiners - Part 3 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2332
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2430
- Hotfix: Proc column missing in output feature schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2435
- Nest hyperopt parameters into decoder object by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2436
- Fix: Make the twitter bots modeling example runnable by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2433
- Add MLG-ULB creditcard fraud dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2425
- Bugfix: non-number inputs to GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2418
- GBM: log intermediate progress by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2421
- Fix: Upgrade ludwig config before schema validation by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2441
- Log warning for calibration if validation set is trivially small by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2440
- Fixes calibration and adds example scripts by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2431
- Add medical no-show appointments dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2387
- Added conditional check for UNK token insertion into category feature vocab by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2429
- Ensure synthetic dataset unit tests to clean up extra files. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2442
- Added feature specific parameter test for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2329
- Fixed version transformation to accept user configs without ludwig_version by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2424
- Fix mulitple partition predict by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2422
- Cache jsonschema validator to reduce memory pressure by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2444
- [tests] Added more explicit lifecycle management to Ray clusters during tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2447
- Fix: explicit keyword args for seaborn plot fn by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2454
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2453
- Extended hyperopt to support nested configuration block parameters by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2445
- Consolidate missing value strategy to only include bfill and ffill by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2457
- fix: Switched Learning Rate to NonNegativeFloat Field by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2446
- Support GitHub Codespaces by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2463
- Enh: quality-of-life improvements for
export_torchscriptby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2459 - Disables
batch_size: autofor CPU-only training by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2455 - buxfix: triton model version as a string by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2461
- Updating images to Ray 2.0.0 and CUDA 11.3 by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2390
- Loss, Split, and Defaults Schema Additions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2439
- More precise resource usage tracking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2363
- Summarizing performance metrics and resource usage results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2372
- Better gbm defaults based on benchmarking results by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2466
- Infer single distinct value columns as category instead of binary by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2467
- fix: Add explicit schema in to_parquet() during saving predictions by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2420
- Publish docker images from release branches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2470
- Add backwards-compatibility logic for model progress tracker by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2468
- Backwards compatibility for class_weights by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2469
- Test for parameter updates in Ludwig Decoders - Part 4 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2354
- Fixed backwards compatibility for training_set_metadata and bfill by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2472
- Fixed backwards compatibility for models with level metadata in saved configs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2475
- Fix profiler: account for missing values when running in docker by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2477
- Add L-BFGS optimizer by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2478
- fix: Automatically assign title to OneOfOptionsField by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2480
- fix: handle 'numerical' entries in preprocessing config during backwards compatibility upgrade by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2484
- fix: mark update_class_weights_in_features transformation for version 0.6 by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2481
- Fixed usage of checkpoints for AutoML in Ray 2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2485
- [fix flaky test] Relax loss constraint for unit tests for lbfgs optimizer. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2486
- Fixed stratified splitting with Dask by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1883
- Replace custom Union marshmallow fields with Oneof fields, and default allow_none=True everywhere. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2482
- Resource isolation for dataset preprocessing on ray backends by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2404
- Pin transformers < 4.22 until issues resolved by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2495
- Fix flaky ray nightly image test by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2493
- Added workflow to auto cherry-pick into release branches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2500
- Enable hyperopt to be launched from a ray client by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2501
- GBM: support hyperopt by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2490
- Fixes saved_weights_in_checkpoint docstring, mark as internal only by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2506
- Fix test length of predictions by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2507
- Fixed support for distributed datasets in create_auto_config by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2508
- Config-first Datasets API (ludwig.datasets refactor) by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2479
- Add in-memory dataset size calculation to dataset statistics by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2509
- Surfacing dataset statistics in hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2515
- Adds multimodal benchmark datasets from AutoGluon paper by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2512
- Adds goodbooks dataset by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2514
- GBM: correctly compute early stopping by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2517
- Fixes mnist dataset image files not exporting by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2520
- Fix get_best_model in hyperopt for Ray 1.12 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2527
- Populate Parameter Metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2503
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2532
- Update README to be consistent with ludwig.ai home page. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2530
- Add missing declarative ML image in README by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2533
- fix: Add missing titles/descriptions to various schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2516
- Cleanup: move to per-module loggers instead of the global logging object. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2531
- Updated schedule logic for placement groups for ray backend by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2523
- Nit: Parameter update tests grammar. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2537
- Hyperopt: Log warning with num_extra_trials if all grid search parameters and num_samples > 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2535
- Adds model configs to ludwig.datasets by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2540
- ZScore Normalization Failure When Using Constant Value Number Feature by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2543
- Adds class names to calibration plot title, reformats Brier scores as grouped bar chart by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2545
- Pin ray nightly version to avoid new test failures by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2548
- Added tests for init_config and render_config CLI commands by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2551
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2554
- Ensure bfill/ffill leave no residual NaNs in the dataset during preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2553
- Comprehensive configs: Explicitly list and save all parameter values for input and output features in configs. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2460
- Fixing SettingWithCopyWarning when using
get_repeatable_train_val_test_splitby @abidwael in https://github.com/ludwig-ai/ludwig/pull/2562 - Replace numerical with number in dataset zoo configs. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2558
- Benchmarking toolkit wrap up by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2462
- Migrate to Raincloud plots for hyperopt report by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2561
- Remove global torchtext version-specific tokenizer availability warnings. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2547
- Only create hyperopt pair plots when there is more than 1 parameter by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2560
- fix: Limit frequency array to top_n_classes in F1 viz by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2565
- int: unpin Dask version by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2550
- Fixed typehint and removed unused utility function by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2570
- AutoML: stratify imbalanced datasets by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2525
- Use Ray Air Checkpoint to sync files between trial workers by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2577
- GBM bugfix: matching predictions LightGBM, hummingbird by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2574
- specify seed in RayDataset shuffling by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2566
- update logging message when
early_stop: -1by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2585 - update docker with torch wheel by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2584
- Refactors test_ray.py to minimize duplicate training jobs by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2573
- Explanation API and feature importance for GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2564
- Remove duplicate option by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2593
- Quick fix: Don't show calibration validation set warnings unless calibration is actually enabled by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2595
- Fixed issue when uploading output directory artifacts to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2598
- Add API Annotations to Ludwig by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2596
- Tweaks to the README (forward-ported from release-0.6) by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2603
- Extend test coverage for non-conventional booleans by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2601
- Fix assertions in training_determinism tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2606
- Ensure no ghost ray instances are running in tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2607
- Allow explicitly plumbing through nics by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2605
- bug: fix relative import in optimizers.py by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2600
- GBM: increase boosting_rounds_per_checkpoint to reduce evaluation overhead by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2612
- regression tests: add GBM model trained on v0.6.1 by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2611
- Relax test constraint to reduce flakiness in test_ray by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2610
- Add splitter that deterministically splits on an ID column by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2615
- fix(explain): missing columns for fixed split by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2616
- Fixed hyperopt trial syncing to remote filesystems for Ray 2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2617
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2622
- feat: adds
max_batch_sizeto auto batch size functionality by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2579 - Set commonly used parameters by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2619
- Factor out defaults mixin change by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2628
- Add type to custom combiner by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2627
- Remove hyperopt from config when running train through cli by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2631
- Ensure resource availability for ray datasets workloads when running on cpu clusters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2524
- Speed up horovod hyperopt tests and solve OOMs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2599
- [explain] add API annotations by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2635
- Added storage backend API to allow injecting dynamic credentials by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2630
- Update version to 0.7.dev by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2625
- Unpin Ray nightly in CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2614
- Skip Horovod 0.26 installation, add packaging to requirements.txt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2642
- [Annotations] Callbacks by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2641
- Fix automl by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2639
- accepting dictionary as input to
benchmarking.benchmarkby @abidwael in https://github.com/ludwig-ai/ludwig/pull/2626 - Fixed automl APIs to work with remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2650
- Adds minimum split size, ensures random split is never smaller than minimum for local backend by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2623
- Categorical passthrough encoder training failure fix by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2649
- Changes learning_curves to use "step" or "epoch" as x-axis label. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2578
- Remove Trainer
typeParam by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2647 - Model performace in GitHub actions by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2568
- Fixed race condition in schema validation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2653
- Fixed --gpu_memory_limit in CLI to interpret as fraction of GPU memory by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2658
- Stopgap solution for test_training_determinism by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2665
- Added min and max to sample ratio by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2655
- Set internal only flags by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2659
- Add support for running pytest github action locally with act by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2661
- Enforcing a 1 to 1 matching in names between Ludwig datasets and AutoGluon paper by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2666
- Added default arg to get_schema by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2667
- remove duplicate
news_popularitydataset by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2668 - Switch defaults to use mixins and improve test by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2669
- Documents running local tests with act by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2672
- Config Object by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2426
- Unpin protobuf by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2673
- Check vocab size of category features, error out if only one category. Also adds error.py for custom error types. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2670
- Ordered Schema by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2671
- Fix Regression Test Configs by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2678
- Testing always() inside expansion in condition by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2681
- Add protos to the Ludwig project: DatasetProfile messages and Whylogs messages. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2674
- Allow Ray Tune callbacks to be passed into hyperopt and log model config by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2640
- Check for nans before testing equality in test_training_determinism by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2687
- Set saved_weights_in_checkpoint on encoder, not input feature by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2690
- Use fully rendered config dictionary when accessing model.config by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2685
- bug: Set
additionalPropertiestoTruefor preprocessing schemas. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2620 - Bump support for torch 1.11.0 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2691
- Fix validator for reduce_learning_rate_on_plateau by @carlogrisetti in https://github.com/ludwig-ai/ludwig/pull/2692
- Use TensorArray to speed up writing predictions with Ray by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2684
- Dataset size checks in preprocess_for_training by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2688
- Remove Duplicate Schema Fields by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2679
- Speed up tune_batch_size by using synthetic batches by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2680
- Add
bucketing_fieldParam to Trainer by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2694 - Fix InputDataError to be serializeable by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2695
- Adds PublicAPI annotation to api.py by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2698
- Cleanup: move to per-module loggers instead of the global logging object. (2) by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2699
- Adds Ray implementation of IntegratedGradientsExplainer that distributes across cluster resources by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2697
- Fixed bug with non-category outputs in RayIntegratedGradientsExplainer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2702
- Fix example values for max_batch_size in trainer parameter metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2705
- Fix incorrect internal_only flags on audio feature metadata by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2704
- add customer churn datasets by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2703
- Add Kaggle test splits by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2675
- Fix ComparatorCombiner by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2689
- Actually print the torchinfo summary in print_model_summary() by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2696
- Add H&M fashion recommendation dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2708
- Fix GBM ray nightly test by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2676
- Adds DeveloperAPI and PublicAPI annotations to AutoML by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2701
- Remove obsolete v0 whylogs callback. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2713
- fill_value / computed_fill_value fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2714
- Add path to RayDataset by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2716
- Fixed Horovod to be an optional import when doing Hyperopt by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2717
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2722
- Adds annotation to download_one method in benchmarks by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2712
- fix: Prevent shared parameter_metadata instances between
defaultsand_features. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2715 - Added ngram tokenizer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2723
- Revert "Add H&M fashion recommendation dataset (#2708)" by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2724
- Optimize search space for hyperopt tests to decrease test durations by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2730
- Add custom to_dask() to infer Dask metadata from Datasets schema. by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2728
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2735
- Bump Ludwig to Ray 2.0 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2729
- Parameter Metadata Updates by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2736
- Removes some vestigial code and replaces Tensorflow with PyTorch in comments by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2731
- @DeveloperAPI annotations for backend module by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2707
- int: Refactor
test_ray.pyto limit number of full train jobs by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2637 - BaseTrainer: add empty barrier() by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2734
- Use whylogs to generate dataset profiles for pandas and dask dataframes. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2710
- Add IntegerOptions marshmallow field by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2739
- Downgrade to Ray 2.0 in CI to get green Ludwig CIs again. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2742
- Adds @DeveloperAPI annotations to combiner classes by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2744
- Use clearer error messages in ludwig serving, and enable serving to work with configs that have stratified splitting on target columns. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2740
- Update Ray GPU Docker image to CUDA 11.6 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2747
- Fix https://github.com/ludwig-ai/ludwig/issues/1735 by @herrmann in https://github.com/ludwig-ai/ludwig/pull/2746
- Enable dataset window autosizing by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2721
- Downgrade to PyTorch 1.12.1 in Docker to due to NCCL + CUDA compatibility by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2750
- Replicate ludwig type inference, using the whylogs dataset profile. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2743
- fix:
Encountered unknown symbol 'foo'warning in Category feature preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2662 - Expand ~ in dataset download paths by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2754
- Updates twitter bots example to new datasets API by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2753
- fix: refactor
IntegerOptionsfield by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2755 - Added ray datasets repartitioning in cases of multiple train workers by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2756
- fix: Fix metadata object-to-JSON serialization for oneOf fields and add full schema serialization test. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2758
- refactor: Add
ProtectedStringfield (alias ofStringOptionsthat only allows one string) by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2757 - [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2761
- Updates ludwig docker readme by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2760
- Annotates ludwig.datasets API by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2751
- Annotate MLFlow callback, and utility functions by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2749
- Drishi sarcasmdataset 1 by @drishi in https://github.com/ludwig-ai/ludwig/pull/2725
- Add local_rank to BaseTrainer by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2766
- Public datasets by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2752
- Fix typo by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2767
- Correctly infer bool and object types in autoML by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2765
- feat: Hyperopt schema v0, part 1: Move output feature metrics from feature classes to feature configs. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2759
- Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2769
- Add ray version to runners by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2771
- Annotate Ludwig encoders and decoders by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2773
- Move preprocess callbacks inside model.preprocess by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2772
- Fix benchmark tests, update latest metrics, and use the local backend for GBM benchmark tests by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2748
- Ensure correct output reduction for text encoders like MT5 and add warning messages when not supported by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2774
- CVE-2007-4559 Patch by @TrellixVulnTeam in https://github.com/ludwig-ai/ludwig/pull/2770
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2776
- Fix double counting of training loss by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2775
- feat: Hyperopt schema v0, part 2: Make
BaseMarshmallowConfigabstract by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2779 - feat: Hyperopt schema v0, part 3: Enable optional min/max support for
FloatTupleMarshmallowFieldfields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2780 - feat: Hyperopt schema v0, part 4: Add and use new hyperopt registry, search algorithm instantiation by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2781
- Added exponential retry for mlflow, remote dataset loading by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2738
- Add synthetic test data integration test utils, and use them for loss value decrease tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2789
- feat: Hyperopt schema v0, part 5: Add basic search algorithm, scheduler, executor, and hyperopt schemas. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2784
- Add benchmark as a pytest marker to avoid warnings. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2786
- feat: Hyperopt schema v0, part 6: Enable new hyperopt schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2785
- Add sentencepiece as a requirement, which is necessary for some hf models like mt5. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2782
- [Annotations] Ludwig data modules by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2793
- [Annotations] Add DeveloperAPI annotations to Ludwig utils - Part 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2794
- [Annotations] Annotations for Ludwig's utils - Part 2 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2797
- [Annotations] Add annotations for schema module (part 1) - Model Config, Split, Trainer, Optimizers, Utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2798
- [Annotations] Annotate Schema Part 2: decoders, encoders, defaults, combiners, loss and preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2799
- Add new data utility functions for buffers and files, and rename registry by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2796
- [Annotations] Ludwig Schema - Part 3: Features, Hyperopt and Metadata by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2800
- [Annotations] Add annotations for Ludwig's data utils (file readers) by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2795
- Proceed with model training even if saving preprocessed data fails. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2783
- Improve warnings about backwards compatibility and dataset splitting. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2788
- Generate structural change warnings and log_once functionality by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2801
- Broadcast progress tracker dict to all workers by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2804
- Start fresh training run if files for resuming training are missing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2787
- LIghtGBMRayTrainer repartition datasets with fewer blocks than Ray actors by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2806
- Add InterQuartileTransformer normalization strategy for Number Features by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2805
- Add negative sampling to ludwig.data by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2711
- Rectify output features in dataset config by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2768
- int: Add JSON markup to support unique input feature names. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2792
- int: Replace
StringOptionsusage withProtectedStringin split schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2808 - int: Replace
StringOptionswithProtectedStringfor combiner schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2809 - refactor: Replace
StringOptionswithProtectedStringfor encoder/decoder schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2810 - Upload Datasets to Remote Location by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2764
- [Annotations] Annotate AutoML utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2812
- [Annotations] Ludwig Visualizations by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2813
- [Annotations] Logging Level Registry by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2814
- refactor: Replace
StringOptionswithProtectedStringfor loss/hyperopt schematypefields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2816 - Define custom Ludwig types and replace Dict[str, Any] type hints with them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2556
- Config Object Bug Fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2817
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2803
- AutoML libraries that use DatasetProfile instead of DatasetInfo by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2802
- Remove Sentencepiece by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2821
- fix: account for
max_batch_sizeconfig param in batch size tuning on cpu by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2693 - [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2823
- refactor: Add filtering based on
model_typefor feature, combiner, and model type schemas by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2815 - [TorchScript] Add user-defined HF Bert tokenizers by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2733
- [Annotations] Move feature registries into accessor functions by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2818
- [Annotations] Encoder and Decoder Registries by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2819
- Speed Up Ray Image Tests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2828
- fix: Restrict allowed top-level config keys by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2826
- Moves image decoding out of Ray Datasets to Dask Dataframe by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2737
- Improve type hints and remove dead code for DatasetLoader module by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2833
- Update stratified split with a more specific exception for underpopulated classes by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2831
- Add Ludwig contributors to README by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2835
- Fix key error in AutoML model select by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2824
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2836
- Drop incomplete batches for Ray and Pandas to prevent Batchnorm computation errors by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2778
- Catch and surface Runtime exceptions during preprocessing by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2839
- fix: Mark
widthandheightasinternal_onlyfor image encoders by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2842 - Select best batch size to maximize training throughput by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2843
- Make batch_size=auto more consistent by using median of 5 steps by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2846
- Make trainable=False default for all pretrained models by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2844
- fix: Add back missing split fields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2848
- Pin scikit-learn<1.2.0 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2850
- text_encoder: RoBERTa max_sequence_length by @rudolfolah in https://github.com/ludwig-ai/ludwig/pull/2852
- Fix TorchText version in tokenizers ahead of torch 1.13.0 upgrade by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2838
- Fix
trainable=Falseto freeze all params for HF encoders by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2855 - Add support for automatic mixed precision (AMP) training by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2857
- Evaluate training set in the training loop by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2856
- Extend parameter guidance documentation for regularization, and add explicit maxes to Non-Negative floats by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2849
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2860
- Fixes for the roberta encoder: explicitly set max sequence length, and fix output shape computation by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2861
- Enables Set output feature on Ray by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2791
- Add go module for dataset profile protos. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2834
- fix: Upgrade
expected_impactfortrainabletoMEDIUMon all encoders. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2865 - support stratified split with low cardinality features by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2863
- fix: load spacy model for lemmatization in
EnglishLemmatizeFilterTokenizerto work by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2868 - Token-level explanations by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2864
- Replace
learning rate: autowith feature type and encoder-based heuristics by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2854 - Set RayBackend Config to use single worker for tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2853
- Remove
_to_tensors_fnfrom Ray Datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2866 - Remove ludwig-dev Dockerfile by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2873
- Support Ray GPU image with Torch 1.13 and CUDA 11.6 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2869
- Use native LightGBM for intermittent eval during training by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2829
- Set default validation metrics based on the output feature type. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2820
- Auto resize images for ViTEncoder when use_pretrained is True or False by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2862
- TLE Backwards Compatibility Fixes by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2875
- Do not drop batch size dimension for single inputs by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2878
- Save GBM after training if not previously saved by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2880
- Fix TLE - Pt. 2 by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2881
- Tle fix by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2883
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2885
- Convert schema metadata to YAML by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2884
- Automatically infer vector_size for vector features when not provided by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2888
- Support MLFlowCallback logging to an existing run by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2892
- Fix dataset synthesizer by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2894
- Add a clear error message about invalid column names in GBM datasets by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2879
- Explicitly track all metrics related to the best evaluation in the progress tracker. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2827
- Added DistributedStrategy interface with support for DDP by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2890
- Adopt PyTorch official LRScheduler API by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2877
- Annotate Confusion Matrix with updated cmap by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2899
- Dynamically resize confusion matrix and f1 plots by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2900
- Update backward compatibility tests for LR progress tracker changes made in #2877. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2904
- fix: Fix vague initializer JSON schema titles. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2909
- Support Distributed Training And Ray Tune with Ray 2.1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2709
- Expand vision models to support pre-trained models by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2408
- Add ECD Descriptions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2897
- Simplify titanic example to read config in-line, and skip saving processed input. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2912
- Adds quick fix for pretrained models not loading by modifying state_dict keys on load. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2911
- fix: Schema split conditions should pass in [TYPE] and not string by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2917
- Refactor metrics and metric tables and support adding more in-training metrics. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2901
- Updated AutoML configs for latest schema and added validation tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2921
- Adds backwards compatibility for legacy image encoders by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2916
- Pin Torch to
>=1.13.0by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2914 - Hyperopt invalid GBM config by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2926
- Store mlflow tracking URI to ensure consistency across processes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2927
- Update automl heuristics for fine-tuning and multi-modal tasks by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2922
- Bump torch version for benchmark tests by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2929
- Fix signing key by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2928
- Adds safe_move_directory to fs_utils by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2931
- Added separate AutoML APIs for feature inference and config generation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2932
- Dynamic resizing for Confusion Matrix, Brier, F1 Plot, etc. by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2936
- Raise RuntimeError only for category output features with vocab size 1 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2923
- Bump min python to 3.8 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2930
- Evaluate training set in the training loop (GBM) by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2907
- [automl] Exclude text fields with low avg words by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2941
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2944
- Fix pre-commit by removing manually specified blacken-docs dep. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2949
- Rotate Brier Plot X-axis labels to 45 degree angle by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2948
- Retry HuggingFace pretrained model download on failure by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2951
- Disable AUROC for CATEGORY features. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2950
- Deactivate GBM random forest boosting type by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2954
- Make batch_size=auto the default by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2845
- Twitter bots test small improvements by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2955
- Disable bagging when using GOSS GBM boosting type by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2956
- Add missing standardize_image key to metadata by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2946
- Integrated Gradients: reset sample_ratio to 1.0 if set by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2945
- Increase CI pytest time out to 75 minutes by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2958
- Add
sacremosesas a dependency for transformer_xl encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2961 - Move all config validation to its own standalone module,
config_validation. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2959 - Fixes longformer encoder by passing in pretrained_kwargs correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2963
- Expected Impact Calibration by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2960
- Update Camembert by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2966
- fix: Fix
epochssuggested range by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2965 - fix: enable binary dense encoder by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2957
- GBM DART boosting type incopatible with early stopping by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2964
- Improving metadata config descriptions by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/2933
- Fix ludwig-gpu image by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2974
- Skip test_ray_outputs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2935
- Enable custom HF BERT models with default tokenizer config by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2973
- Update CamemBERT in schema by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2975
- Set reduce_output to sum for XLM encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2972
- Skipped mercedes_benz_greener.ecd.yaml benchmark test by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2980
- Add sentencepiece as a requirement for MT5 text encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2967
- Disable CTRL Encoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2976
- MT5 reduce_output can't be cls_pooled - set to sum by default by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2981
- Populate hyperopt defaults using schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2968
- Revert "Add sentencepiece as a requirement for MT5 text encoder (#2967)" and disable MT5 Encoder by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2982
- Change default reduce_output strategy to sum for CamemBERT by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2984
- Set
max_failuresfor Tuner to 0 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2987 - Fix TLE OOM for BERT-like models by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2990
- Reorder Advanced Parameters by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2979
- [Hyperopt] Modify _get_best_model_path to grab it from the Checkpoint object with ExperimentAnalysis by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2985
- GBM: disable goss boosting type by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2986
- Adds HuggingFace pretrained encoder unit tests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2962
- [Hyperopt] Set default num_samples based on parameter space by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2997
- LR Scheduler Adjustments by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2996
- fix: Force populate combiner registry inside of
get_schemafunction. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2970 - fix: Fix validation and serialization for
BooleanandOneOfOptionsFieldfields by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2992 - Ray 2.2 compatibility by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2910
- Compute fixed text embeddings (e.g., BERT) during preprocessing by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2867
- Use iloc to fetch first audio value. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3006
- Fix Internal Only Param by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3008
- Ludwig Dataclass by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/3005
- Cap batch_size=auto at 128 for CPU training by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3007
- Added ghost batch norm option for concat combiner by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3001
- Refactored norm layer and added additional norm at the start of the FCStack by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3011
- Fix assignment that undoes tensor move to CPU by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/3012
- [Explain] Detach inputs before numpy processing by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3014
- Handle CUDA OOMs in explanations with retry and batch size halving by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3015
- fix: Remove
ecd_ray_legacymodel type alias. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/3013 - Explain fixes by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3016
- Remove
nullGBM trainer config options by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2989 - Disable reuse_actors in hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3017
- Skip Sarcos dataset during benchmark tests by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/3020
- Explain: improve docstring about IntegratedGradient baseline for number features by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3018
- Upgrade isort to fix pre-commit. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/3027
- Limit batch size tuning to ≤20% of dataset size by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/3003
- [schema] Mark skip internal only by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3022
- Add specificity metric for binary features by @jppgks in https://github.com/ludwig-ai/ludwig/pull/3025
- Added FSDP distributed strategy by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/3026
New Contributors
- @Marvjowa made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2236
- @Dennis-Rall made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2192
- @abidwael made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2263
- @noahlh made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2284
- @jeffkinnison made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2316
- @andife made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2358
- @alberttorosyan made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2413
- @herrmann made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2746
- @drishi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2725
- @TrellixVulnTeam made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2770
- @rudolfolah made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2852
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.3...v0.7.beta
Published by arnavgarg1 almost 2 years ago
What's Changed
- Field fix: by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2714
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2719
- Bump Ludwig to 0.6.4 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2720
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6.3...v0.6.4
Published by justinxzhao about 2 years ago
What's Changed
- Cherry-pick remote file syncing with hyperopt by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2644
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2646
- Cherry-pick bb8bef02c002eccbb6369292ac54490875bebbc4 by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2651
- Cherry-pick: Ensure no ghost ray instances are running in tests (#2607) by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2654
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2660
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2677
- Update version to v0.6.3 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2682
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6.2...v0.6.3
Published by justinxzhao about 2 years ago
What's Changed
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2594
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2602
- 0.6.2: cherry-pick Explanation API by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2604
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2609
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2608
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2613
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2618
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2634
- Cherrypick: feat: adds max_batch_size to auto batch size functionality by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2632
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2636
- Update version to 0.6.2 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2624
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6.1...v0.6.2
Published by justinxzhao about 2 years ago
What's Changed
- Cherry pick hyperopt plots by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2567
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2571
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2572
- fix: Limit frequency array to top_n_classes in F1 viz (#2565) by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2575
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2581
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2583
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2590
- Cherrypick: Comprehensive Configs by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2580
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2591
- Update version to 6.1 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2582
- Readme fixes by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2592
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6...v0.6.1
Published by justinxzhao about 2 years ago
Overview
Ludwig 0.6 introduces several exciting features focused on modeling, deployment, and testing that make it more flexible, reliable, and easy to use in production.
- Gradient boosted models: Historically, Ludwig has been built around a single, flexible neural network architecture called ECD (for Encoder-Combiner-Decoder). With the release of 0.6 we are adding support for a different model architecture: gradient-boosted tree models (GBMs).
- Richer configuration schema and validation: We formalized the schema of Ludwig configurations and now validate it before initialization, which can help you avoid mistakes like typos and syntax errors.
- Probability calibration for binary and multi-class classification: With deep neural networks, the probabilities given by models often don't match the true likelihood of the data. Ludwig now supports temperature scaling calibration (On Calibration of Modern Neural Networks), which brings class probabilities closer to their true likelihoods in the validation set.
- Pipelined TorchScript: We improved the TorchScript model export functionality, making it easier than ever to train and deploy models for high performance inference.
- Model parameter update unit tests: The code to update parameters of deep neural networks can be too complex for developers to make sure the model parameters are updated. To address this difficulty and improve the robustness of our models, we implemented a reusable utility to ensure parameters are updated during one cycle of a forward-pass / backward-pass / optimizer step.
Additional improvements include a new global configuration section, time-based dataset splitting and more flexible hyperparameter optimization configurations. Read more about each specific feature below.
If you are learning about Ludwig for the first time, or if these new features are relevant and exciting to your research or application, we'd love to hear from you. Join our Ludwig Slack Community here.
Gradient Boosted Models (@jppgks)
Historically, Ludwig has been built around a single, flexible neural network architecture called ECD (for Encoder-Combiner-Decoder). With the release of 0.6 we are, adding support for a different model architecture: gradient-boosted tree models (GBM).
This is motivated by the fact that tree models still outperform neural networks on some tabular datasets, and the fact that tree models are generally less compute-intensive, making them a better choice for some applications. In Ludwig, users can now experiment with both neural and tree-based architectures within the same framework, taking advantage of all of the additional functionalities and conveniences that Ludwig offers like: preprocessing, hyperparameter optimization, integration with different backends (local, ray, horovod), and interoperability with different data sources (pandas, dask, modin).
How to use it
Install the tree extra package with pip install ludwig[tree]. After the installation, you can use the new gbm model type in the configuration. Ludwig will default to using the ECD architecture, which can be overridden as follows to use GBM:
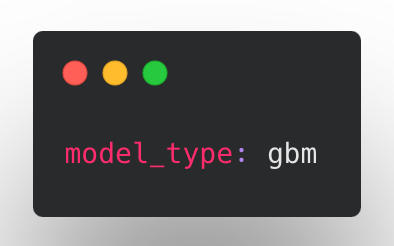
In some initial benchmarking we found that GBMs are particularly performant on smaller tabular datasets and can sometimes deal better with class imbalance compared to neural networks. Stay tuned for a more in-depth blogpost on the topic. Like the ECD neural networks, GBMs can be sensitive to hyperparameter values, and hyperparameter tuning is important to get a well-performing model.
Under the hood, Ludwig uses LightGBM for training gradient-boosted tree models, and the LightGBM trainer parameters can be configured in the trainer section of the configuration. For serving, the LightGBM model is converted to a PyTorch graph using Hummingbird for efficient evaluation and inference.
Limitations
Ludwig's initial support for GBM is limited to tabular data (binary, categorical and numeric features) with a single output feature target.
Calibrating probabilities for category and binary output features (@dantreiman)
Suppose your model outputs a class probability of 90%. Is there a 90% chance that the model prediction is correct? Do the probabilities given by your model match the true likelihood of the data? With deep neural networks, they often don't.
Drawing on the methods described in On Calibration of Modern Neural Networks (Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q. Weinberger), Ludwig now supports temperature scaling for binary and category output features. Temperature scaling brings a model's output probabilities closer to the true likelihood while preserving the same accuracy and top k predictions.
How to use Calibration
To enable calibration, add calibration: true to any binary or category output feature configuration:

With calibration enabled, Ludwig will find a scale factor (temperature) which will bring the class probabilities closer to their true likelihoods in the validation set. The calibration scale factor is determined in a short phase after training is complete. If no validation split is provided, the training set is used instead.
To visualize the effects of calibration in Ludwig, you can use Calibration Plots, which bin the data based on model probability and plot the model probability (X) versus observed (Y) for each bin (see code examples).
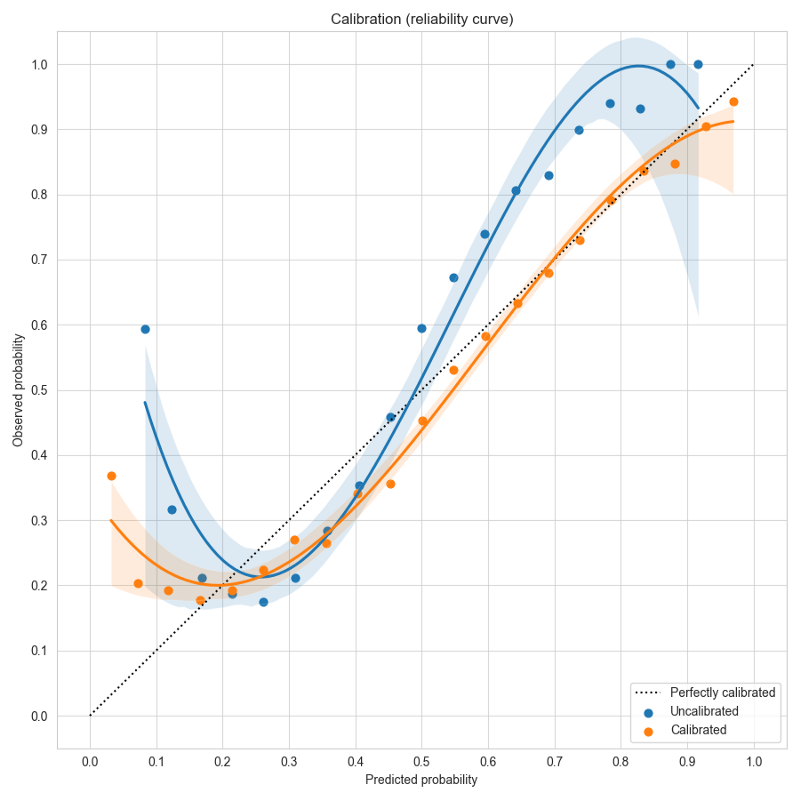
In a perfectly calibrated model, the observed probability equals the predicted probability, and all predictions will land on the dotted line y=x. In this example using the forest cover dataset, the uncalibrated model in blue gives over-confident predictions near the left and right edges close to probability values of 0 or 1. Temperature scaling learns a scale factor of 0.51 which improves the calibration curve in orange, moving it closer to y=x.
Limitations
Calibration is currently limited to models with binary and category output features.
Richer configuration schema and validation (@connor-mccorm @ksbrar @justinxzhao )
Ludwig configurations are flexible by design, as they internally map to Python function signatures. This allows configurations for expressive configurations with many parameters for the users to play with, but we have found that users would too easily have typos in their configs like incorrect value types or other syntactical inconsistencies that were not easy to catch.
We have now formalized the Ludwig config with a strongly typed schema, serving as a centralized source of truth for parameter documentation and config validation. Ludwig validation now explicitly restricts each parameter's values to valid ones, decreasing the chance of syntactical and logical errors and signaling immediately to the user where the issues lie, before processing data or starting training. Schemas also provide many future benefits including autocompletion.
Nested encoder and decoder parameters (@connor-mccorm )
We have also restructured the way that encoders and decoders are configured to now use a nested structure, consistent with other modules in Ludwig such as combiners and loss.
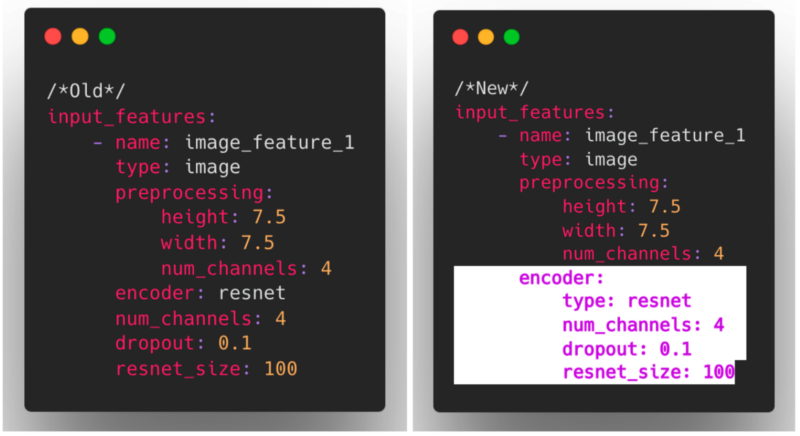
As these changes impact what constitutes a valid Ludwig config, we also introduced a mechanism for ensuring backward compatibility that invisibly and automatically upgrades older configs to the current config structure.
We hope with the new Ludwig schema and the improved encoder/decoder nesting structure, that you find using Ludwig to be a much more robust and user friendly experience!
New Defaults Ludwig Section (@arnavgarg1 )
In Ludwig 0.5, users could specify global preprocessing parameters on a per-feature-type basis through the preprocessing section in Ludwig configs. This is useful if users know they always want to apply certain transformations to their data for every feature of the same type. However, there was no equivalent mechanism for global encoder, decoder or loss related parameters.
For example, say we have a mammography dataset to predict breast cancer that contains many categorical features. In Ludwig 0.5, we might define our input features with encoder parameters in the following way:
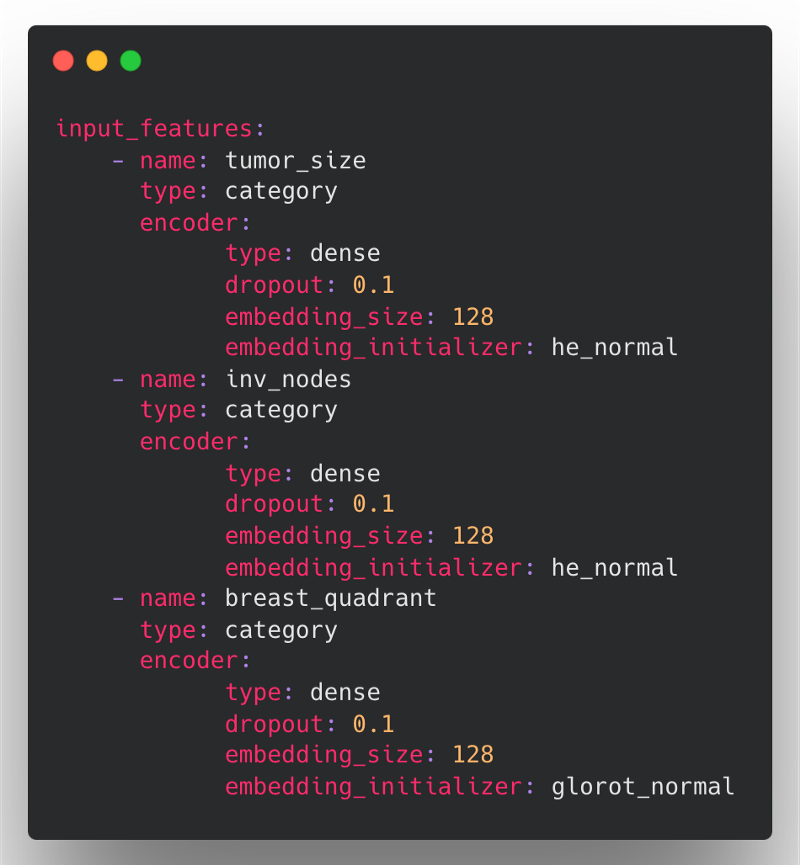
Here, the problem is that we have to redefine the same encoder parameters (type, dropout, and embedding_size) for each of the input features if we want to override the default value across all categorical features.
In Ludwig 0.6, we are introducing a new defaults section within the Ludwig config to define feature-type defaults for preprocessing, encoders, decoders, and loss. Default preprocessing and encoder configurations will be applied to all input_features of that feature type, while decoder and loss configurations will be applied to all output_features of that feature type.
Note that you can still specify feature specific parameters as usual, and these will override any default parameter values that come from the global defaults section.
The same mammography config above could be defined in the following, much more concise way in Ludwig 0.6:
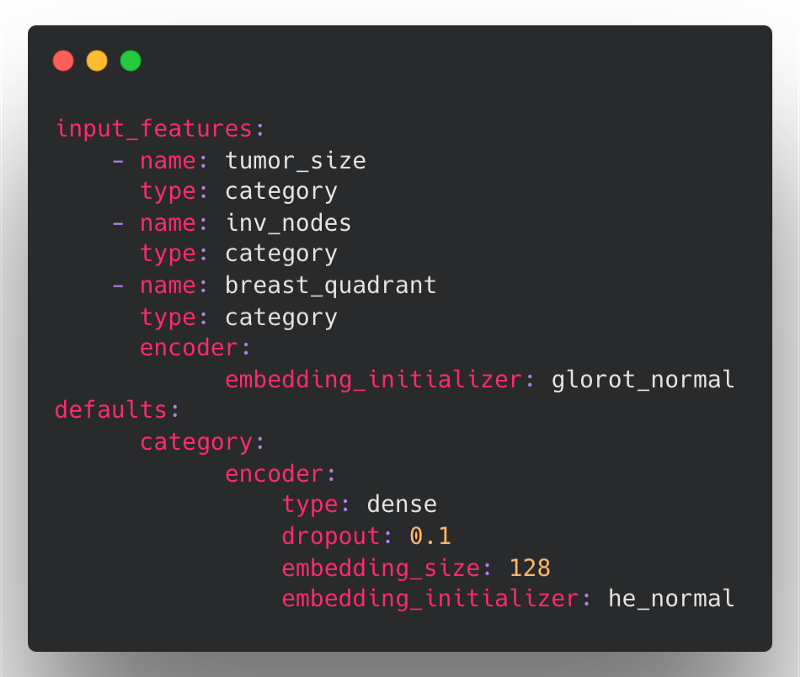
Here, the encoder defaults for type, dropout and embedding_size are applied to all three categorical features. The he_normal embedding initializer is only applied to tumor_size and inv_nodes since we didn't specify this parameter in their feature definitions, but breast_quadrant will use the glorot_normal initializer since it will override the value from the defaults section.
Additionally, in Ludwig 0.6, we have moved all global feature-type preprocessing within this new defaults section from the preprocessing section.
The defaults section enables the same fine-grained control with the benefit of making your config easier to define and read.
Global Defaults In Hyperopt (@arnavgarg1 )
The defaults section has also been added to hyperopt, so that users can define feature-type level parameters for individual trials. This makes the definition of the hyperopt search space more convenient, without the need to define individual parameters for each of the features in instances where the dataset has a large number of input or output features.
For example, if you want to hyperopt over different encoders for all text features for each of the trials, one can do so by defining a parameter this way:
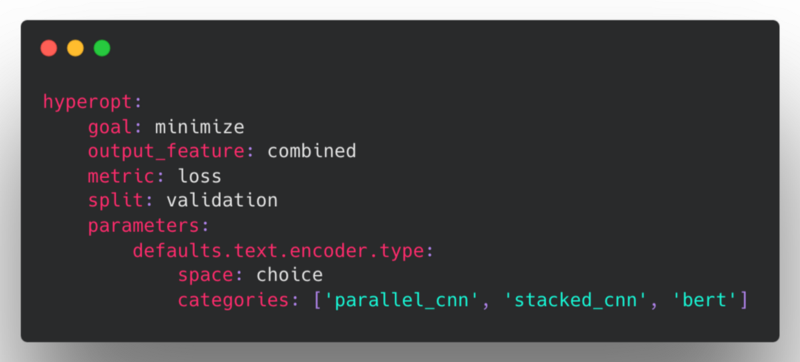
This will sample one of the three encoders for text features and apply it to all the text features for that particular trial.
Nested Configs In Hyperopt (@tgaddair )
We have extended the range of hyperopt parameters to support parameter choices that consist of partial or complete blocks of nested Ludwig config sections. This allows users to search over a set of Ludwig configs, as opposed to needing to specify config params individually and search over all combinations.
To provide a parameter that represents a full top-level Ludwig config, the . key name can be used.
For example, we can define a hyperopt search space where we sample partial Ludwig configs in the following way would create hyperopt samples that look like the following:
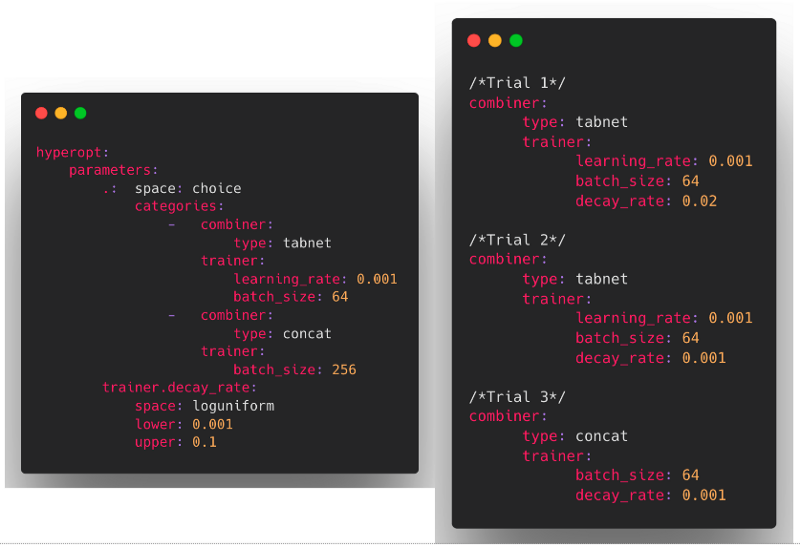
Pipelined TorchScript (@geoffreyangus @brightsparc )
In Ludwig v0.6, we improved the TorchScript model export functionality, making it easier than ever to train and deploy models for high performance inference.
At the core of our implementation is a pipeline-based approach to exporting models. After training a Ludwig model, users can run the export_torchscript command in the CLI, or call LudwigModel.save_torchscript. If model training was performed on a GPU device, doing so produces three new TorchScript artifacts:
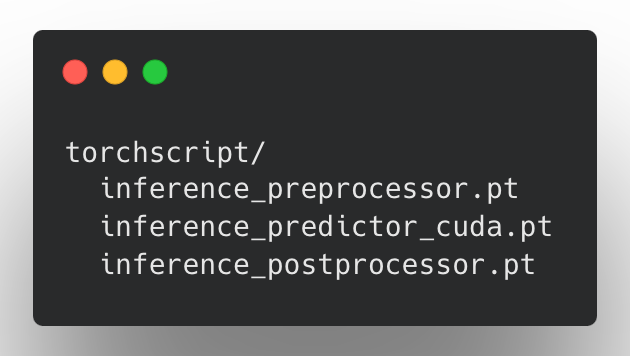
These artifacts represent a single LudwigModel as three modules, each separated by stage: preprocessing, prediction, and postprocessing. These artifacts can be pipelined together using the InferenceModule class method InferenceModule.from_directory, or with some tools such as NVIDIA Triton.
One of the most significant benefits is that TorchScripted models are backend and environment independent and different parts can run on different hardware to maximize throughput. They can be loaded up in either a C++ or Python backend, and in either, minimal dependencies are required to run model inference. Such characteristics ensure that the model itself is both highly portable and backward compatible.
Time-based Dataset Splitting (@tgaddair )
In Ludwig v0.6, we have added the ability to split based on a date column such that the data is ordered by date (ascending) and then split into train-validation-test along the time dimension. To make this possible, we have reworked the way splitting is handled in the Ludwig configuration to support a dedicated split section:
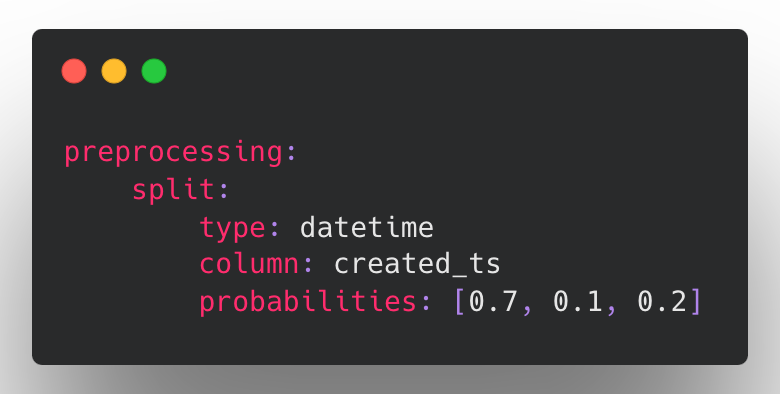
In this example, by setting probabilities: [0.7, 0.1, 0.2], the earliest 70% of the data will be used for training, the middle 10% used for validation, and the last 20% used for testing.
This feature is important to support backtesting strategies where the user needs to know if a model trained on historical data would have performed well on unseen future data. If we were to use a uniformly random split strategy in these cases, then the model performance may not reflect the model's ability to generalize well if the data distribution is subject to change over time. For example, imagine a model that is predicting housing prices. If we both train and test on data from around the same time, we may fool ourselves into believing our model has learned something fundamental about housing valuations when in reality it might just be basing its predictions on recent trends in the market (trends that will likely change once the model is put into production). Splitting the training from the test data along the time dimension is one way to avoid this false sense of confidence, by showing how well the model should do on unseen data from the future.
Prior to Ludwig v0.6, the preprocessing configuration supported splitting based on a split column, split probabilities (train-val-test), or stratified splitting based on a category, all of which were flattened into the top-level of the preprocessing section:
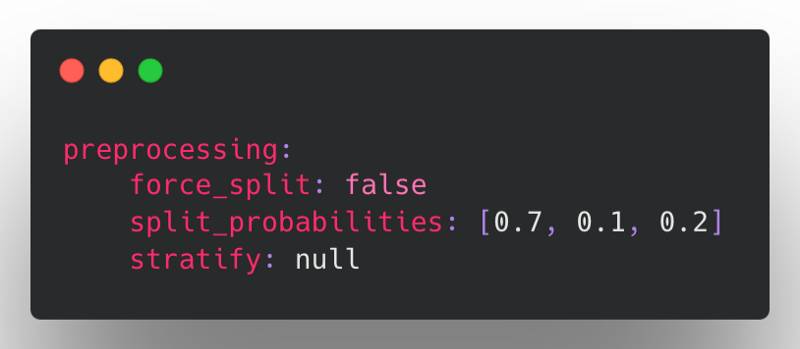
This approach was limiting in that every new split type required reconciling all of the above params and determining how they should interact with the new type. To resolve this complexity, all of the existing split types have been similarly reworked to follow the new structure supported for datetime splitting.
Examples
Splitting by row at random (default):
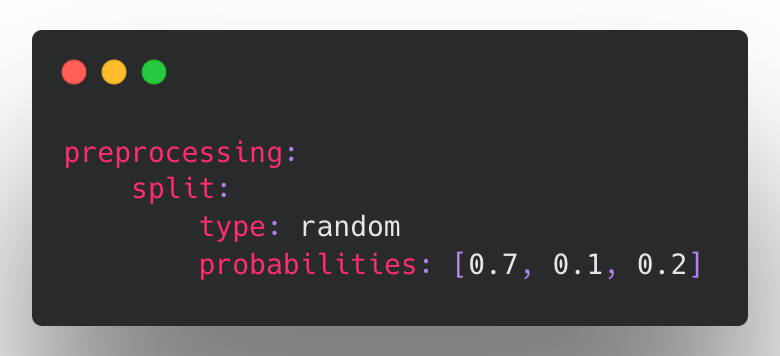
Splitting based on a fixed column.

Stratified splits using a chosen stratification category column.
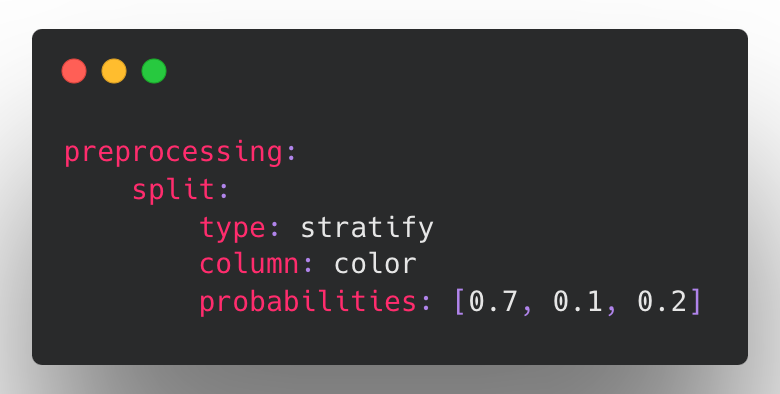
Be on the lookout as we continue to add additional split strategies in the future to support advanced usage such as bucketed backtesting. If you are interested in these kinds of scenarios, please reach out!
Parameter Update Unit Tests (@jimthompson5802 )
A significant step was taken in this release to improve the code quality of Ludwig components, e.g., encoders, combiners, and decoders. Deep neural networks have many layers composed of a large number of parameters that must be updated to converge to a solution. Depending on the particular algorithm, the code for updating parameters during training can be quite complex. As a result, it is near impossible for a developer to reason through an analysis that confirms model parameters are updated.
To address this difficulty, we implemented a reusable utility to perform a quick sanity check to ensure parameters, such as tensor weights and biases, are updated during one cycle of a forward-pass / backward-pass / optimizer step. This work was inspired by these earlier blog postings: How to unit test machine learning code and Testing Your PyTorch Models with Torcheck.
This utility was added to unit tests for existing Ludwig components. With this addition, unit tests for Ludwig now ensure the following:
- No run-time exceptions are raised
- Generated output are the correct data type and shape
- (New capability) Model parameters are updated as expected
The above is an example of a unit test. First, it sets the random number seed to ensure repeatability. Next, the test instantiates the Ludwig component and processes synthetic data to ensure the component does not raise an error and that the output has the expected shape. Finally, the unit test checks if the parameters are updated under the different combinations of configuration settings.
In addition to the new parameter update check utility, Ludwig's Developer Guide contains instructions for using the utility. This allows an advanced user or a contributor, who is developing custom encoders, combiners, or decoders, to ensure the quality of their custom component.
Stay in the loop
Ludwig thriving open source community gathers on Slack, join it to get involved!
If you are interested in adopting Ludwig in the enterprise, check out Predibase, the declarative ML platform that connects with your data, manages the training, iteration, and deployment of your models, and makes them available for querying, reducing time to value of machine learning projects.
Full Changelog
- Fix ray nightly import by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2196
- Restructured split config and added datetime splitting by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2132
- enh: Implements
InferenceModuleas a pipelined module with separate preprocessor, predictor, and postprocessor modules by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2105 - Explicitly pass data credentials when reading binary files from a RayBackend by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2198
- MlflowCallback: do not end run on_trainer_train_teardown by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2201
- Fail hyperopt with full import error when Ray not installed by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2203
- Make convert_predictions() backend-aware by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2200
- feat: MVP for explanations using Integrated Gradients from captum by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2205
- [Torchscript] Adds GPU-enabled input types for Vector and Timeseries by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2197
- feat: Added model type GBM (LightGBM tree learner), as an alternative to ECD by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2027
- [Torchscript] Parallelized Text/Sequence Preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2206
- feat: Adding feature type shared parameter capability for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2133
- Bump up version to 0.6.dev. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2209
- Define
FloatOrAutoandIntegerOrAutoschema fields, and use them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2219 - Define a dataclass for parameter metadata. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2218
- Add explicit handling for zero-length image byte buffers to avoid cryptic errors by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2210
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2231
- Create dataset util to form repeatable train/vali/test split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2159
- Bug fix: Use safe rename which works across filesystems when writing checkpoints by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2225
- Add parameter metadata to the trainer schema. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2224
- Add an explicit call to merge_wtih_defaults() when loading a config from a model directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2226
- Fixes flaky test test_datetime_split[dask] by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2232
- Fixes prediction saving for models with Set output by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2211
- Make ExpectedImpact JSON serializable by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2233
- standardised quotation marks, added missing word by @Marvjowa in https://github.com/ludwig-ai/ludwig/pull/2236
- Add boolean postprocessing to dataset type inference for automl by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2193
- Update get_repeatable_train_val_test_split to handle non-stratified split w/ no existing split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2237
- Update R2 score to handle single sample computation by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2235
- Input/Output Feature Schema Refactor by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2147
- Fix nan in entmax loss and flaky sparsemax/entmax loss tests by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2238
- Fix preprocessing dataset split API backwards compatibility upgrade bug. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2239
- Removing duplicates in constants from recent PRs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2240
- Add attention scores of the vit encoder as an additional return value by @Dennis-Rall in https://github.com/ludwig-ai/ludwig/pull/2192
- Unnest Audio Feature Preprocessing Config by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2242
- Fixed handling of invalud number values to treat as missing values by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2247
- Support saving numpy predictions to remote FS by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2245
- Use global constant for description.json by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2246
- Removed import warnings when LightGBM and Ray not requested by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2249
- Adds ability to read images from numpy files and numpy arrays by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2212
- Hyperopt steps per epoch not being computed correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2175
- Fixed splitting when providing pre-split inputs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2248
- Added Backwards Compatibility for Audio Feature Preprocessing by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2254
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2256
- Fix: Don't skip saving the model if the save path already exists. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2264
- Load best weights outside of finally block, since load may throw an exception by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2268
- Reduce number of distributed tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2270
- [WIP] Adds
inference_utils.pyby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2213 - Run github checks for pushes and merges to *-stable. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2266
- Add ludwig logo and version to CLI help text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2258
- Add hyperopt_statistics.json constant by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2276
- fix: Make
BaseTrainerConfigan abstract class by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2273 - [Torchscript] Adds
--deviceargument toexport_torchscriptCLI command by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2275 - Use pytest tmpdir fixture wherever temporary directories are used in tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2274
- adding configs used in benchmarking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2263
- Fixes #2279 by @noahlh in https://github.com/ludwig-ai/ludwig/pull/2284
- adding hardware usage and software packages tracker by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2195
- benchmarking utils by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2260
- dataclasses for summarizing benchmarking results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2261
- Benchmarking core by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2262
- Fixed default eval_batch_size when setting batch_size=auto by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2286
- Remove obsolete postprocess_inference_graph function. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2267
- [Torchscript] Adds BERT tokenizer + partial HF tokenizer support by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2272
- Support passing ground_truth as df for visualizations by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2281
- catching urllib3 exception by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2294
- Run pytest workflow on release branches. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2291
- Save checkpoint if train_steps is smaller than batcher's steps_per_epoch by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2298
- Fix typo in amazon review datasets: s/review_tile/review_title by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2300
- Refactor non-distributed automl utils into a separate directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2296
- Don't skip normalization in TabNet during inference on a single row. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2299
- Fix error in postproc_predictions calculation in model.evaluate() by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2304
- Test for parameter updates in Ludwig components by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2194
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2311
- Use warnings to suppress repeated logs for failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2312
- Use ray dataset and drop type casting in binary_feature prediction post processing for speedup by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2293
- Add size_bytes to DatasetInfo and DataSource by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2306
- Fixes TensorDtype TypeError in Ray nightly by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2320
- Add configuration section for global feature parameters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2208
- Ensures unit tests are deleting artifacts during teardown by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2310
- Fixes unit test that had empty Dask partitions after splitting by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2313
- Serve json numpy encoding by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2316
- fix: Mlflow config being injected in hyperopt config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2321
- Update tests that use preprocessing to match new defaults config structure by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2323
- Bump test timeout to 60 minutes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2325
- Set a default value for size_bytes in DatasetInfo by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2331
- Pin nightly versions to fix CI by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2327
- Log number of failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2317
- Add test with encoder dependencies for global defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2342
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2334
- Add wine quality notebook to demonstrate using config defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2333
- fix: GBM tests failing after new release from upstream dependency by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2347
- fix: restore overwrite of eval_batch_size on GBM schema by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2345
- Removes empty partitions after dropping rows and splitting datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2328
- fix: Properly serialize
ParameterMetadatato JSON by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2348 - Test for parameter updates in Ludwig Components - Part 2 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2252
- refactor: Replace bespoke marshmallow fields that accept multiple types with a new 'combinatorial'
OneOfFieldthat accepts other fields as arguments. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2285 - Use Ray Datasets to read binary files in parallel by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2241
- typos: Update README.md by @andife in https://github.com/ludwig-ai/ludwig/pull/2358
- Respect the resource requests in RayPredictor by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2359
- Resource tracker threading by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2352
- Allow writing init_config results to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2364
- Fixed export_mlflow command to not assume an existing registered_model_name by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2369
- fix: Fixes to serialization, and update to allow set repo location. by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2367
- Add amazon employee access challenge kaggle dataset by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2349
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2362
- Wrap read of cached training set metadata in try/except for robustness by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2373
- Reduce dropout prob in test_conv1d_stack by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2380
- fever: change broken download links by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2381
- Add default split config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2379
- Fix CI: Skip failing ray GBM tests by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2391
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2389
- Triton ensemble export by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2251
- Fix: Random dataset splitting with 0.0 probability for optional validation or test sets. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2382
- Print final training report as tabulated text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2383
- Add Ray 2.0 to CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2337
- add GBM configs to benchmarking by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2395
- Optional artifact logging for MLFlow by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2255
- Simplify ludwig.benchmarking.benchmark API and add ludwig benchmark CLI by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2394
- rename kaggle_api_key to kaggle_key by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2384
- use new URL for yosemite dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2385
- Encoder refactor V2 by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2370
- re-enable GBM tests after new lightgbm-ray release by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2393
- Added option to log artifact location while creating mlflow experiment by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2397
- Treat dataset columns as object dtype during first pass of handle_missing_values by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2398
- fix: ParameterMetadata JSON serialization bug by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2399
- Adds registry to organize backward compatibility updates around versions and config sections by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2335
- Include split column in explanation df by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2405
- Fix AimCallback to model_name as Run.name by @alberttorosyan in https://github.com/ludwig-ai/ludwig/pull/2413
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2410
- Hotfix: features eligible for shared params hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2417
- Nest FC Params in Decoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2400
- Hyperopt Backwards Compatibility by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2419
- Investigating test_resnet_block_layer intermittent test failure by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2414
- fix: Remove duplicate option from
cell_typefield schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2428 - Test for parameter updates in Ludwig Combiners - Part 3 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2332
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2430
- Hotfix: Proc column missing in output feature schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2435
- Nest hyperopt parameters into decoder object by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2436
- Fix: Make the twitter bots modeling example runnable by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2433
- Add MLG-ULB creditcard fraud dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2425
- Bugfix: non-number inputs to GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2418
- GBM: log intermediate progress by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2421
- Fix: Upgrade ludwig config before schema validation by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2441
- Log warning for calibration if validation set is trivially small by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2440
- Fixes calibration and adds example scripts by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2431
- Add medical no-show appointments dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2387
- Added conditional check for UNK token insertion into category feature vocab by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2429
- Ensure synthetic dataset unit tests to clean up extra files. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2442
- Added feature specific parameter test for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2329
- Fixed version transformation to accept user configs without ludwig_version by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2424
- Fix mulitple partition predict by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2422
- Cache jsonschema validator to reduce memory pressure by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2444
- [tests] Added more explicit lifecycle management to Ray clusters during tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2447
- Fix: explicit keyword args for seaborn plot fn by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2454
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2453
- Extended hyperopt to support nested configuration block parameters by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2445
- Consolidate missing value strategy to only include bfill and ffill by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2457
- fix: Switched Learning Rate to NonNegativeFloat Field by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2446
- Support GitHub Codespaces by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2463
- Enh: quality-of-life improvements for
export_torchscriptby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2459 - Disables
batch_size: autofor CPU-only training by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2455 - buxfix: triton model version as a string by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2461
- Updating images to Ray 2.0.0 and CUDA 11.3 by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2390
- Loss, Split, and Defaults Schema Additions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2439
- More precise resource usage tracking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2363
- Summarizing performance metrics and resource usage results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2372
- [release-0.6] Cherry-pick bugfixes from upstream by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2471
- [release-0.6] Cherry-pick upstream commits by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2473
- [release-0.6] Cherry-pick upstream by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2476
- Cherry-pick backwards-compatibility fixes by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2487
- [cherry-pick] Fixed usage of checkpoints for AutoML in Ray 2.0 (#2485) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2491
- fix: Automatically assign title to OneOfOptionsField (#2480) by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2492
- [cherry-pick] Fixed stratified splitting with Dask (#1883) by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2494
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2505
- AUTO: Enable hyperopt to be launched from a ray client by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2504
- [cherry-pick] Pin transformers < 4.22 until issues resolved (#2495) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2510
- [cherry-pick] Fix flaky ray nightly image test (#2493) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2511
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2513
- Add in-memory dataset size calculation to dataset statistics and hyperopt (#2509) by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2518
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2521
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2528
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2534
- Cherrypick: Cleanup: move to per-module loggers instead of the global logging object by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2539
- Update version to 0.6rc1. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2529
- Add resource isolation to 0.6 and fix merge conflicts by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2538
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2542
- More resource isolation cherrypicks by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2544
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2546
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2552
- Pin ray nightly version to avoid test failures related to TensorDType… by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2559
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2557
- Update version to 0.6. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2549
New Contributors
Congratulations to our new contributors!
- @Marvjowa made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2236
- @Dennis-Rall made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2192
- @abidwael made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2263
- @noahlh made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2284
- @jeffkinnison made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2316
- @andife made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2358
- @alberttorosyan made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2413
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.3...v0.6
Published by justinxzhao about 2 years ago
What's Changed
- [release-0.6] Cherry-pick bugfixes from upstream by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2471
- [release-0.6] Cherry-pick upstream commits by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2473
- [release-0.6] Cherry-pick upstream by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2476
- Cherry-pick backwards-compatibility fixes by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2487
- [cherry-pick] Fixed usage of checkpoints for AutoML in Ray 2.0 (#2485) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2491
- fix: Automatically assign title to OneOfOptionsField (#2480) by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2492
- [cherry-pick] Fixed stratified splitting with Dask (#1883) by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2494
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2505
- AUTO: Enable hyperopt to be launched from a ray client by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2504
- [cherry-pick] Pin transformers < 4.22 until issues resolved (#2495) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2510
- [cherry-pick] Fix flaky ray nightly image test (#2493) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2511
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2513
- Add in-memory dataset size calculation to dataset statistics and hyperopt (#2509) by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2518
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2521
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2528
- AUTO: by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2534
- Cherrypick: Cleanup: move to per-module loggers instead of the global logging object by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2539
- Update version to 0.6rc1. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2529
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.6.beta...v0.6rc1
Published by justinxzhao about 2 years ago
What's Changed
- Fix ray nightly import by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2196
- Restructured split config and added datetime splitting by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2132
- enh: Implements
InferenceModuleas a pipelined module with separate preprocessor, predictor, and postprocessor modules by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2105 - Explicitly pass data credentials when reading binary files from a RayBackend by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2198
- MlflowCallback: do not end run on_trainer_train_teardown by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2201
- Fail hyperopt with full import error when Ray not installed by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2203
- Make convert_predictions() backend-aware by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2200
- feat: MVP for explanations using Integrated Gradients from captum by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2205
- [Torchscript] Adds GPU-enabled input types for Vector and Timeseries by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2197
- feat: Added model type GBM (LightGBM tree learner), as an alternative to ECD by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2027
- [Torchscript] Parallelized Text/Sequence Preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2206
- feat: Adding feature type shared parameter capability for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2133
- Bump up version to 0.6.dev. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2209
- Define
FloatOrAutoandIntegerOrAutoschema fields, and use them. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2219 - Define a dataclass for parameter metadata. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2218
- Add explicit handling for zero-length image byte buffers to avoid cryptic errors by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2210
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2231
- Create dataset util to form repeatable train/vali/test split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2159
- Bug fix: Use safe rename which works across filesystems when writing checkpoints by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2225
- Add parameter metadata to the trainer schema. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2224
- Add an explicit call to merge_wtih_defaults() when loading a config from a model directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2226
- Fixes flaky test test_datetime_split[dask] by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2232
- Fixes prediction saving for models with Set output by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2211
- Make ExpectedImpact JSON serializable by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2233
- standardised quotation marks, added missing word by @Marvjowa in https://github.com/ludwig-ai/ludwig/pull/2236
- Add boolean postprocessing to dataset type inference for automl by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2193
- Update get_repeatable_train_val_test_split to handle non-stratified split w/ no existing split by @amholler in https://github.com/ludwig-ai/ludwig/pull/2237
- Update R2 score to handle single sample computation by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2235
- Input/Output Feature Schema Refactor by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2147
- Fix nan in entmax loss and flaky sparsemax/entmax loss tests by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2238
- Fix preprocessing dataset split API backwards compatibility upgrade bug. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2239
- Removing duplicates in constants from recent PRs by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2240
- Add attention scores of the vit encoder as an additional return value by @Dennis-Rall in https://github.com/ludwig-ai/ludwig/pull/2192
- Unnest Audio Feature Preprocessing Config by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2242
- Fixed handling of invalud number values to treat as missing values by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2247
- Support saving numpy predictions to remote FS by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2245
- Use global constant for description.json by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2246
- Removed import warnings when LightGBM and Ray not requested by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2249
- Adds ability to read images from numpy files and numpy arrays by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2212
- Hyperopt steps per epoch not being computed correctly by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2175
- Fixed splitting when providing pre-split inputs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2248
- Added Backwards Compatibility for Audio Feature Preprocessing by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2254
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2256
- Fix: Don't skip saving the model if the save path already exists. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2264
- Load best weights outside of finally block, since load may throw an exception by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2268
- Reduce number of distributed tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2270
- [WIP] Adds
inference_utils.pyby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2213 - Run github checks for pushes and merges to *-stable. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2266
- Add ludwig logo and version to CLI help text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2258
- Add hyperopt_statistics.json constant by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2276
- fix: Make
BaseTrainerConfigan abstract class by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2273 - [Torchscript] Adds
--deviceargument toexport_torchscriptCLI command by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2275 - Use pytest tmpdir fixture wherever temporary directories are used in tests. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2274
- adding configs used in benchmarking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2263
- Fixes #2279 by @noahlh in https://github.com/ludwig-ai/ludwig/pull/2284
- adding hardware usage and software packages tracker by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2195
- benchmarking utils by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2260
- dataclasses for summarizing benchmarking results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2261
- Benchmarking core by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2262
- Fixed default eval_batch_size when setting batch_size=auto by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2286
- Remove obsolete postprocess_inference_graph function. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2267
- [Torchscript] Adds BERT tokenizer + partial HF tokenizer support by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2272
- Support passing ground_truth as df for visualizations by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2281
- catching urllib3 exception by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2294
- Run pytest workflow on release branches. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2291
- Save checkpoint if train_steps is smaller than batcher's steps_per_epoch by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2298
- Fix typo in amazon review datasets: s/review_tile/review_title by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2300
- Refactor non-distributed automl utils into a separate directory. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2296
- Don't skip normalization in TabNet during inference on a single row. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2299
- Fix error in postproc_predictions calculation in model.evaluate() by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2304
- Test for parameter updates in Ludwig components by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2194
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2311
- Use warnings to suppress repeated logs for failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2312
- Use ray dataset and drop type casting in binary_feature prediction post processing for speedup by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2293
- Add size_bytes to DatasetInfo and DataSource by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2306
- Fixes TensorDtype TypeError in Ray nightly by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2320
- Add configuration section for global feature parameters by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2208
- Ensures unit tests are deleting artifacts during teardown by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2310
- Fixes unit test that had empty Dask partitions after splitting by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2313
- Serve json numpy encoding by @jeffkinnison in https://github.com/ludwig-ai/ludwig/pull/2316
- fix: Mlflow config being injected in hyperopt config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2321
- Update tests that use preprocessing to match new defaults config structure by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2323
- Bump test timeout to 60 minutes by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2325
- Set a default value for size_bytes in DatasetInfo by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2331
- Pin nightly versions to fix CI by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2327
- Log number of failed image reads by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2317
- Add test with encoder dependencies for global defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2342
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2334
- Add wine quality notebook to demonstrate using config defaults by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2333
- fix: GBM tests failing after new release from upstream dependency by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2347
- fix: restore overwrite of eval_batch_size on GBM schema by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2345
- Removes empty partitions after dropping rows and splitting datasets by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2328
- fix: Properly serialize
ParameterMetadatato JSON by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2348 - Test for parameter updates in Ludwig Components - Part 2 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2252
- refactor: Replace bespoke marshmallow fields that accept multiple types with a new 'combinatorial'
OneOfFieldthat accepts other fields as arguments. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2285 - Use Ray Datasets to read binary files in parallel by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2241
- typos: Update README.md by @andife in https://github.com/ludwig-ai/ludwig/pull/2358
- Respect the resource requests in RayPredictor by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2359
- Resource tracker threading by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2352
- Allow writing init_config results to remote filesystems by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2364
- Fixed export_mlflow command to not assume an existing registered_model_name by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2369
- fix: Fixes to serialization, and update to allow set repo location. by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2367
- Add amazon employee access challenge kaggle dataset by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2349
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2362
- Wrap read of cached training set metadata in try/except for robustness by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2373
- Reduce dropout prob in test_conv1d_stack by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2380
- fever: change broken download links by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2381
- Add default split config by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2379
- Fix CI: Skip failing ray GBM tests by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2391
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2389
- Triton ensemble export by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2251
- Fix: Random dataset splitting with 0.0 probability for optional validation or test sets. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2382
- Print final training report as tabulated text. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2383
- Add Ray 2.0 to CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2337
- add GBM configs to benchmarking by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2395
- Optional artifact logging for MLFlow by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2255
- Simplify ludwig.benchmarking.benchmark API and add ludwig benchmark CLI by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2394
- rename kaggle_api_key to kaggle_key by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2384
- use new URL for yosemite dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2385
- Encoder refactor V2 by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2370
- re-enable GBM tests after new lightgbm-ray release by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2393
- Added option to log artifact location while creating mlflow experiment by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2397
- Treat dataset columns as object dtype during first pass of handle_missing_values by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2398
- fix: ParameterMetadata JSON serialization bug by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2399
- Adds registry to organize backward compatibility updates around versions and config sections by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2335
- Include split column in explanation df by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2405
- Fix AimCallback to model_name as Run.name by @alberttorosyan in https://github.com/ludwig-ai/ludwig/pull/2413
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2410
- Hotfix: features eligible for shared params hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2417
- Nest FC Params in Decoder by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2400
- Hyperopt Backwards Compatibility by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2419
- Investigating test_resnet_block_layer intermittent test failure by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2414
- fix: Remove duplicate option from
cell_typefield schema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2428 - Test for parameter updates in Ludwig Combiners - Part 3 by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2332
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2430
- Hotfix: Proc column missing in output feature schema by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2435
- Nest hyperopt parameters into decoder object by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2436
- Fix: Make the twitter bots modeling example runnable by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2433
- Add MLG-ULB creditcard fraud dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2425
- Bugfix: non-number inputs to GBM by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2418
- GBM: log intermediate progress by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2421
- Fix: Upgrade ludwig config before schema validation by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2441
- Log warning for calibration if validation set is trivially small by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2440
- Fixes calibration and adds example scripts by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2431
- Add medical no-show appointments dataset by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2387
- Added conditional check for UNK token insertion into category feature vocab by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2429
- Ensure synthetic dataset unit tests to clean up extra files. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2442
- Added feature specific parameter test for hyperopt by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2329
- Fixed version transformation to accept user configs without ludwig_version by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2424
- Fix mulitple partition predict by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2422
- Cache jsonschema validator to reduce memory pressure by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2444
- [tests] Added more explicit lifecycle management to Ray clusters during tests by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2447
- Fix: explicit keyword args for seaborn plot fn by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2454
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2453
- Extended hyperopt to support nested configuration block parameters by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2445
- Consolidate missing value strategy to only include bfill and ffill by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2457
- fix: Switched Learning Rate to NonNegativeFloat Field by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2446
- Support GitHub Codespaces by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2463
- Enh: quality-of-life improvements for
export_torchscriptby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2459 - Disables
batch_size: autofor CPU-only training by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2455 - buxfix: triton model version as a string by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2461
- Updating images to Ray 2.0.0 and CUDA 11.3 by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2390
- Loss, Split, and Defaults Schema Additions by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2439
- More precise resource usage tracking by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2363
- Summarizing performance metrics and resource usage results by @abidwael in https://github.com/ludwig-ai/ludwig/pull/2372
New Contributors
- @Marvjowa made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2236
- @Dennis-Rall made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2192
- @abidwael made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2263
- @noahlh made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2284
- @jeffkinnison made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2316
- @andife made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2358
- @alberttorosyan made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2413
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.3...v0.6.beta
Published by arnavgarg1 about 2 years ago
What's Changed
- Bump Ludwig From v0.5.4 -> v0.5.5 by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2340
- Bug fix: Use safe rename which works across filesystems when writing checkpoints
- Fixed default eval_batch_size when setting batch_size=auto
- Update R2 score to handle single sample computation
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.4...v0.5.5
Published by justinxzhao over 2 years ago
What's Changed
- Cherrypick fixes to 0.5 by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2257
- Update ludwig version to v0.5.4. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2265
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.3...v0.5.4
Published by justinxzhao over 2 years ago
What's Changed
- Changed CheckpointManager to write the latest checkpoint to a consistent filename by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2123
- fix: restore existing credentials when exiting use_credentials context manager by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2112
- Torchscript-compatible TabNet by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2126
- Add tests to ensure optional imports are optional by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2116
- Added ray 1.13.0 and nightly wheel tests to CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2128
- fix: Add
defaultto top level ofNumericOrStringOptionsschema by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2119 - Comprehensive configs for trainer and combiner. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2118
- Set saved_weights_in_checkpoint immediately after creating model. Also adds test. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2131
- Fix Torchscript for exclusively binary feature inputs by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2103
- Fixes NaN handling in boolean dtypes by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2058
- [pre-commit.ci] pre-commit suggestions by @pre-commit-ci in https://github.com/ludwig-ai/ludwig/pull/2135
- Parallelizes URL reads for images using Ray/Multithreading by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2048
- Fixes dtype of SPLIT column if already provided in CSV by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2140
- Fixes FILL_WITH_MEAN missing value strategy with appropriate cast by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2141
- Remove
tune_batch_sizefrom tabnet config by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2145 - Accept kwargs in read_xsv by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2151
- Remove all torch packages from the nightly test requirements by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2157
- [Torchscript] Add Set output feature by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2161
- Cleaning hyperopt logging by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2162
- enh: Aim experient tracking for Ludwig by @osoblanco in https://github.com/ludwig-ai/ludwig/pull/2097
- Update to packaging version instead of LooseVersion by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2173
- rmspe: add epsilon to avoid division by zero by @jppgks in https://github.com/ludwig-ai/ludwig/pull/2139
- Fix creating tensor from copy of numpy array warning messages by @arnavgarg1 in https://github.com/ludwig-ai/ludwig/pull/2170
- [Torchscript] Add Vector preprocessing and postprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2160
- [Torchscript] Add H3 preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2164
- Expose dtype as a parameter of the read_xsv function instead of a purely hardcoded value by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2177
- [Torchscript] Adds Sequence and Text feature postprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2163
- [Torchscript] Add Date feature preprocessing by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2178
- Added flag for writing per trial logs in hyperopt by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2149
- Replace ray.state.nodes() with ray.nodes(). by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2183
- HYPEROPT: Migrate Sampler functionality to Executor by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2165
- Changes for enabling checkpoint syncing for hyperopt by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2115
- Adds mechanism for calibrating probabilities for category and binary features by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/1949
- fix: Set divisions for proc_cols directly from original dataset by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2187
- Avoid unneeded total_entropy calculation when sparsity=0 by @amholler in https://github.com/ludwig-ai/ludwig/pull/2190
- Fix changing parameters on plateau. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2191
- [Torchscript] Adds NaN handling to preprocessing modules by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2179
- Fix postprocessing on binary feature columns with number dtype by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2189
- automl: Use auto batch size by default with tabnet by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2150
- Update ludwig version to v0.5.3. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2184
New Contributors
- @arnavgarg1 made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2162
- @osoblanco made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2097
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.2...v0.5.3
Published by justinxzhao over 2 years ago
What's Changed
- Addresses
SettingWithCopyWarninginread_csv_with_nanby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2053 - Update AutoML to check for imbalanced binary or category output features by @amholler in https://github.com/ludwig-ai/ludwig/pull/2052
- fix: Pin
jsonschemarequirement by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2059 - fix: Adjust custom JSON schema for
betasfield on optimizers by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2056 - Use the smaller, unanimated GIF version so that it loads properly in PyPi by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2063
- Make text encoder trainable property default to False for pre-trained HF encoders by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2060
- Pin protobuf to 3.20.1 to workaround FieldDescriptor error by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2062
- Use the smaller, unanimated GIF version so that it loads properly in PyPI by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2064
- Factor pytorch device setting code by @amholler in https://github.com/ludwig-ai/ludwig/pull/2068
- fix: pin protobuf to 3.20.1 in tests by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/2070
- Update torch nightly and pin torchvision to fix CI by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2072
- Added explicit encode, combine, decode functions to ECD by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2073
- Revert "Adds rule of thumb for determining embeddings size" by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2069
- Unpin torchvision by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2077
- Restrict torchmetrics<0.9 and whylogs<1.0 until compatibility fixed by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2079
- Adding new export for Triton by @brightsparc in https://github.com/ludwig-ai/ludwig/pull/2078
- Adds step tracking at epoch level by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2081
- Fix ray hyperopt by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/1999
- Adds regression test for #2081 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2084
- Complete PR comments for hyperopt refactoring by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2082
- Parallelizes URL reads using Ray / Multithreading by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2040
- Set Hyperopt Executor Type default to RAY by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/2093
- Fixes shape issue in
_BinaryPostprocessingby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2094 - Rename
sequence_size->max_sequence_lengthby @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2086 - Fix type hints for dropout, dropout parameter references, and add docs for FCLayer and FCStack. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2061
- Fix to_numpy_dataset() for Dask series by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2095
- Add DATA_TRAIN_HDF5_FP in training_set_metadata for ParquetPreprocessor by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2096
- Adds torchscript-compatible Audio input feature by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/1980
- Fix progress bar ray by @magdyksaleh in https://github.com/ludwig-ai/ludwig/pull/2051
- Fixes binary feature postprocessing upcast by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2101
- Fixes for large scale hyperopt by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/2083
- Changes batch norm momentum defaults to 1-momentum by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2100
- Add imbalanced tabular dataset for developing AutoML heuristics by @amholler in https://github.com/ludwig-ai/ludwig/pull/2106
- Deflakes and refactors torchscript tests by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2109
- Fixed combiner schema creation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2114
- Added ability to stop and resume hyperopt / automl runs by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2108
- Use the Backend to check for dask dataframes, instead of a hard check. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2113
- Rename 'bias' to 'use_bias' for consistency by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/2104
- Update ludwig version to v0.5.2. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2098
New Contributors
- @magdyksaleh made their first contribution in https://github.com/ludwig-ai/ludwig/pull/2051
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5.1...v0.5.2
Published by justinxzhao over 2 years ago
What's Changed
- refactor: Rename, reorganize schema module by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/1963
- Fix redundant import by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2019
- fix: Various marshmallow improvements. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/1975
- fixes nans in dask df engine by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2020
- Adds regression tests for #2020 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2021
- Removes pinned torchtext and torch for windows. by @dantreiman in https://github.com/ludwig-ai/ludwig/pull/1998
- Add AutoML inference for audio by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2023
- Added support for batch size and learning rate tuning using Ray backend by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2024
- Added split column for a deterministic output so flakes stop by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2028
- Workaround test_tune_batch_size_lr flakiness by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2030
- Fixed ordering of imports for comet test by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2031
- Adds regression tests for #2007 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2018
- Improve performance of
DataFrameEngine.df_likeby @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2029 - Fixed infinite loop in tune_batch_size by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2034
- Fixed learning rate tuning on gpu by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/2035
- Fix SIGINT handler to modify the number of remaining training steps. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/2032
- upgrade: Update jsonschema validator to latest spec. by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/2036
- Bumps py3.7 Ray version to 1.12.0 by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2041
- Added blocking warning for experiment CLI, and visual warning for tra… by @connor-mccorm in https://github.com/ludwig-ai/ludwig/pull/2043
- Adds ability to export scripted ECD model without pre-/post- processing modules by @geoffreyangus in https://github.com/ludwig-ai/ludwig/pull/2042
- Convert nan to 0 in avg_num_tokens() by @hungcs in https://github.com/ludwig-ai/ludwig/pull/2046
- Fixing the trainable parameter in pretrained encoders by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/2047
- Fixes trainability of sparse embeddings by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/2049
- Adds rule of thumb for determining embeddings size by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/2050
- Refactor HyperOpt to use RayTune by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/1994
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.5...v0.5.1
Published by justinxzhao over 2 years ago
Ludwig v0.5 is a complete renovation of Ludwig from the ground up with a focus on parity, scalability, deployment, reliability, and documentation. Ludwig v0.5 migrates our entire backend from TensorFlow to PyTorch and introduces several new features and technical improvements, including:
- Step-based training and evaluation to enable frequent sub-epoch monitoring of model health and evaluation metrics. This is particularly useful for large datasets that may be trained using large models.
- Data balancing: upsampling and downsampling during preprocessing to better proportioned datasets.
- End-to-end torchscript to support low-level optimized model deployment, including preprocessing and post-processing, to go directly from example to predictions.
- Ludwig on Ray with RayDatasets enabling significant training speed boosts for reading large datasets while training Ludwig models on a Ray cluster.
- The addition of MLPMixer and ViTEncoder as image encoders for state-of-the-art deep learning on image data.
- AutoML for tabular and text classification, integrated with distributed hyperparameter search using RayTune.
- Scalability optimizations with Dask, Modin, and Ray, enabling Ludwig to preprocess, train, and evaluate over datasets hundreds of gigabytes in size in tens of minutes.
- Config validation using marshmallow schemas revealing configuration typos or bad values early and increasing reliability.
- More tests. We've quadrupled the number of unit tests and end-to-end integration tests and we've expanded our CI testing to run in distributed and GPU settings. This strengthens Ludwig's stability and helps build confidence in new changes going forward.
Our team is thoroughly invested in improving the declarative ML experience, and, as part of the v0.5 release, we've revamped the getting started guide, user guide, and developer documentation. We've also published a handful of end-to-end tutorials with thoroughly documented notebooks on text, tabular, image, and multimodal classification that provide a deep walkthrough of Ludwig's functionality.
Migrating to PyTorch
Ludwig's migration to PyTorch comes from a substantial 6 month undertaking involving 230+ commits, changes to 70k+ lines of code, and contributions from 40+ people.
PyTorch's pythonic design and emphasis on developer experience are well-aligned with Ludwig's principles of simplicity, modularity, and extensibility. Switching to use PyTorch as Ludwig’s backend of choice was strongly motivated by the increase in productivity in development, debugging, and iteration that the more pythonic PyTorch API affords us as well as the great ecosystem the PyTorch community has built around it. With Ludwig on PyTorch, we're thrilled to see what developers, researchers, and data scientists in the PyTorch and broader deep learning community can bring to Ludwig.
Feature and Performance Parity
Over the last several months, we've moved all Ludwig encoders, combiners, decoders, and metrics for every data modality that Ludwig supports, as well as all of the backend infrastructure on Horovod and Ray, to PyTorch.
At the same time, we wanted to make sure that the experience of Ludwig users continues to be performant and delightful. We've run extensive comparisons between Ludwig v0.5 (PyTorch-based) and Ludwig v0.4 on text, image, and tabular datasets, evaluating training speed, inference throughput, and model performance, to verify that there's been no degradation.
Our results reveal roughly the same high GPU utilization (~90%) on several datasets with significant improvements in distributed training speed and memory usage without impacting model accuracy nor time to convergence. We'll be publishing a blog with more details on benchmarking soon.
New Features
In addition to the PyTorch migration, Ludwig v0.5 is packed with new functionality, features, and additional changes that make v0.5 the most feature-rich and robust release of Ludwig yet.
Step-based training and evaluation
Ludwig's train loop is epoch-based by default, with one round of evaluation per epoch (one pass through the dataset).
for epoch in num_epochs:
for batch in training_data.batches:
train(batch)
save_model(model_dir)
evaluation(training_data)
evaluation(validation_data)
evaluation(test_data)
print_results()
This is an appropriate fit for tabular datasets, which are small, fit in memory, and train quickly. However, this can be awkward for unstructured datasets, which tend to be much larger, and train more slowly due to larger models. Now, with step-based training and evaluation, users can configure a more frequent sub-epoch evaluation cadence to more regularly monitor metrics and model health.
Use steps_per_checkpoint to run evaluation every N training steps, or checkpoints_per_epoch to run evaluation N times per epoch.
trainer:
steps_per_checkpoint: 1000
trainer:
checkpoints_per_epoch: 2
Note that it is invalid to specify both checkpoints_per_epoch and steps_per_checkpoint simultaneously.
To further speed up evaluation, users can skip evaluation on the training set by setting evaluate_training_set to False.
trainer:
evaluate_training_set: false
Data balancing
Users working with imbalanced datasets can specify an oversampling or undersampling parameter which will balance the data during preprocessing.
In this example, Ludwig will oversample the minority class to achieve a 50% representation in the overall dataset.
preprocessing:
oversample_minority: 0.5
In this example, Ludwig will undersample the majority class to achieve a 70% representation in the overall dataset.
preprocessing:
undersample_majority: 0.7
Data balancing is only supported for binary output classes. Specifying both parameters at the same time is also not supported.
When developing models, it can be useful to iterate quickly with a smaller portion of the dataset. Ludwig supports this with a new preprocessing parameter, sample_ratio, which subsamples the dataset.
preprocessing:
sample_ratio: 0.7
End-to-end torchscript
Users can export trained ludwig models to torchscript with ludwig export_torchscript.
ludwig export_torchscript –model=/path/to/model
Models that use number, category, and text binary features now support torchscript-compatible preprocessing, enabling end-to-end torchscript compilation.
inputs = {
'cat_feature': ['foo', 'bar']
'num_feature': torch.tensor([42, 7])
'bin_feature1': torch.tensor([True, False])
'bin_feature2': ['No', 'Yes']
}
scripted_model = model.to_torchscript()
output = scripted_model(inputs)
End to end torchscript compilation is also supported for text features that use torchscript-enabled torchtext tokenizers. We are actively working on adding support for other data types.
AutoML for Text Classification
In v0.4, we introduced experimental AutoML functionalities into Ludwig.
Ludwig AutoML automatically creates deep learning models given a dataset, its label column, and a time budget. Ludwig AutoML infers the input and output feature types, chooses the model architecture, and specifies the parameters and ranges across which to perform hyperparameter search.
auto_train_results = ludwig.automl.auto_train(
dataset=my_dataset_df,
target=target_column_name,
time_limit_s=7200,
tune_for_memory=False
)
Our initial AutoML work focused on tabular datasets, since good performance on such datasets is a current area of interest in the DL community. In v0.5, we expand on this work to develop and validate Ludwig AutoML for text classification.
Config validation against Marshmallow Schemas
The combiner and trainer sections of Ludwig configurations are now validated against official Marshmallow schemas. This centralizes documentation, flags configuration typos or bad values, and helps catch regressions.
Better Test Coverage
We've quadrupled the number of unit and integration tests and we've established new testing guidelines for well-tested contributions going forward. This strengthens Ludwig's stability, iterability, and helps build confidence in new changes.
Backward Compatibility
Despite all of the code changes, we've worked hard to ensure that Ludwig’s simple interface remains consistent and compatible with earlier releases as much as possible. A few minor parameter naming changes in the Ludwig configuration to be aware of:
-
training->trainer -
numeric->number -
fc_size->output_size -
tied_weights->tied - deleted
{weight/bias/activation}_regularizer-> A globalregularization_lambdaandregularization_typeis used to control regularization across the entire model. - delete
dropout: True/False->dropout is float [0,1]
Finally, we've dropped support for Python 3.6. Please use Python 3.7 going forward.
New Contributors
- @vreyespue made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1213
- @Yard1 made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1277
- @EnricoMi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1442
- @q0w made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1512
- @kriziacicchetti made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1525
- @RebSolcia made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1526
- @noyoshi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1540
- @louixs made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1552
- @dantreiman made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1576
- @pre-commit-ci made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1595
- @connor-mccorm made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1699
- @hfurkanbozkurt made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1734
- @brightsparc made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1830
- @tirkarthi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1838
- @jeffreykennethli made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1856
- @rk0n made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1864
- @geoffreyangus made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1882
- @jppgks made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1959
Published by justinxzhao over 2 years ago
Fixes loss reporting consistency issues, and shape-based metric calculation errors with SET output features.
Published by ShreyaR over 2 years ago
Migration to PyTorch.
Published by justinxzhao over 2 years ago
Summary
This release features experimental AutoML with auto config generation and auto-training integrated with hyperopt on RayTune, and integrations with Ray training and Ray datasets. We're still working on a comprehensive overhaul of the documentation, and all the new functionality will all available in the upcoming v0.5 too.
Aside from critical bugs and new datasets, v0.4.1 will be the last release of Ludwig using TensorFlow. Starting with v0.5+ (release coming soon), Ludwig will use PyTorch as the backend for tensor computation. We will release a blogpost detailing the rationale and impact of this decision, but we wanted to do one last TensorFlow release to make sure that all those committed to a TensorFlow ecosystem that have used Ludwig so far could enjoy the benefits of many bug fixes and improvements we did on the codebase that were not specific to PyTorch.
The next version v0.5 will also have several additional improvements that we’ll be excited to share in the coming weeks.
Additions
- Non-absolute image path support by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1224
- Add image dim inference to schema by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1225
- Additional Tabular Datasets by @amholler (#1226, #1230, #1237)
- Initial implementation of the end-to-end autotrain module by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1219
- [automl] AutoML Extended public API by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1235
- Add image dimension inference to automl by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1243
- [automl] Memory Aware Config Tuning by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1257
- Added DataFrame wrapper type and fixed usage of optional imports by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1371
- Added Dask kwargs to Ray backend by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1380
- Configure Dask to determine parallelism automatically by default by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1383
- Add Ray backend to Ray hyperopt by @Yard1 in https://github.com/ludwig-ai/ludwig/pull/1269
- Add additional hyperopt callbacks by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1388
- Added preprocessing callbacks by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1398
- Added Slack and Twitter badges by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1399
- Add support for Ray Train and Ray Datasets in training by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1391
- Add combiner schema validation by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/1347
- Publish unit test results by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1414
- Publish test results for fork repos as well by @EnricoMi in https://github.com/ludwig-ai/ludwig/pull/1442
- Build docker images for tf-legacy by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1504
- Added init_config and render_config command-line utils (#1506) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1514
- Add experiment heuristics to automl module (variant of Avanika PR 1362) by @amholler in https://github.com/ludwig-ai/ludwig/pull/1507
- Add random_seed to auto_train API to improve repeatability by @amholler in https://github.com/ludwig-ai/ludwig/pull/1619
- Support use_reference_config option to AutoML to add initial trial from relevant best past model by @amholler in https://github.com/ludwig-ai/ludwig/pull/1636
- Add remote checkpoint support to ray tune post search evaluation by @amholler in https://github.com/ludwig-ai/ludwig/pull/1646
- [datasets] Add remote filesystem support to datasets module by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1244
- Add sample training by @amholler in https://github.com/ludwig-ai/ludwig/pull/1227
- Add support for Santander Customer Satisfaction dataset, along with s… by @amholler in https://github.com/ludwig-ai/ludwig/pull/1238
Improvements
- Allow logging params to mlflow from any epoch by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1211
- Changed remote fs behavior to upload at the end of each epoch by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1210
- Add metric and loss modules for RMSE, RMSPE, and AUC by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1214
- [hyperopt] fixed metric_score to use test split when available by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1239
- Fixed metric selection to ignore config split if unavailable by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1248
- Ray Tune Intermediate Checkpoint Cleaning by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1255
- Do not initialize Ray if already initalized by @Yard1 in https://github.com/ludwig-ai/ludwig/pull/1277
- Changed default combiner to concat from tabnet by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/1278
- Ray data migration by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/1260
- Fix automl to treat binary as categorical when missing values present by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1292
- Add serialization for DatasetInfo and round avg_words to int by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1294
- Cast
max_lengthto int inbuild_sequence_matrix::padby @Yard1 in https://github.com/ludwig-ai/ludwig/pull/1295 - [automl] update model config parameter ranges by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1298
- Change INFER_IMAGE_DIMENSIONS default to True by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1303
- Add HTTPS retries for image urls by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1304
- Return None for unreadable images and try to infer num channels by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1307
- Add gray image/avg image fallbacks for unreachable images by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1312
- Account for image extensions during image type inference by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1335
- Fixed schema validation to handle null preprocessing values for strings by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1344
- Added default size and output_size for tabnet by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1355
- Removed DaskBackend and moved tests to RayBackend by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1412
- Perform preprocessing first before hyperopt when possible by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1415
- Employ a fallback str2bool mapping from the feature column's distinct values when the feature's values aren't boolean-like. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/1471
- Remove trailing dot in income label field in adult_census… by @amholler in https://github.com/ludwig-ai/ludwig/pull/1475
- Update Ludwig AutoML Feature Type Selection by @amholler in https://github.com/ludwig-ai/ludwig/pull/1485
- Update infer_type tests to reflect interface and functionality updates by @amholler in https://github.com/ludwig-ai/ludwig/pull/1493
- Skip converting to TensorDType if the column is binary by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1547
- Remove TensorDType conversion for all scalar types by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1560
- Update AutoML tabular model type choice to remove heuristic for concat by @amholler in https://github.com/ludwig-ai/ludwig/pull/1548
- Better handle empty fields with distinct_values=[] by @hungcs in https://github.com/ludwig-ai/ludwig/pull/1574
- Port #1476 ('dict' option for weights_initializer and bias_initializer) to tf_legacy by @ksbrar in https://github.com/ludwig-ai/ludwig/pull/1599
- Modify combiners to accept input_features as a dict instead of a list by @jeffreyftang in https://github.com/ludwig-ai/ludwig/pull/1618
- Update hyperopt: Choose best model from validation data; For stopped Ray Tune trials, run evaluate at search end by @amholler in https://github.com/ludwig-ai/ludwig/pull/1612
- Keep search_alg type in dict to record in hyperopt_statistics.json by @amholler in https://github.com/ludwig-ai/ludwig/pull/1626
- For ames_housing, remove test.csv from processing; it has no label column which prevents test split eval by @amholler in https://github.com/ludwig-ai/ludwig/pull/1634
- Improve Ludwig resilience to Ray Tune issues by @amholler in https://github.com/ludwig-ai/ludwig/pull/1660
- Handle download gzip files by @amholler in https://github.com/ludwig-ai/ludwig/pull/1676
- Upgrade tf from 2.5.2 to 2.7.0. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/1713
- Add basic precommit to tf-legacy to pass precommit checks on tf-legacy PRs. by @justinxzhao in https://github.com/ludwig-ai/ludwig/pull/1718
- For kdd datasets, do not include unlabeled test data by default by @amholler in https://github.com/ludwig-ai/ludwig/pull/1704
- Use config which has been previously validated by @vreyespue in https://github.com/ludwig-ai/ludwig/pull/1213
- Update Readme to activate directly the virtualenv by @vreyespue in https://github.com/ludwig-ai/ludwig/pull/1212
- doc: Correct README.md link to Developer Guide by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/1217
- Update pandas version by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/1223
- Modify Kaggle datasets to not process test sets by @ANarayan in https://github.com/ludwig-ai/ludwig/pull/1233
- Restructure dataframe preprocessing setup and change to avoid creatin… by @amholler in https://github.com/ludwig-ai/ludwig/pull/1240
Bug fixes
- Fixed Keras imports by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/1215
- Fix assert in tabnet to be tf assert_rank by @w4nderlust in https://github.com/ludwig-ai/ludwig/pull/1222
- Fixed read_csv for Dask by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1247
- Fix TensorFlow CUDA version mismatch in Ray GPU image by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1256
- Fix excluded field detection by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1285
- Fixed automl to work when combiner is not specified by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1293
- FIX: Issue 1181 resolves the ZeroDivisionError when calculating sample variance by @jimthompson5802 in https://github.com/ludwig-ai/ludwig/pull/1326
- Fixed steps_per_epoch to be computed on batch resizing by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1402
- Fix evaluation and visualization of confusion_matrix by @carlogrisetti in https://github.com/ludwig-ai/ludwig/pull/1408
- Fixed auto eval batch size when train batch size is set by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1410
- Fixed gpu isolation by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1455
- Address issues in AutoML managing time-budget while exploring trial space by @amholler in https://github.com/ludwig-ai/ludwig/pull/1535
- Fixed RayDatasets by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1565
- Fix makedirs call to path_exists to pass url by @amholler in https://github.com/ludwig-ai/ludwig/pull/1592
- Fixed KeyError while creating default config (#1643) by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1654
- Fix FileNotFoundError while caching when cache_dir is … by @ShreyaR in https://github.com/ludwig-ai/ludwig/pull/1665
- Fixed TabNet conversion to TF graph with unknown batch size by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1252
Other changes and things to note
- Moved experiments to separate repo by @tgaddair in https://github.com/ludwig-ai/ludwig/pull/1245
- Neuropod does not yet support python 3.9. Ludwig still supports neuropod for python<=3.8.
New Contributors
- @vreyespue made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1213
- @Yard1 made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1277
- @EnricoMi made their first contribution in https://github.com/ludwig-ai/ludwig/pull/1442
Full Changelog: https://github.com/ludwig-ai/ludwig/compare/v0.4...v0.4.1
Published by w4nderlust over 3 years ago
Changelog
Additions
- Integrate ray tune into hyperopt (#1001)
- Added Ames Housing Kaggle dataset (#1098)
- Added functionality to obtain subtrees in the SST dataset (#1108)
- Added comparator combiner (#1113)
- Additional Text Classification Datasets (#1121)
- Added Ray remote backend and Dask distributed preprocessing (#1090)
- Added TabNet combiner and needed modules (#1062)
- Added Higgs Boson dataset (#1157)
- Added GitHub workflow to push to Docker Hub (#1160)
- Added more tagging schemes for Docker images (#1161)
- Added Docker build matrix (#1162)
- Added category feature > 1 dim to TabNet (#1150)
- Added timeseries datasets (#1149)
- Add TabNet Datasets (#1153)
- Forest Cover Type, Adult Census Income and Rossmann Store Sales datasets (#1165)
- Added KDD Cup 2009 datasets (#1167)
- Added Ray GPU image (#1170)
- Added support for cloud object storage (S3, GCS, ADLS, etc.) (#1164)
- Perform inference with Dask when using the Ray backend (#1128)
- Added schema validation to config files (#1186)
- Added MLflow experiment tracking support (#1191)
- Added export to MLflow pyfunc model format (#1192)
- Added MLP-Mixer image encoder (#1178)
- Added TransformerCombiner (#1177)
- Added TFRecord support as a preprocessing cache format (#1194)
- Added higgs boson tabnet examples (#1209)
Improvements
- Abstracted Horovod params into the Backend API (#1080)
- Added allowed_origins to serving to support to allow cross-origin requests (#1091)
- Added callbacks to hook into the training loop programmatically (#1094)
- Added scheduler support to Ray Tune hyperopt and fixed GPU usage (#1088)
- Ray Tune: enforced that epochs equals max_t and early stopping is disabled (#1109)
- Added register_trainable logic to RayTuneExecutor (#1117)
- Replaced Travis CI with GitHub Actions (#1120)
- Split distributed tests into separate test suite (#1126)
- Removed unused regularizer parameter from training defaults
- Restrict docker built GA to only ludwig-ai repos (#1166)
- Harmonize return object for categorical, sequence generator and sequence tagger (#1171)
- Sourcing images from either file path or in-memory ndarrays (#1174)
- Refactored hyperopt results into object structure for easier programmatic usage (#1184)
- Refactored all contrib classes to use the Callback interface (#1187)
- Improved performance of Dask preprocessing by adding parallelism (#1193)
- Improved TabNetCombiner and Concat combiner (#1177)
- Added additional backend configuration options (#1195)
- Made should_shuffle configurable in Trainer (#1198)
Bugfixes
- Fix SST parentheses issue
- Fix serve.py adding a try around the form parsing (#1111)
- Fix #1104: add lengths to text encoder output with updated unit test (#1105)
- Fix sst2 substree logic to match glue sst2 dataset (#1112)
- Fix #1078: Avoid recreating cache when using image preproc (#1114)
- Fix checking is dask exists in figure_data_format_dataset
- Fixed bug in EthosBinary dataset class and model directory copying logic in RayTuneReportCallback (#1129)
- Fix #1070: error when saving model with image feature (#1119)
- Fixed IterableBatcher incompatibility with ParquetDataset and remote model serialization (#1138)
- Fix: passing backend and TF config parameters to model load path in experiment
- Fix: improved TabNet numerical stability + refactoring
- Fix #1147: passing bn_epsilon to AttentiveTransformer initialization in TabNet
- Fix #1093: loss value mismatch (#1103)
- Fixed CacheManager to correctly handle test_set and validation_set (#1189)
- Fixing TabNet sparsity loss issue (#1199)
Breaking changes
Most models trained with v0.3.3 would keep working in v0.4.
The main changes in v0.4 are additional options, so what worked previously should not be broken now.
One exception to this is that now there is a much strictier check of the validity of the model configuration.
This is great as it allows to catch errors earlier, although configurations that despite errors worked in the past may not work anymore.
The checks should help identify the issues in the configurations though, so errors should be easily ficable.
Contributors
@tgaddair @jimthompson5802 @ANarayan @kaushikb11 @mejackreed @ronaldyang @zhisbug @nimz @kanishk16

