
featureform
The Virtual Feature Store. Turn your existing data infrastructure into a feature store.
MPL-2.0 License
Bot releases are visible (Hide)
Published by sdreyer 8 months ago
What's Changed
- Feature: Clickhouse offline store support (#1224) by @ahmadnazeri in https://github.com/featureform/featureform/pull/1232
- Feature (Timestamp Variants) Turn on by default by @aolfat in https://github.com/featureform/featureform/pull/1176
- Upgrade pandas to >=1.3.5 by @epps in https://github.com/featureform/featureform/pull/1175
- Optional inference store for features by @aolfat in https://github.com/featureform/featureform/pull/1178
- Adding support for users to deploy Featureform on docker via cli. by @ahmadnazeri in https://github.com/featureform/featureform/pull/962
- Truncate long form errors by @anthonylasso in https://github.com/featureform/featureform/pull/1205
- Register features in batch by @RiddhiBagadiaa in https://github.com/featureform/featureform/pull/1195
- Searchable Tags by @ihkap11 in https://github.com/featureform/featureform/pull/1167
- Inputs for SQL Transformations by @aolfat in https://github.com/featureform/featureform/pull/1233
- Support for Resource Location by @ahmadnazeri in https://github.com/featureform/featureform/pull/1262
- Remove local mode from main package by @ahmadnazeri in https://github.com/featureform/featureform/pull/1294
Bugfixes
- Increase GRPC Stream Timeout by @sdreyer in https://github.com/featureform/featureform/pull/1190
- Client-side gRC Configuration for Long-running jobs by @epps in https://github.com/featureform/featureform/pull/1192
- Write Spark Submit Params to File Store to Avoid Databricks API 10K-byte Limit by @epps in https://github.com/featureform/featureform/pull/1197
- Helm Install-Upgrade ETCD fix. by @anthonylasso in https://github.com/featureform/featureform/pull/1220
- MD5 Hash of
offline_store_spark_runner.pyby @epps in https://github.com/featureform/featureform/pull/1213 - Bug: Healthy Providers Aren't Rechecked When Reapplied by @epps in https://github.com/featureform/featureform/pull/1231
- Fix banner reload issue by @anthonylasso in https://github.com/featureform/featureform/pull/1300
- Redshift Configuration Correction by @epps in https://github.com/featureform/featureform/pull/1307
- Source Modal Null Rows Fix by @anthonylasso in https://github.com/featureform/featureform/pull/1306
-
get_dynamodbmethod by @epps in https://github.com/featureform/featureform/pull/1309 - Add missing HDFS switch case by @anthonylasso in https://github.com/featureform/featureform/pull/1311
- Adds variant to materialization IDs for SQL providers by @epps in https://github.com/featureform/featureform/pull/1313
- Check other definition for cast before calling .Query on it by @aolfat in https://github.com/featureform/featureform/pull/1321
- Make ondemand feature be allowed to passed into as an object by @aolfat in https://github.com/featureform/featureform/pull/1312
Full Changelog: https://github.com/featureform/featureform/compare/v0.11.0...v0.12.0
Published by sdreyer 11 months ago
What's Changed
New Features
- Provider Health Checks by @epps in https://github.com/featureform/featureform/pull/1085
- Ability To Preview Feature Data by @anthonylasso in https://github.com/featureform/featureform/pull/1129
- Batch Serving (Snowflake) by @RiddhiBagadiaa in https://github.com/featureform/featureform/pull/1158
- Batch Serving (Spark) by @RiddhiBagadiaa in https://github.com/featureform/featureform/pull/1174
- Ondemand Feature Code Previews In Dashboard by @anthonylasso in https://github.com/featureform/featureform/pull/1169
- Materialization via S3 Import to DynamoDB by @epps in https://github.com/featureform/featureform/pull/1161
- Ability to Copy Name Variant to Clipboard by @anthonylasso in https://github.com/featureform/featureform/pull/1163
- Ability to Get Spark Dataframes For Training Sets by @ahmadnazeri in https://github.com/featureform/featureform/pull/1121
- Ability to See Lineage of Transformations in the Dashboard by @anthonylasso in https://github.com/featureform/featureform/pull/1096
Quality of Life
- Improved caching for docker rebuilds by @sdreyer in https://github.com/featureform/featureform/pull/1043
- Dynamically set dashboard table sizes by @anthonylasso in https://github.com/featureform/featureform/pull/1030
- Databricks/client creds input validation by @ihkap11 in https://github.com/featureform/featureform/pull/1149
Bugfixes
- Ensure each transformation function argument has an input by @aolfat in https://github.com/featureform/featureform/pull/1018
- Fix state error for resource redefined error by @aolfat in https://github.com/featureform/featureform/pull/1032
- Issue with source not retrieving any source by @ahmadnazeri in https://github.com/featureform/featureform/pull/1034
- Refresh and Loading fix by @anthonylasso in https://github.com/featureform/featureform/pull/1039
- Add resource type in title. by @anthonylasso in https://github.com/featureform/featureform/pull/1024
- Fixed Conditional that added duplicate feature by @sdreyer in https://github.com/featureform/featureform/pull/1062
- Docs Parsing error by @joshcolts18 in https://github.com/featureform/featureform/pull/1090
- Materialization Copy Performance Improvement by @epps in https://github.com/featureform/featureform/pull/1079
- Slow search results loading state by @anthonylasso in https://github.com/featureform/featureform/pull/1088
- Flask compatibility with python 3.7 by @sdreyer in https://github.com/featureform/featureform/pull/1111
- Materialize Copy Race Condition by @epps in https://github.com/featureform/featureform/pull/1113
- Increasing Timeout For Long Running Jobs by @ahmadnazeri in https://github.com/featureform/featureform/pull/1118
New Contributors
- @jerempy made their first contribution in https://github.com/featureform/featureform/pull/1074
- @joshcolts18 made their first contribution in https://github.com/featureform/featureform/pull/1090
- @syedzubeen made their first contribution in https://github.com/featureform/featureform/pull/1119
- @ihkap11 made their first contribution in https://github.com/featureform/featureform/pull/1149
Full Changelog: https://github.com/featureform/featureform/compare/v0.10.3...v0.11.0
Published by sdreyer about 1 year ago
What's Changed
- Hotfix/pinecone casting by @sdreyer in https://github.com/featureform/featureform/pull/917
- Bump grpcio from 1.51.1 to 1.53.0 by @dependabot in https://github.com/featureform/featureform/pull/908
- Unit tests to cover the SQL format function by @anthonylasso in https://github.com/featureform/featureform/pull/918
- Fix table row sizing by @anthonylasso in https://github.com/featureform/featureform/pull/937
- Update CLI version output by @anthonylasso in https://github.com/featureform/featureform/pull/934
-
pytestCoverage by @epps in https://github.com/featureform/featureform/pull/940 - Bugfix: KCF doesn't read csv files feature registered on source by @aolfat in https://github.com/featureform/featureform/pull/943
- Update README.md by @sdreyer in https://github.com/featureform/featureform/pull/946
- Run coverage on main by @sdreyer in https://github.com/featureform/featureform/pull/950
- Setup code to enable unit-level metadata_server + provider tests. by @anthonylasso in https://github.com/featureform/featureform/pull/944
- Provider Config Testing #64 by @anthonylasso in https://github.com/featureform/featureform/pull/948
- KCF dockerfile image to 3.10 + use consistent dill versioning by @aolfat in https://github.com/featureform/featureform/pull/955
- "Get" Provider Testing by @anthonylasso in https://github.com/featureform/featureform/pull/954
- Dashboard metadata variant bugfix by @anthonylasso in https://github.com/featureform/featureform/pull/933
- Change Resource names to ResourceVariant by @aolfat in https://github.com/featureform/featureform/pull/941
- Register instantiate tests by @anthonylasso in https://github.com/featureform/featureform/pull/961
- Bugfix: Dataframe transformation by @anthonylasso in https://github.com/featureform/featureform/pull/926
- Spark Tests by @sdreyer in https://github.com/featureform/featureform/pull/958
- Tests/spark by @sdreyer in https://github.com/featureform/featureform/pull/965
- FEATURE: PostgreSQL: adding support for ssl mode by @ahmadnazeri in https://github.com/featureform/featureform/pull/964
- Fix ETCD issue #945 by @anthonylasso in https://github.com/featureform/featureform/pull/967
- Cloud Storage Pathing (Azure Blob Storage) by @epps in https://github.com/featureform/featureform/pull/947
Full Changelog: https://github.com/featureform/featureform/compare/v0.10.0...v0.10.1
Published by sdreyer over 1 year ago
What's Changed
V0.10 release brings:
- A brand-new Dashboard UI and enhanced functionality
- Vector database support in local and hosted mode for Weaviate and Pinecone
- API improvements for data science development
- Updated documentation and bugfixes
Dashboard Makeover and Upgrades
We're excited to bring you a more visually appealing Dashboard with new functionality for both users and administrators, including metadata management for resource tags, previewing transformation results, and clear visibility of transformation logic
Assign tags to resources directly through the dashboard UI
Edit Resource Metadata from the Dashboard
Preview datasets directly from the dashboard
Better formatting for Python and SQL transformations
Vector Database Support
You can now register Weaviate and Pinecone as providers!
API Improvements for Data Science Development
Read all files from a directory into a dataframe with ff.register_directory()
Inference Stores are now optional in Local Mode: if an inference store is not specified, it will default to local mode.
Bug Fixes
- Bugfix: Added error check for inputs list by @sdreyer in https://github.com/featureform/featureform/pull/878
- Bugfix: Fixed how state is cleared by @ahmadnazeri in https://github.com/featureform/featureform/pull/876
- Bugfix: Fixed lingering default variants by @ahmadnazeri in https://github.com/featureform/featureform/pull/879
- Bugfix: Allowed nearest() to accept a Feature object by @ahmadnazeri in https://github.com/featureform/featureform/pull/885
- Bugfix: Banner Color @RedLeader16 in https://github.com/featureform/featureform/pull/873
- Bugfix: Give meaningful error when resource not found by @ahmadnazeri in https://github.com/featureform/featureform/pull/883
- Bugfix: Fixed scheduling for KCF by @aolfat in https://github.com/featureform/featureform/pull/853
- Bugfix: Fixed missing weaviate provider config implementation by @epps in https://github.com/featureform/featureform/pull/899
- Bugfix: Removes Outdated logging package by @sdreyer in https://github.com/featureform/featureform/pull/913
Full Changelog: https://github.com/featureform/featureform/compare/v0.9.0...v0.10.0
Published by sdreyer over 1 year ago
What's New
Vector Database and Embedding Support
You can use Featureform to define and orchestrate data pipelines that generate embeddings. Featureform can write them into either Redis for nearest neighbor lookup. This also allows users to version, re-use, and manage embeddings declaratively.
Registering Redis for use as a Vector Store (it’s the same as registering it typically)
ff.register_redis(
name = "redis",
description = "Example inference store",
team = "Featureform",
host = "0.0.0.0",
port = 6379,
)
A Pipeline to Generate Embeddings from Text
docs = spark.register_file(...)
@spark.df_transform(
inputs=[docs],
)
def embed_docs():
docs[“embedding”] = docs[“text”].map(lambda txt: openai.Embedding.create(
model="text-embedding-ada-002",
input=txt,
)["data"]
return docs
Defining and Versioning an Embedding
@ff.entity
def Article:
embedding = ff.Embedding(embed_docs[[“id”, “embedding”]], dims=1024, vector_db=redis)
@ff.entity
class Article:
embedding = ff.Embedding(
embed_docs[["id", "embedding"]],
dims=1024,
variant="test-variant",
vector_db=redis,
)
Performing a Nearest Neighbor Lookup
client.Nearest(Article.embedding, “id_123”, 25)
Interact with Training Sets as Dataframes
You can already interact with sources as dataframes, this release adds the same functionality to training sets as well.
Interacting with a training set as Pandas
import featureform as ff
client = ff.Client(...)
df = client.training_set(“fraud”, “simple”).dataframe()
print(df.head())
Enhanced Scheduling across Offline Stores
Featureform supports Cron syntax for scheduling transformations to run. This release rebuffs this functionality to make it more stable and efficient, and also adds more verbose error messages.
A transformation that runs every hour on Snowflake
@snowflake.sql_transform(schedule=“0 * * * *”)
def avg_transaction_price()
return “SELECT user, AVG(price) FROM {{transaction}} GROUP BY user”
Run Pandas Transformations on K8s with S3
Featureform schedules and runs your transformations for you. We support running Pandas directly, Featureform spins up a Kubernetes job to run it. This isn’t a replacement for distributed processing frameworks like Spark (which we also support), but it’s a great option for teams that are already using Pandas for production.
Defining our Pandas on Kubernetes Provider
aws_creds = ff.AWSCredentials(
aws_access_key_id="<aws_access_key_id>",
aws_secret_access_key="<aws_secret_access_key>",
)
s3 = ff.register_s3(
name="s3",
credentials=aws_creds,
bucket_path="<s3_bucket_path>",
bucket_region="<s3_bucket_region>"
)
pandas_k8s = ff.register_k8s(
name="k8s",
description="Native featureform kubernetes compute",
store=s3,
team="featureform-team"
)
Registering a file in S3 and a Transformation on it
src = pandas_k8s.register_file(...)
@pandas_k8s.df_transform(inputs=[src])
def transform(src):
return src.groupby("CustomerID")["TransactionAmount"].mean()
Published by sdreyer over 1 year ago
What's Changed
New Functionality
- KCF/S3 Support by @ahmadnazeri in https://github.com/featureform/featureform/pull/786
Enhancements
- Updated Readme example to fix serving and use class api by @ahmadnazeri in https://github.com/featureform/featureform/pull/792
- Dashboard Routing and Build Optimizations by @RedLeader16 in https://github.com/featureform/featureform/pull/781
- Set Jobs Limit for scheduling by @aolfat in https://github.com/featureform/featureform/pull/794
- Reformat and cleanup status displayer by @aolfat in https://github.com/featureform/featureform/pull/782
- Bump pymdown-extensions from 9.9.2 to 10.0 by @dependabot in https://github.com/featureform/featureform/pull/804
Bug Fixes
- Bad pathing exception #769 by @RedLeader16 in https://github.com/featureform/featureform/pull/773
- Throw error if input tuple is not of type (str, str) by @ahmadnazeri in https://github.com/featureform/featureform/pull/780
- Fix issue with paths for the Spark files by @ahmadnazeri in https://github.com/featureform/featureform/pull/776
- Fix missing executor type in differing fields check for SparkProvider by @zhilingc in https://github.com/featureform/featureform/pull/789
- Add default username and password for etcd coordinator by @aolfat in https://github.com/featureform/featureform/pull/798
New Contributors
- @zhilingc made their first contribution in https://github.com/featureform/featureform/pull/789
Full Changelog: https://github.com/featureform/featureform/compare/v0.8.0...v0.8.1
Published by ahmadnazeri over 1 year ago
What's Changed
- Spark Enhancement: Yarn Support
- Pull source and transformation data to client
client = Client() # presumes $FEATUREFORM_HOST is set
client.apply(insecure=False) # `insecure=True` for Docker (Quickstart only)
# Primary source as a dataframe
transactions_df = client.dataframe(
transactions, limit=2
) # Using the ColumnSourceRegistrar instance directly with a limit of 2 rows
# SQL transformation source as dataframe
avg_user_transaction_df = client.dataframe(
"average_user_transaction", "quickstart"
) # Using the source name and variant without a limit, which fetches all rows
print(transactions_df.head())
"""
"transactionid" "customerid" "customerdob" "custlocation" "custaccountbalance" "transactionamount" "timestamp" "isfraud"
0 T1 C5841053 10/1/94 JAMSHEDPUR 17819.05 25.0 2022-04-09T11:33:09Z False
1 T2 C2142763 4/4/57 JHAJJAR 2270.69 27999.0 2022-03-27T01:04:21Z False
"""
- Added Ecommerce notebooks for Azure, AWS, GCP
- Docs: Updated custom resource docs and added docs for KCF
- Bugfix: Updated, more useful error messages
- Bugfix: Fixed resource search
- Bugfix: Fixed breadcrumb type and case error
- Bugfix: KCF Resource limits
- Bugfix: Fixed path for docker file and spark
- Bugfix: Dashboard routing and reload fix
- Bugfix: Spark databricks error message
Full Changelog: https://github.com/featureform/featureform/compare/v0.7.3...v0.8.0
Published by sdreyer over 1 year ago
What's Changed
- Class API Enhancement: Optional
timestamp_columnwhen registering features/labels - Docs: Update AWS Deployment to Cover changes to
eksctl - Python 3.11.2 Support
- Bugfix: Resource Status in CLI List Command
- Bugfix: Fixing spark issue with Spark chained transformation
- Bugfix: Issue with not allowing Python objects as input to DF Transformation
- Bugfix: Checks existence of training set features prior to creation
- Adding notebook links to docs
New Contributors
- @jmeisele made their first contribution in https://github.com/featureform/featureform/pull/727
Full Changelog: https://github.com/featureform/featureform/compare/v0.7.2...v0.7.3
Published by sdreyer over 1 year ago
What's Changed
- Misc QOL improvements for the client
Full Changelog: https://github.com/featureform/featureform/compare/v0.7.1...v0.7.2
Published by sdreyer over 1 year ago
What's Changed
- Bugfix for On demand feature status
Full Changelog: https://github.com/featureform/featureform/compare/v0.7.0...v0.7.1
Published by sdreyer over 1 year ago
Release 0.7
Define Feature and Labels with an ORM-style Syntax
Featureform has added a new way to define entities, features, and labels. This new API, which takes inspiration from Python ORMs, makes it easier for data scientists to define and manage their features and labels in code.
Example
transactions = postgres.register_table(
name="transactions",
table="Transactions", # This is the table's name in Postgres
)
@postgres.sql_transformation()
def average_user_transaction():
return "SELECT CustomerID as user_id, avg(TransactionAmount) " \
"as avg_transaction_amt from {{transactions.default}} GROUP BY user_id"
@ff.entity
class User:
avg_transactions = ff.Feature(
average_user_transaction[["user_id", "avg_transaction_amt"]],
type=ff.Float32,
inference_store=redis,
)
fraudulent = ff.Label(
transactions[["customerid", "isfraud"]], variant="quickstart", type=ff.Bool
)
ff.register_training_set(
"fraud_training",
label="fraudulent",
features=["avg_transactions"],
)
You can read more in the docs.
Compute features at serving time with on-demand features
A highly requested feature was to feature-ize incoming data at serving time. For example, you may have an on-demand feature that turns a user comment into an embedding, or one that processes an incoming image.
On-demand feature that turns a comment to an embedding at serving time
@ff.ondemand_feature
def text_to_embedding(serving_client, params, entities):
return bert_transform(params[“comment”])
You can learn more in the docs
Attach tags & user-defined values to Featureform resources like transformations, features, and labels.
All features, labels, transformations, and training sets now have a tags and properties argument. properties is a dict and tags is a list.
client.register_training_set(“CustomerLTV_Training”, “default”, label=”ltv”, features=[“f1”, “f2”], tags=[“revenue”], properties={“visibility”: “internal”})
You can read more in the docs.
Transformation and training set caching in local mode.
Featureform has a local mode that allows users to define, manage, and serve their features when working locally off their laptop. It doesn’t require anything to be deployed. It would historically re-generate training sets and features on each run, but with 0.7, we cache results by default to decrease iteration time.
A cleaner (and more colorful) CLI flow!

Full Changelog: https://github.com/featureform/featureform/compare/v0.6.4...v0.7.0
Published by sdreyer over 1 year ago
What's Changed
- Bugfix for headers not being fetched in Spark Dataframe transformations
Full Changelog: https://github.com/featureform/featureform/compare/v0.6.3...v0.6.4
Published by sdreyer over 1 year ago
What's Changed
- Added Search to the standalone docker container
- GCP Filestore bug fixes
Full Changelog: https://github.com/featureform/featureform/compare/v0.6.2...v0.6.3
Published by sdreyer over 1 year ago
What's Changed
- Bugfix for typeguard python package version
Full Changelog: https://github.com/featureform/featureform/compare/v0.6.1...v0.6.2
Published by sdreyer over 1 year ago
What's Changed
- Search Bugfix for Standalone Container
Full Changelog: https://github.com/featureform/featureform/compare/v0.6.0...v0.6.1
Published by sdreyer over 1 year ago
Release 0.6
Generic Spark support as a Provider
Featureform has had support for Spark on EMR and Spark on Databricks for a while. We’ve generalized our Spark implementation to handle all versions of Spark using any of S3, GCS, Azure Blob Store, or HDFS as a backing store!
Here are some examples:
Spark with GCS backend
spark_creds = ff.SparkCredentials(
master=master_ip_or_local,
deploy_mode="client",
python_version=cluster_py_version,
)
gcp_creds = ff.GCPCredentials(
project_id=project_id,
credentials_path=path_to_gcp_creds,
)
gcs = ff.register_gcs(
name=gcs_provider_name,
credentials=gcp_creds,
bucket_name=”bucket_name”,
bucket_path="directory/",
)
spark = ff.register_spark(
name=spark_provider_name,
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=gcs,
)
Databricks with Azure
databricks = ff.DatabricksCredentials(
host=host,
token=token,
cluster_id=cluster,
)
azure_blob = ff.register_blob_store(
name=”blob”,
account_name=os.getenv("AZURE_ACCOUNT_NAME", None),
account_key=os.getenv("AZURE_ACCOUNT_KEY", None),
container_name=os.getenv("AZURE_CONTAINER_NAME", None),
root_path="testing/ff",
)
spark = ff.register_spark(
name=”spark-databricks-azure”,
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=databricks,
filestore=azure_blob,
)
EMR with S3
spark_creds = ff.SparkCredentials(
master=master_ip_or_local,
deploy_mode="client",
python_version=cluster_py_version,
)
aws_creds = ff.AWSCredentials(
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID", None),
aws_secret_access_key=os.getenv("AWS_SECRET_KEY", None),
)
s3 = ff.register_s3(
name="s3-quickstart",
credentials=aws_creds,
bucket_path=os.getenv("S3_BUCKET_PATH", None),
bucket_region=os.getenv("S3_BUCKET_REGION", None),
)
spark = ff.register_spark(
name="spark-generic-s3",
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=s3,
)
Spark with HDFS
spark_creds = ff.SparkCredentials(
master=os.getenv("SPARK_MASTER", "local"),
deploy_mode="client",
python_version="3.7.16",
)
hdfs = ff.register_hdfs(
name="hdfs_provider",
host=host,
port="9000",
username="hduser"
)
spark = ff.register_spark(
name="spark-hdfs",
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=hdfs,
)
You can read more in the docs.
Track which models are using features / training sets at serving time
A highly requested feature was to add a lineage link between models and their feature & training set. Now when you serve a feature and training set you can include an optional model argument.
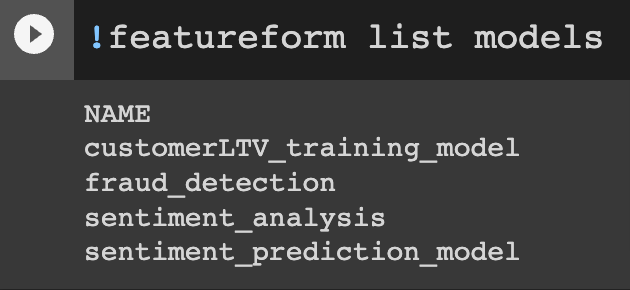
client.features("review_text", entities={"order": "df8e5e994bcc820fcf403f9a875201e6"}, model="sentiment_analysis")
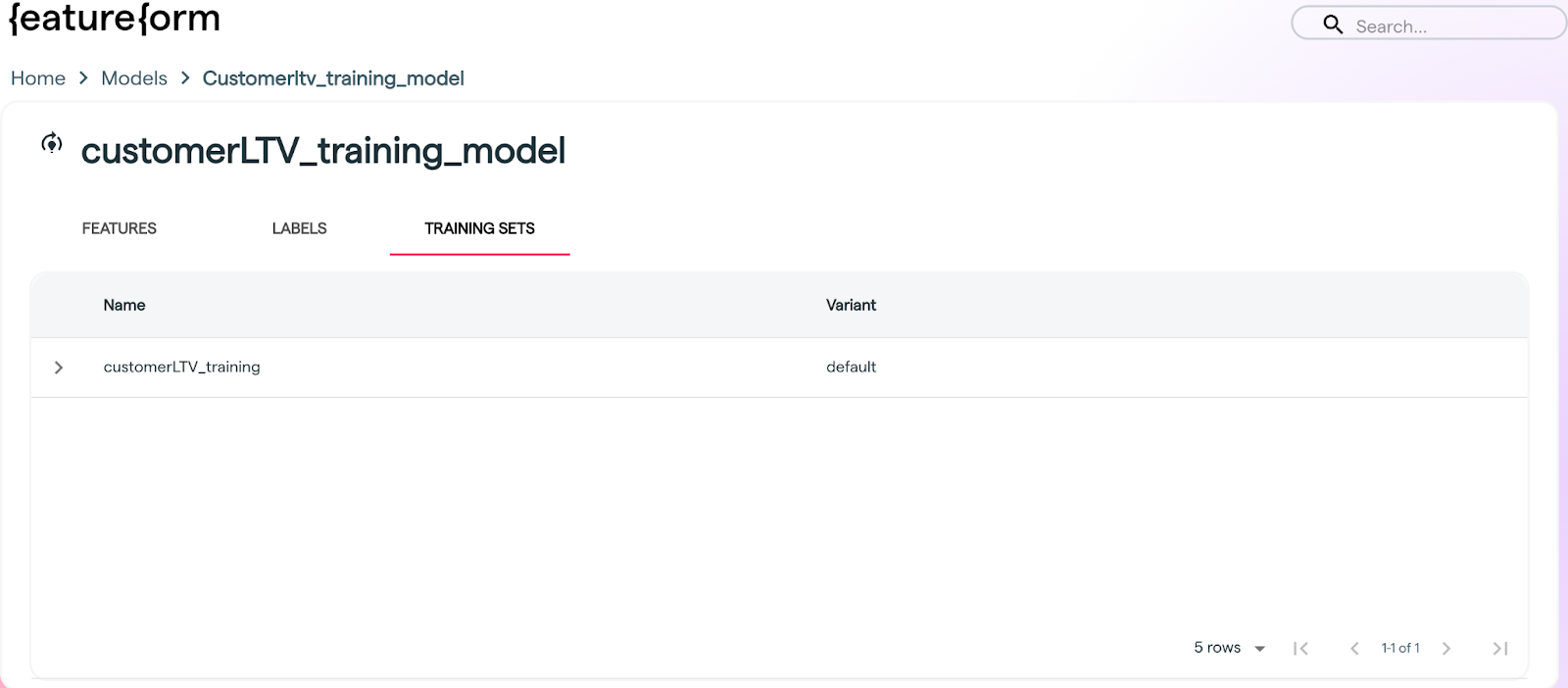
client.training_set(“CustomerLTV_Training”, “default”, model=”linear_ltv_model”)
It can then be viewed via the CLI & the Dashboard:
Dashboard
CLI
You can learn more in the docs
Backup & Recovery now available in open-source Featureform
Backup and recovery was originally exclusive to our enterprise offering. It is our goal to open-source everything in the product that isn’t related to governance, though we often first pilot new features with clients as we nail down the API.
Enable Backups
- Create a k8s secret with information on where to store backups.
> python backup/create_secret.py --help
Usage: create_secret.py [OPTIONS] COMMAND [ARGS]...
Generates a Kubernetes secret to store Featureform backup data.
Use this script to generate the Kubernetes secret, then apply it with:
`kubectl apply -f backup_secret.yaml`
Options:
-h, --help Show this message and exit.
Commands:
azure Create secret for azure storage containers
gcs Create secret for GCS buckets
s3 Create secret for S3 buckets
- Upgrade your Helm cluster (if it was created without backups enabled)
helm upgrade featureform featureform/featureform [FLAGS] --set backup.enable=true --set backup.schedule=<schedule>
Where schedule is in cron syntax, for example an hourly backup would look like:
"0 * * * *"
Recover from backup
Recovering from a backup is simple. In backup/restore, edit the .env-template file with your cloud provider name and credentials, then rename to .env. A specific snapshot can be used by filling in the SNAPSHOT_NAME variable in the .env file.
After that, run recover.sh in that directory.
You can learn more in the docs.
Ability to rotate key and change provider credentials
Prior to this release, if you were to rotate a key and/or change a credential you’d have to create a new provider. We made things immutable to avoid people accidentally overwriting each other's providers; however, this blocked the ability to rotate keys. Now, provider changes work as an upsert.
For example if you had registered Databricks and applied it like this:
databricks = ff.DatabricksCredentials(
host=host,
token=old_token,
cluster_id=cluster,
)
You could change it by simply changing the config and re-applying it.
databricks = ff.DatabricksCredentials(
host=host,
token=new_token,
cluster_id=cluster,
)
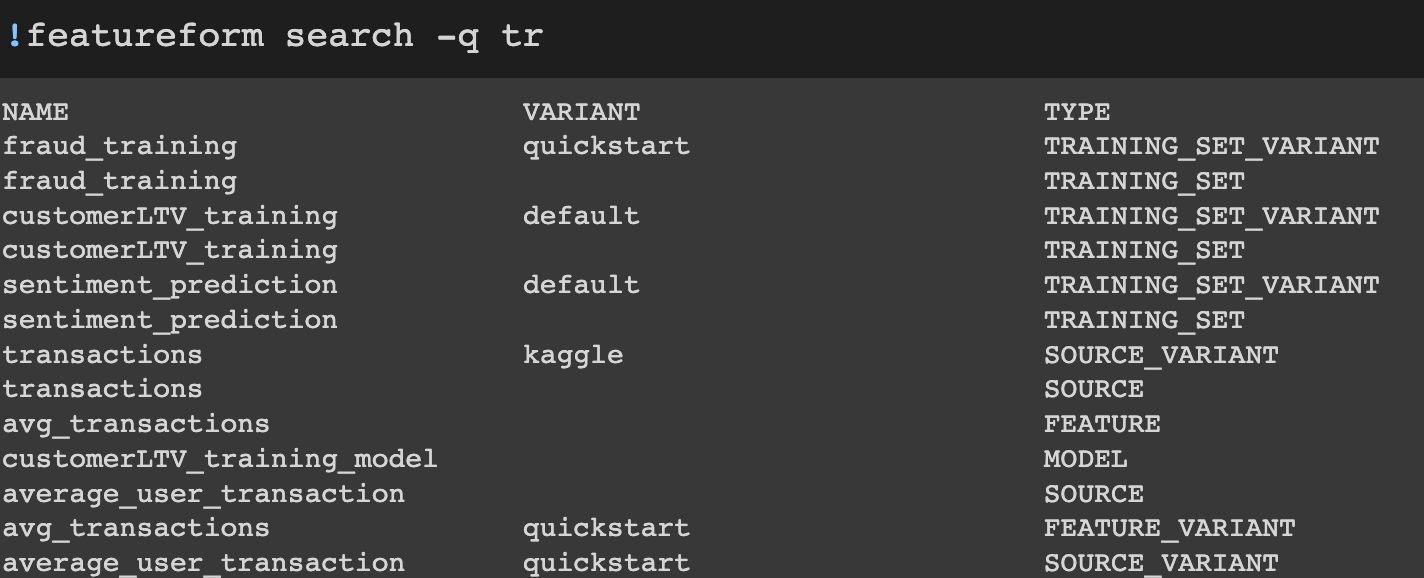
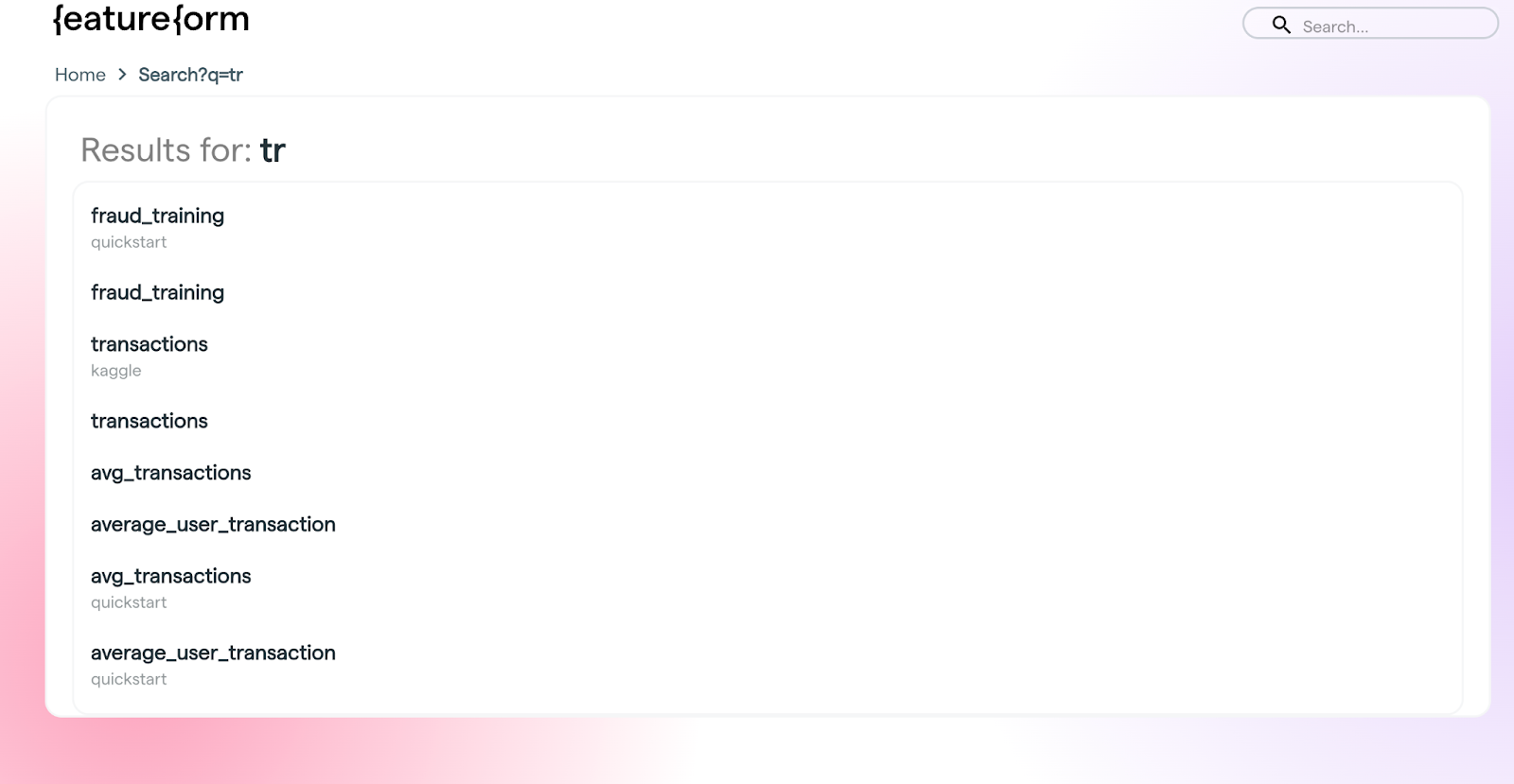
Ability to do full-text search on resources from the CLI
Prior to this release, you could only search resources from the dashboard. We’ve added the same functionality into the CLI. Our goal is to stay as close to feature parity between the dashboard and CLI as possible.
CLI
Dashboard
Enhancements
Mutable Providers
Featureform has historically made all resources immutable to solve a variety of different problems. This includes upstreams changing and breaking downstreams. Over the next couple releases we expect to dramatically pull back on forcing immutability while still avoiding the most common types of problems.
Featureform apply now works as an Upsert. For providers specifically, you can change most of their fields. This also makes it possible to rotate secrets and change credentials as outlined earlier in these release notes.
Support for Legacy Snowflake Credentials
Older deployments of Snowflake used an Account Locator rather than an Organization/Account pair to connect, you can now use our register_snowflake_legacy method.
ff.register_snowflake_legacy(
name = "snowflake_docs",
description = "Example training store",
team = "Featureform",
username = snowflake_username,
password: snowflake_password,
account_locator: snowflake_account_locator,
database: snowflake_database,
schema: snowflake_schema,
)
You can learn more in the docs.
Experimental
Custom Transformation-specific Container Limits for Pandas on K8s transformations
Pandas on K8s is still an experimental feature that we’re continuing to expand on. You were previously able to specify container limits for all, but now for specifically heavy or light transformations you can get more granular about your specifications as follows:
resource_specs = K8sResourceSpecs(
cpu_request="250m",
cpu_limit="50Mi",
memory_request="500m",
memory_limit="100Mi"
)
@k8s.df_transformation(
inputs=[("transactions", “v2”)],
resource_specs=resource_specs
)
def transform(transactions):
pass
You can learn more in the docs.
Published by sdreyer over 1 year ago
What's Changed
- Additional Snowflake Parameters (Role & Warehouse)
Full Changelog: https://github.com/featureform/featureform/compare/v0.5.0...v0.5.1
Published by sdreyer over 1 year ago
What's Changed
- Status Functions For Resources
- Custom KCF Images
- Azure Quickstart
- Support For Legacy Snowflake Credentials
- ETCD Backup and Recovery
Full Changelog: https://github.com/featureform/featureform/compare/v0.4.0...v0.5.0
Published by sdreyer over 1 year ago
What's Changed
- Fix for Provider Image in Local Mode
Full Changelog: https://github.com/featureform/featureform/compare/v0.4.5...v0.4.6