
mage-ai
🧙 Build, run, and manage data pipelines for integrating and transforming data.
APACHE-2.0 License
Bot releases are hidden (Show)
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
🫨 Brand new dbt blocks!
One of our top contributors @christopherscholz just delivered a huge feature! A completely streamlined dbt Block!
Here are some of the highlights:
- Directly integrated into
dbt-core, instead of calling it via a subprocess, which allows to use all of dbts functionalities - Use dbt to seed output dataframes from upstream blocks
- Use dbt to generate correct relations e.g. default schema names, which differ between databases
- Use dbt to preview models, by backporting the
dbt seedcommand todbt-core==1.4.7 - No use of any mage based database connections to handle the block
- Allows to install any dbt adapter, which supports the dbt-core version
- Moved all code into a single interface called
DBTBlock- Doubles as a factory for child blocks
DBTBlockSQLandDBTBlockYAML - Child blocks make it easier to understand which block does what
- Doubles as a factory for child blocks
There's lots to unpack in this one, so be sure to read more in the PR below and check out our updated docs.
by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3497
➕ Add GCS storage to store block output variables
Google Cloud users rejoice! Mage already supports storing block output variables in S3, but thanks to contributor @luizarvo, you can now do the same in GCS!
Check out the PR for more details and read-up on implementation here.
by @luizarvo in https://github.com/mage-ai/mage-ai/pull/3597
✨ Tableau Data Integration Source
Another community-led integration! Thank you @mohamad-balouza for adding a Tableau source for data integration pipelines!
by @mohamad-balouza in https://github.com/mage-ai/mage-ai/pull/3581
🦆 Add DuckDB loader and exporter templates
Last week, we rolled out a ton of new DuckDB functionality, this week, we're adding DuckDB loader and exporter templates! Be sure to check them out when building your new DuckDB pipelines! 😄
by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3553
🧱 Bulk retry incomplete block runs
Exciting frontend improvements are coming your way! You can now retry all of a pipeline's incomplete block runs from the UI. This includes all block runs that do not have completed status.
🐛 Bug Fixes
- Fix using
S3Storageto store block output variables by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3559 and https://github.com/mage-ai/mage-ai/pull/3588 - Support local timezone for cron expressions by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3561
- Make API middlware set status codes if there's an API key or OAUTH token error by @splatcollision in https://github.com/mage-ai/mage-ai/pull/3560
- Fix Postgres connection url parsing by @dy46 in https://github.com/mage-ai/mage-ai/pull/3570
- Fix passing in logger for alternative block execution methods by @dy46 in https://github.com/mage-ai/mage-ai/pull/3571
- Fix variables interpolation in dbt target by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3578
- Fixed
dbt seedrequiring variables by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3579 - Fix updating of
pipelineRowsSortedwhen clearing search query by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3596 - Check yaml serialization before writing variable by @dy46 in https://github.com/mage-ai/mage-ai/pull/3598
- Fix
condition_failedcheck for dynamic blocks by @dy46 in https://github.com/mage-ai/mage-ai/pull/3595
💅 Enhancements & Polish
- Display warning on demo site to prevent users from entering private credentials by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3550
- Update wording for empty pipeline template state by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3557
- Reorder upstream blocks by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3541
- Prioritize using
remote_variables_dirfor variable manager by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3562 - Customize ecs config by @dy46 in https://github.com/mage-ai/mage-ai/pull/3558
- Bookmark values minor improvements by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3576
- Speed up bigquery destination in data integration pipeline by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3590
- Allow declared cookies to propagate to resources by @hugabora in https://github.com/mage-ai/mage-ai/pull/3555
- Refactor: use generic function to call LLM avoid code duplication by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3358
- Allow configuring EMR cluster spark properties by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3592
- Support
TIMESTAMPin redshift convert by @RobinFrcd https://github.com/mage-ai/mage-ai/pull/3567
New Contributors
- @luizarvo made their first contribution in https://github.com/mage-ai/mage-ai/pull/3597
- @RobinFrcd made their first contribution in https://github.com/mage-ai/mage-ai/pull/3567
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.26...0.9.28
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
🐣 DuckDB IO Class and SQL Block
Folks, we've got some ducking magic going on in this release. You can now use DuckDB files inside Mage's SQL Blocks. 🥳 🦆 🪄
You can use data loaders to CREATE and SELECT from DuckDB tables as well as write new data to DuckDB.
Check out our docs to get started today!
by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3463
📊 Charts 2.0
This is another huge feature— a complete overhaul of our Charts functionality!
There are 2 new charts dashboards: a dashboard for all your pipelines and a dashboard for each pipeline.
You can add charts of various types with different sources of data and use these dashboards for observability or for analytics.
There's a ton to unpack here, so be sure to read more in our docs.
by @tommydangerous
⏰ Local timezone setting
This one is a big quality of life improvement: Mage can now display datetimes in local timezones... No more UTC conversion! Just navigate to Settings > Workspace > Preferences to enable a new timezone!
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3481
🔁 Influxdb data loader
A big shoutout to @mazieb! You can now stream data from InfluxDB via Mage. Thanks for your hard work! They added a destination last week!
Read more in our docs here.
by @mazieb in https://github.com/mage-ai/mage-ai/pull/3430
🎚️ Support for custom logging levels
Another frequently requested feature shipping this week, courtesy of @dy46: custom block-level logging!
You can now specify logging at the block-level by directly changing the logger settings:
@data_loader
def load_data(*args, **kwargs):
kwarg_logger = kwargs.get('logger')
kwarg_logger.info('Test logger info')
kwarg_logger.warning('Test logger warning')
kwarg_logger.error('Test logger error')
...
See more in our docs here.
by @dy46 in https://github.com/mage-ai/mage-ai/pull/3473
🐛 Bug Fixes
- Update Oracle discovery table by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3506
- Locking Polars version to 0.19.2 by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3510
- Fix memory leak caused by
zmqcontext destroy by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3514 - Fix: S3 path is joined using
os.path.join-> Error non posix systems by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3520 - Fix raw SQL alias by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3534
- Fix how table name is parsed for SQL blocks by @dy46 in https://github.com/mage-ai/mage-ai/pull/3498
- Fix:
dtypeintis not always casted asint64by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3522 - Fix: paths include posix like forward slash in many instances, which will not work on non-posix systems by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3521
- Fix git authentication issue by @dy46 in https://github.com/mage-ai/mage-ai/pull/3537
- Fix overwriting runtime variables for dbt block by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3543
- Added the Elasticsearch library to setup file by @sujiplr in https://github.com/mage-ai/mage-ai/pull/3501
- Fix:
timestamp out of rangeon Windows by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3519 - Fix: Dependency mismatch between
mage_aiandmage_integrationsby @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3525
💅 Enhancements & Polish
- Only show
Executepipeline action for streaming pipelines by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3492 - Throw exception for ingress by @dy46 in https://github.com/mage-ai/mage-ai/pull/3484
- Update terminal icon by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3503
- Only allow switching to local branches by @dy46 in https://github.com/mage-ai/mage-ai/pull/3507
- Add usage statistics for creating blocks, pipelines, and custom templates by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3528
- Support multiple kafka topics in kafka source by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3532
- Support trailing slash when base path set by @hugabora in https://github.com/mage-ai/mage-ai/pull/3530
- Add checks for cwd in websocket server by @dy46 in https://github.com/mage-ai/mage-ai/pull/3495
- Kafka source and sink include metadata by @mazieb in https://github.com/mage-ai/mage-ai/pull/3404
- Removing obsolete code, handle root path by @hugabora in https://github.com/mage-ai/mage-ai/pull/3546
New Contributors
- @hugabora made their first contribution in https://github.com/mage-ai/mage-ai/pull/3530
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.23...0.9.26
Published by wangxiaoyou1993 about 1 year ago
What's Changed
🎉 Exciting New Features
✨ Add & update block variables through UI
📰 Hot off the press, you can now add and update block variables via the Mage UI!
Check out our docs to learn more about block variables.
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3451
✨ PowerBI source [Data Integration]
You can now pull PowerBI data in to all your Mage projects!
A big shoutout to @mohamad-balouza for this awesome contribution. 🎉
Read more about the connection here.
by @mohamad-balouza in https://github.com/mage-ai/mage-ai/pull/3433
✨ Knowi source [Data Integration]
@mohamad-balouza was hard at work! You can also integrate Knowi data in your Mage projects! 🤯
Read more about the connection here.
by @mohamad-balouza in https://github.com/mage-ai/mage-ai/pull/3446
✨ InfluxDB Destination [Streaming]
A big shoutout to @mazieb! You can now stream data to InfluxDB via Mage. Thanks for your hard work!
Read more in our docs here.
by @mazieb in https://github.com/mage-ai/mage-ai/pull/3378
🐛 Bug Fixes
- Fix command on GCP cloud run by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3437
- Fix Git sync issues by @dy46 in https://github.com/mage-ai/mage-ai/pull/3436
- Bump GitPython and update Git Sync logic by @dy46 in https://github.com/mage-ai/mage-ai/pull/3458
- Remove unnecessary
statusquery from block runs request by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3444 - Fix AWS secrets manager dependency issue by @dy46 in https://github.com/mage-ai/mage-ai/pull/3448
- Fix comparing bookmark value for timestamp column in BigQuery by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3452
- Compare
start_timeandexecution_dateinshould_scheduleby @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3466 - Fix initial ordering of pipeline rows by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3472
💅 Enhancements & Polish
- Update Triggers list page with filters and clean up subheader by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3424
- Fix and optimize pre-commit hook check-yaml and add check-json by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3412
- Full Code Quality Check in Github Action Workflow "Build and Test" by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3413
- Docker: Lint Image and some best practices by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3410
- Support for
local_python_forceexecutor type and configuring ECS executor launch type @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3447 - Limit Github Action Workflow "Build and Test" by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3411
- Hide OpenAI API key by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3455
- Add additional health check message and support unique constraints in Postgres sink by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3457
- Support autoscaling EMR clusters by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3468
- Support GitHub Auth for different workspaces by @dy46 in https://github.com/mage-ai/mage-ai/pull/3456
- Add timestamp precision in Trino by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3465
- Handle transformer renaming columns not breaking destination data types in integration pipelines by @splatcollision in https://github.com/mage-ai/mage-ai/pull/3462
New Contributors
- @mazieb made their first contribution in https://github.com/mage-ai/mage-ai/pull/3378
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.21...0.9.23
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
✨ Add & update block variables through UI
📰 Hot off the press, you can now add and update block variables via the Mage UI!
Check out our docs to learn more about block variables.
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3451
✨ PowerBI source [Data Integration]
You can now pull PowerBI data in to all your Mage projects!
A big shoutout to @mohamad-balouza for this awesome contribution. 🎉
Read more about the connection here.
by @mohamad-balouza in https://github.com/mage-ai/mage-ai/pull/3433
✨ Knowi source [Data Integration]
@mohamad-balouza was hard at work! You can also integrate Knowi data in your Mage projects! 🤯
Read more about the connection here.
by @mohamad-balouza in https://github.com/mage-ai/mage-ai/pull/3446
✨ InfluxDB Destination [Streaming]
A big shoutout to @mazieb! You can now stream data to InfluxDB via Mage. Thanks for your hard work!
Read more in our docs here.
by @mazieb in https://github.com/mage-ai/mage-ai/pull/3378
🐛 Bug Fixes
- Fix command on GCP cloud run by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3437
- Fix Git sync issues by @dy46 in https://github.com/mage-ai/mage-ai/pull/3436
- Bump GitPython and update Git Sync logic by @dy46 in https://github.com/mage-ai/mage-ai/pull/3458
- Remove unnecessary
statusquery from block runs request by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3444 - Fix AWS secrets manager dependency issue by @dy46 in https://github.com/mage-ai/mage-ai/pull/3448
- Fix comparing bookmark value for timestamp column in BigQuery by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3452
- Compare
start_timeandexecution_dateinshould_scheduleby @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3466 - Fix initial ordering of pipeline rows by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3472
💅 Enhancements & Polish
- Update Triggers list page with filters and clean up subheader by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3424
- Fix and optimize pre-commit hook check-yaml and add check-json by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3412
- Full Code Quality Check in Github Action Workflow "Build and Test" by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3413
- Docker: Lint Image and some best practices by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3410
- Support for
local_python_forceexecutor type and configuring ECS executor launch type @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3447 - Limit Github Action Workflow "Build and Test" by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3411
- Hide OpenAI API key by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3455
- Add additional health check message and support unique constraints in Postgres sink by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3457
- Support autoscaling EMR clusters by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3468
- Support GitHub Auth for different workspaces by @dy46 in https://github.com/mage-ai/mage-ai/pull/3456
- Add timestamp precision in Trino by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3465
- Handle transformer renaming columns not breaking destination data types in integration pipelines by @splatcollision in https://github.com/mage-ai/mage-ai/pull/3462
New Contributors
- @mazieb made their first contribution in https://github.com/mage-ai/mage-ai/pull/3378
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.21...0.9.23
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
✨ Single-task ECS pipeline executor 🤖
Mage now supports running the whole pipeline process in one AWS ECS task instead of running pipeline blocks in separate ECS tasks! This allows you to speed up pipeline execution in ECS tasks by saving ECS task startup time.
Here's an example pipeline metadata.yaml:
blocks:
- ...
- ...
executor_type: ecs
run_pipeline_in_one_process: true
name: example_pipeline
...
The ECS executor_config can also be configured at the pipeline level.
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3418
✨ Postgres streaming destination 🐘
Postgres enthusiasts rejoice! You can now stream data directly to Postgres via streaming pipelines! 😳
Check out the docs for more information on this handy new destination.
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3423
✨ Added sorting to the Block Runs table
You can now sort the Block Runs table by clicking on the column headers! Those of us who are passionate about having our ducks in a row are happy about this one! 🦆
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3356
✨ Enable deleting individual runs from pipeline runs table
Bothered by that one run you'd rather forget? Individual runs can be dropped from the pipeline runs table, so you don't have to worry about them anymore!
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3370
✨ Add timeout for block runs and pipeline runs
Much like Buzz Lightyear, we're headed "to infinity and beyond," but we get that your pipelines shouldn't be. This feature allows you to configure timeouts for both blocks and pipelines— if a run exceeds the timeout, it will be marked as failed.
by @dy46 in https://github.com/mage-ai/mage-ai/pull/3399
🐛 Bug Fixes
- Fix
nextjslocal build type error by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3389 - Fixed
NULLheaders breaking API Source by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3386 - Fixes on MongoDB destination (Data integration) by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3388
- Fix Git commit from version control by @dy46 in https://github.com/mage-ai/mage-ai/pull/3397
- Change the default search path to the schema given in the connection URL for PostgreSQL by @csharplus in https://github.com/mage-ai/mage-ai/pull/3406
- Raise exception if a pipeline has duplicate block uuids by @dy46 in https://github.com/mage-ai/mage-ai/pull/3385
- Fix creating subfolder when renaming block by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3419
- Docker: Installation Method of Node using
setup_17.xis no longer supported by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3405 - [dy] Add support for key properties for postgresql destination by @dy46 in https://github.com/mage-ai/mage-ai/pull/3422
💅 Enhancements & Polish
- Added disable schema creation config by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3417
- Read DB credentials from AWS secret manager by @dy46 in https://github.com/mage-ai/mage-ai/pull/3354
- Add healthcheck to sqs streaming sourceby @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3393
- Enhancement: token expiry time env by @juancaven1988 in https://github.com/mage-ai/mage-ai/pull/3396
- Auto-update triggers in code when making changes in UI by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3395
- Add fetch and reset to version control app by @dy46 in https://github.com/mage-ai/mage-ai/pull/3409
- Set correct file permissions when using shutil by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3262
- Create
lsnand_mage_deleted_atin initial log_based syncby @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3394 - Feat: Added Missing destination block warning by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3407
New Contributors
- @WesAkers made their first contribution in https://github.com/mage-ai/mage-ai/pull/3382
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.19...0.9.21
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
✨ New AI Functionality
As a part of this release, we have some exciting new AI functionality: you can now generate pipelines and add inline comments using AI. 🤯
See the following links for documentation of the new functionality.
by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3365 and https://github.com/mage-ai/mage-ai/pull/3359
✨ Elasticsearch as sink for streaming
Elasiticsearch is now available as a streaming sink. 🥳🎉
A big thanks to @sujiplr for their contribution!
by @sujiplr in https://github.com/mage-ai/mage-ai/pull/3335
✨ Add GitHub source
The GitHub API is now available as a data integrations— you can pull in commits, changes, and more from the GitHub API!
by @mattppal in https://github.com/mage-ai/mage-ai/pull/3252
✨ Interpolate variables in dbt profiles
This is a big one for our dbt users out there! You can now use {{ variables('...') }} in dbt profiles.yml.
jaffle_shop:
outputs:
dev:
dbname: postgres
host: host.docker.internal
port: 5432
schema: {{ variables('dbt_schema') }}
target: dev
That means pulling in custom Mage variables, directly!
by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3337
✨ Enable sorting on pipelines dashboard
Some great frontend improvements are going down! You can now sort pipelines on the dashboards, both with and without groups/filters enabled!
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3327
✨ Display data integration source docs inline
Another awesome community contribution— this one also on the frontend. Thanks to @splatcollision, we now have inline documentation for our data integration sources!
Now, you can see exactly what you need, directly from the UI!
by @splatcollision in https://github.com/mage-ai/mage-ai/pull/3349
🐛 Bug Fixes
- Fix MongoDB source by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3342
- Overwrite existing project_uuid if a project_uuid is set when starting the server by @dy46 in https://github.com/mage-ai/mage-ai/pull/3338
- Add started_at to pipeline run policy by @dy46 in https://github.com/mage-ai/mage-ai/pull/3345
- Fix passing variables to run_blocks by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3346
- Not pass liveness_probe to cloud run jobs by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3355
- Fix data integration pipeline column renaming in transformer block by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3360
- Fix FileContentResource file path check by @dy46 in https://github.com/mage-ai/mage-ai/pull/3363
- Update api/status endpoint by @dy46 in https://github.com/mage-ai/mage-ai/pull/3352
- Removed unique_constraints from valid_replication_keys definition by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3369
- Fix dbt command failure due to empty content args by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3376
💅 Enhancements & Polish
✨ New Docs Structure
You might notice our docs have a new look! We've changed how we think about side-navs and tabs.
Our goal is to help you find what you need, faster. We hope you like it!
_by @mattppal in https://github.com/mage-ai/mage-ai/pull/3324 and https://github.com/mage-ai/mage-ai/pull/3367
✨ Other Enhancements
- Explain cron syntax in a human readable way by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3348
- Add run_pipeline_in_one_process in pipeline settings by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3347
- Preview next pipeline run time for triggers by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3341
- Optimize Docker build by @christopherscholz in https://github.com/mage-ai/mage-ai/pull/3329
- Integration pipeline column explanations by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3353
- Allow using k8s executor config for streaming pipeline by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3371
- Add role to Snowflake data integration pipeline by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3374
- Disable automatic dbt tests by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3357
- Update terminal server user token handling by @dy46 in https://github.com/mage-ai/mage-ai/pull/3350
- Restrict file creation via API by @dy46 in https://github.com/mage-ai/mage-ai/pull/3351
New Contributors
- @sujiplr made their first contribution in https://github.com/mage-ai/mage-ai/pull/3335
- @splatcollision made their first contribution in https://github.com/mage-ai/mage-ai/pull/3349
- @pilosoposerio made their first contribution in https://github.com/mage-ai/mage-ai/pull/3377
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.16...0.9.19
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
✨ Global data products are now available in Mage! 🎉
A data product is any piece of data created by 1 or more blocks in a pipeline. For example, a block can create a data product that is an in-memory DataFrame, or a JSON serializable data structure, or a table in a database.
A global data product is a data product that can be referenced and used in any pipeline across the entire project. A global data product is entered into the global registry (global_data_products.yaml) under a unique ID (UUID) and it references an existing pipeline. Learn more here.
by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3206
✨ Add block templates for MSSQL 🤘
We now have some awesome block templates for our MySQL users out there!
Check them out:
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3294
✨ Support sharing memory objects across blocks
In the metadata.yml of a standard batch pipeline, you can now configure running pipelines in a single process:
blocks:
...
run_pipeline_in_one_process: true
...
You may now also:
- Define object once and make it available in any block in the pipeline via keyword arguments
kwargs['context'] - Pass variables between blocks in memory directly
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3280
🐛 Bug Fixes
- Added type check on unique_constraints by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3282
- Proper filtering in multi-workspace pipeline runs & subproject role creation by @dy46 in https://github.com/mage-ai/mage-ai/pull/3283
- Add column identifier for Trino by @dy46 in https://github.com/mage-ai/mage-ai/pull/3311
- Fix mage run cli command with variables by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3315
- Fix
async_generate_block_with_descriptionupstream_blocksparam by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3313 - Removed unused config in Salesforce destination by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3287
- Fix BigQuery bookmark datetime comparison by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3325
- Improve secrets handling by @dy46 in https://github.com/mage-ai/mage-ai/pull/3309
- Adding
oracledblib to mage-ai by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3319
💅 Enhancements & Polish
-
base.py: Add XML support for file read/write in S3, GCP, and other cloud storage providers by @adelcast in https://github.com/mage-ai/mage-ai/pull/3279 - Save logs scroll position for trigger logs by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3285
- Update error logging for block runs by @dy46 in https://github.com/mage-ai/mage-ai/pull/3234
- Browser-specific dependency graph improvements by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3300
- Updated Clickhouse destination by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3286
- Make pipeline run count pagination consistent by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3310
- Add new base path environment variables by @dy46 in https://github.com/mage-ai/mage-ai/pull/3289
- Add pipeline
created_atproperty by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3317 - Add pagination to pipeline run block runs page by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3316
- Added all columns as replication key by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3301
- Improve streaming pipeline stability by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3326
- Added test connection to
google_adssource by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3322 - Open and edit any file, including prefix . by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3255
- Add namespace to K8sBlockExecutor config by @mattcamp in https://github.com/mage-ai/mage-ai/pull/3246
- Add a community Code of Conduct by @mattppal in https://github.com/mage-ai/mage-ai/pull/3318
- Add documentation for adapting an existing tap by @mattppal in https://github.com/mage-ai/mage-ai/pull/3290
New Contributors
- @adelcast made their first contribution in https://github.com/mage-ai/mage-ai/pull/3279
- @mattcamp made their first contribution in https://github.com/mage-ai/mage-ai/pull/3246
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.14...0.9.16
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
✨ New Connector: sFTP
Ahoy! There's a new connector on-board the Mage ship: sFTP. 🚢
by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3214
✨ Pipeline Schedule Tags
Pipeline schedules can now be tagged to help categorize them in the UI. 🎉
@tommydangerous in https://github.com/mage-ai/mage-ai/pull/3222
✨ Pipeline Run Cancellation
😎 Manual pipeline runs can now be cancelled via the UI.
by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3236
🐛 Bug Fixes
- Fix error logging for replica blocks by @dy46 in https://github.com/mage-ai/mage-ai/pull/3183
- Fix variables dir construction by @dy46 in https://github.com/mage-ai/mage-ai/pull/3203
- Escape password in
db_connection_urlby @dy46 in https://github.com/mage-ai/mage-ai/pull/3189 - Renaming blocks with shared pipelines by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3199
- Fix infinite rendering loop in SchemaTable by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3213
- Fix log detail metrics object rendering issue by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3216
- Fix
dbt-snowflakewhen password null by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3225 - Update redshift format value by @dy46 in https://github.com/mage-ai/mage-ai/pull/3196
- Fix EMR pyspark kernel permission error by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3227
- Update where the
frontend_dist_base_pathis created by @dy46 in https://github.com/mage-ai/mage-ai/pull/3224 - Block run and pipeline run start/completion times in UTC by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3229
- Allow adding block from search by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3235
- Fix setting project uuid error by @dy46 in https://github.com/mage-ai/mage-ai/pull/3231
- Fix custom templates with empty parent names by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3253
- Not obfuscate data in data integration records. by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3265
- When comparing
spark.jars, use the file names and neglect paths by @csharplus in https://github.com/mage-ai/mage-ai/pull/3264 - Import decorators when executing block module by @dy46 in https://github.com/mage-ai/mage-ai/pull/3243
- Fix using location in
dbt-bigquery. by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3273 - Fix trigger not showing up in block run view by @dy46 in https://github.com/mage-ai/mage-ai/pull/3274
💅 Enhancements & Polish
- Updated Facebook Ads SDK to 17.0.2 by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3187
- Support updating ingress when creating k8s workspace by @dy46 in https://github.com/mage-ai/mage-ai/pull/3200
- Add API endpoint to Trigger detail page by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3219
- Add custom timeout to kafka streams by @mattppal in https://github.com/mage-ai/mage-ai/pull/3204
- Limit the number of rows of sql block output in pipeline run by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3237
- Hide the token in the UI by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3254
- Use greater than operator for unique columns in source sql bookmark comparison. by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3256
- Update block runs table by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3257
- Improve error message for duplicate column name. by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3268
- Add count of completed blocks in pipelineRun table by @oonyoontong in https://github.com/mage-ai/mage-ai/pull/3245
- Block run count formatting in PipelineRuns table by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3276
- Added clickhouse state file location by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3201
- Generate comment for code by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3161
- Support dbt model config option for database by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3208
- Add custom block template for streaming pipeline by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3209
- Do not convert variables dir to abs path for s3 variables dir by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3210
- Add tags and tags association for polymorphic relationship by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3211
- Change the table creation into two steps as required by the ClickHouse Cloud by @csharplus in https://github.com/mage-ai/mage-ai/pull/3194
- Add openssl dockerfile by @dy46 in https://github.com/mage-ai/mage-ai/pull/3215
- Add upstream blockIds when generating pipeline code by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3169
New Contributors
- @oonyoontong made their first contribution in https://github.com/mage-ai/mage-ai/pull/3245
- @christopherscholz made their first contribution in https://github.com/mage-ai/mage-ai/pull/3258
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.11...0.9.14
Published by mattppal about 1 year ago
🎉 Exciting New Features
✨ Base path configuration for Mage
There's a new environment variable in town— MAGE_BASE_PATH! 🤠
Mage now supports adding a prefix to a Mage URL, i.e. localhost:6789/my_prefix/
by @dy46 in https://github.com/mage-ai/mage-ai/pull/3141
✨ Support for DROP TABLE in raw SQL blocks
Raw SQL blocks can now drop tables! 🎉
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3184
✨ MongoDB connection string support
Our MongoDB users will be happy about this one— MongoDB can now be accessed via a connection string, for example: mongodb+srv://{username}:{password}@{host}
Doc: https://docs.mage.ai/integrations/databases/MongoDB#add-credentials
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3188
✨ Salesforce destination
Data integration pipelines just got another great destination— Salesforce!
by @Luishfs in https://github.com/mage-ai/mage-ai/pull/2772
🐛 Bug Fixes
- Fix circular dependency and repo config issues by @dy46 in https://github.com/mage-ai/mage-ai/pull/3168
- Fix an issue in the bigquery init method by @csharplus in https://github.com/mage-ai/mage-ai/pull/3171
- Fix base path frontend_dist creation by @dy46 in https://github.com/mage-ai/mage-ai/pull/3182
- Fix the
booldata type conversion issue with the ClickHouse exporter by @csharplus in https://github.com/mage-ai/mage-ai/pull/3172 - Do not start pipeline run immediately after creation by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3173
💅 Enhancements & Polish
- Add block runtime chart for all blocks by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3156
- Use Playwright for web UI test automation by @erictse in https://github.com/mage-ai/mage-ai/pull/3075
- Auto-scroll to newest logs by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3170
- Add
DISABLE_TERMINALenvironment variable by @juancaven1988 in https://github.com/mage-ai/mage-ai/pull/3174 - Consolidate AWS region variables by @dy46 in https://github.com/mage-ai/mage-ai/pull/3152
- Adding test connection to MongoDB destination by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3159
- Adding test connection to clickhouse destination by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3158
- Adding snowflake table name option and regex by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3186
- Remove streaming S3 sink timer error by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3190
- Include
frontend_dist_base_path_templatein package by @dy46 in https://github.com/mage-ai/mage-ai/pull/3178 - New options to pass Azure Blob
upload_kwargsto allow overwriting an existing file or use any other options by @sumanshusamarora in https://github.com/mage-ai/mage-ai/pull/3148
🎉 New Contributors
- @Radu-D made their first contribution in https://github.com/mage-ai/mage-ai/pull/3179
- @juancaven1988 made their first contribution in https://github.com/mage-ai/mage-ai/pull/3174
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.10...0.9.11
Published by mattppal about 1 year ago
What's Changed
🎉 Exciting New Features
🤖 Create blocks and documentation using LLMs
Block Creation
Document Generation
From the following PRs:
- Generate block using AI by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3095
- Generate documentation using AI by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3105
- Generate block template based on block description by @matrixstone in https://github.com/mage-ai/mage-ai/pull/3029
- Create model and API endpoint for global data products by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3135
❄️ Enable batch upload for Snowflake destination
Leveraging write_pandas in the snowflake-connector-python library, this feature enhances the speed of batch uploads using Snowflake destinations 🤯 by @csharplus in https://github.com/mage-ai/mage-ai/pull/2896
Auto-delete logs after retention period
Now, Mage can auto-remove logs after your retention period expires!
Configure retention_period in logging_config:
logging_config:
retention_period: '15d'
Run command to delete old logs:
mage clean-old-logs k8s_project
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3139
MongoDB destination support (data integration)
MongoDB is now supported as a destination! 🎉 by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3084
Pipeline-level concurrency
It's now possible to configure concurrency at the pipeline level:
concurrency_config:
block_run_limit: 1
pipeline_run_limit: 1
Doc: https://docs.mage.ai/design/data-pipeline-management#pipeline-level-concurrency
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3112
🧱 New add-block flow
Mage's UI has been improved to feature a new add-block flow! by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3094, https://github.com/mage-ai/mage-ai/pull/3074, & https://github.com/mage-ai/mage-ai/pull/3106
Custom k8s executors
Mage now support custom k8s executor configuration:
k8s_executor_config:
service_account_name: mageai
job_name_prefix: "{{ env_var('KUBE_NAMESPACE') }}"
container_config:
image: mageai/mageai:0.9.7
env:
- name: USER_CODE_PATH
value: /home/src/k8s_project
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3127
Custom s3 endpoint_url in logger
You can now configure a custom endpoint_url in s3 loggers, allowing you to customize how messages are displayed!
logging_config:
type: s3
level: INFO
destination_config:
bucket: <bucket name>
prefix: <prefix path>
aws_access_key_id: <(optional) AWS access key ID>
aws_secret_access_key: <(optional) AWS secret access key>
endpoint_url: <(optional) custom endpoint url>
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3137
Render text/html from block output
Text and HTML from block output is now rendered!
by @dy46 in https://github.com/mage-ai/mage-ai/pull/3079
Clickhouse data integration support
Clickhouse is now supported as a integrations destination! by @Luishfs in https://github.com/mage-ai/mage-ai/pull/3005
Custom timeouts for ECS tasks
You can now set custom timeouts for all of your ECS tasks! by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3144
Run multiple Mage instances with the same PostgreSQL databases
A single Postgres database can now support multiple Mage instances ✨ by @csharplus in https://github.com/mage-ai/mage-ai/pull/3070
🐛 Bug Fixes
- Clear pipeline list filters when clicking Defaults by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3092
- Fetch Snowflake role by @mattppal in https://github.com/mage-ai/mage-ai/pull/3100
- Add service argument to OracleDB data loader by @mattppal in https://github.com/mage-ai/mage-ai/pull/3032
- Fix
pymssqldependency by @dy46 in https://github.com/mage-ai/mage-ai/pull/3114 - Include runs without associated triggers in pipeline run count by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3118
- Fix positioning of nested flyout menu 4 levels deep by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3125
- Batch git sync in
pipeline_schedulerby @dy46 in https://github.com/mage-ai/mage-ai/pull/3102 - Only try to interpolate variables if they are in the query by @dy46 in https://github.com/mage-ai/mage-ai/pull/3142
- Fix command for running streaming pipeline in k8s executor. by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3093
- Fix block flow bugs by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3094
- Catch timeout exception for test_connection by @dy46 in https://github.com/mage-ai/mage-ai/pull/3143
- Fix showing duplicate templates for v1 by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3128
-
check_statusmethod bug fix to look at pipelines ran between specific time period by @sumanshusamarora in https://github.com/mage-ai/mage-ai/pull/3115 - Fix db init on start by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3080
- Fix logic for making API requests for block outputs or analyses that were throwing errors due to invalid
pipeline_uuidsby @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3090
💅 Enhancements & Polish
- Decrease variables response size by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3097
- Cancel block runs when pipeline run fails by @dy46 in https://github.com/mage-ai/mage-ai/pull/3096
- Clean up code in
VariableResourcemethod by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3099 - Import block function from file for test execution by @dy46 in https://github.com/mage-ai/mage-ai/pull/3110
- Misc UI improvements by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3133
- Polish custom templates by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3120
- Throw correct exception about
io-configby @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3130 - Clarify input for dbt profile target if a default target is not configured by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3077
- Support nested sampling on output by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3086
- Add API endpoint for fetching OAuth access tokens by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3089
New Contributors
- @sumanshusamarora made their first contribution in https://github.com/mage-ai/mage-ai/pull/3115
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.8...0.9.10
Published by mattppal about 1 year ago

What's Changed
🎉 Exciting New Features
🔥 Custom block & pipeline templates
With this release, Magers now have the option to create pipeline templates, then use those to populate new pipelines.
Additionally, you may now browse, create, and use custom block templates in your pipelines. 🎉
by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3064, https://github.com/mage-ai/mage-ai/pull/3042 and https://github.com/mage-ai/mage-ai/pull/3065
🛟 Save pipelines list filters and groups
Your pipeline filters and groups are now sticky— that means setting filters/groups will persist through your Mage session.

by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3059
Horizontal scaling support for schedulers
You can now run the web server and scheduler in separate containers, allowing for horizontal scaling of the scheduler! Read more in our docs.
Run scheduler only:
/app/run_app.sh mage start project_name --instance-type scheduler
Run web server only:
/app/run_app.sh mage start project_name --instance-type web_server
by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3016
🎏 Run parallel integration streams
Data integration streams may now be executed in parallel!
by @dy46 in https://github.com/mage-ai/mage-ai/pull/1474
Update secrets management backend
The secrets management backend can now handle multiple environments!
by @dy46 in https://github.com/mage-ai/mage-ai/pull/3000
📆 Include interval datetimes and intervals in block variables
Interval datetimes and durations are now returned in block variables. Check out our docs for more info!
by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3058 and https://github.com/mage-ai/mage-ai/pull/3068
🐛 Bug Fixes
- Persist error message popup when selecting stream by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3028
- Add google oauth2 scopes to bigquery client by @mattppal in https://github.com/mage-ai/mage-ai/pull/3023
- enable backfills
deleteand add documentation by @mattppal in https://github.com/mage-ai/mage-ai/pull/3012 - Show warning if no streams displayed by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3034
- Fix SLA alerting as soon as trigger run starts by @dy46 in https://github.com/mage-ai/mage-ai/pull/3036
- Display error when fetching data providers by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3038
- Add
/filesroute to backend server and fix TypeError in FileEditor by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3041 - Create dynamic block runs in block executor by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3035
- Fix block settings not updating after saving by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3021
- Catch redis error and fix logging by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3047
- Fix roles query by entity bug by @dy46 in https://github.com/mage-ai/mage-ai/pull/3049
- API quickstart for rapid development by @mattppal in https://github.com/mage-ai/mage-ai/pull/3017
- Fix pipelines list filters and group bys not removing by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3060
- Fix deleting block by @wangxiaoyou1993 in https://github.com/mage-ai/mage-ai/pull/3011
- Temporary pymssql fix v2 by @dy46 in https://github.com/mage-ai/mage-ai/pull/3015
💅 Enhancements & Polish
- Add
Updated Atcolumn to Pipelines list page by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3050 - Default error log to Errors tab when opening log detail by @johnson-mage in https://github.com/mage-ai/mage-ai/pull/3052
- Add timeout for fetching files for git by @dy46 in https://github.com/mage-ai/mage-ai/pull/3051
- Encode URI component for file path on files page by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3067
- When clicking a file in file browser, select block if in pipeline by @tommydangerous in https://github.com/mage-ai/mage-ai/pull/3024
New Contributors
- @Hikari made their first contribution in https://github.com/mage-ai/mage-ai/pull/3037
Full Changelog: https://github.com/mage-ai/mage-ai/compare/0.9.4...0.9.8
Published by thomaschung408 over 1 year ago

🎉 Features
Azure Data Lake streaming pipeline support
Docs: https://docs.mage.ai/guides/streaming/destinations/azure_data_lake
Mage now supports Azure Data Lake as a streaming destination!

Pipeline Tags
Tags can now be applied to pipelines. Users can leverage the pipeline view to apply filters or group pipelines by tag.
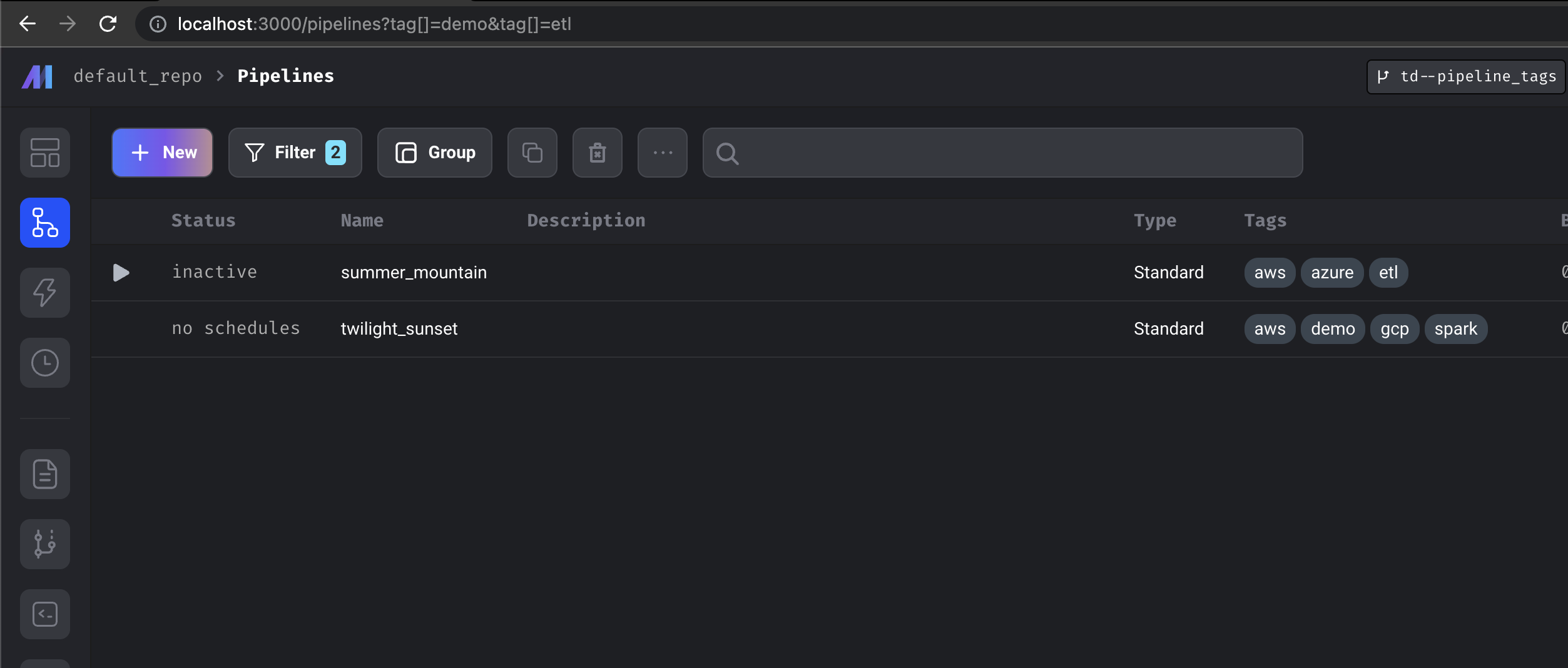
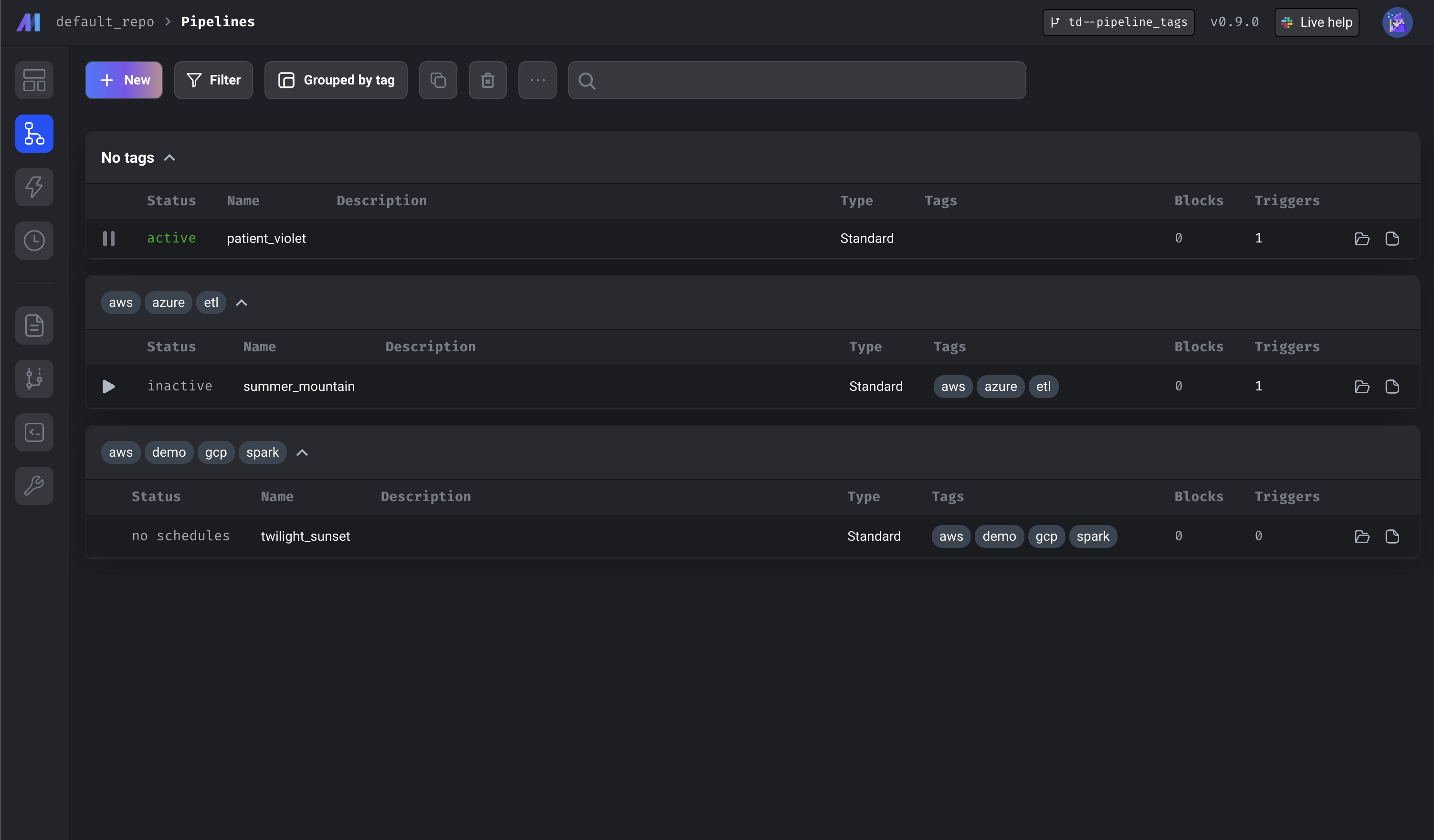
Support for custom k8s executor job prefixes
You can now prefix your k8s executor jobs! Here’s an example k8s executor config file:
k8s_executor_config:
job_name_prefix: data-prep
resource_limits:
cpu: 1000m
memory: 2048Mi
resource_requests:
cpu: 500m
memory: 1024Mi
service_account_name: default
See the documentation for further details.
Removed data integration config details from logs
Mage no longer prints data integration settings in logs: a big win for security. 🔒
💅 Other bug fixes & polish
Cloud deployment
- Fix k8s job deletion error.
- Fix fetching AWS events while editing trigger.
- Fixes for Azure deployments.
- Integrate with Azure Key Vault to support
azure_secret_varsyntax: docs. - Pass resource limits from main ECS task to dev tasks.
- Use network configuration from main ECS service as a template for dev tasks.
Integrations
- Fix Postgres schema resolution error— this fixes schema names with characters like hyphens for Postgres.
- Escape reserved column names in Postgres.
- Snowflake strings are now casted as
VARCHARinstead ofVARCHAR(255). The MySQL loader now usesTEXTfor strings to avoid truncation. - Use AWS session token in io.s3.
- Fix the issue with database setting when running ClickHouse in SQL blocks
Other
- Fix multiple upstream block callback error. Input variables will now be fetched one block at a time.
- Fix data integration metrics calculation.
- Improved variable serialization/deserialization— this fixes kernel crashes due to OOM errors.
- User quote: "A pipeline that was taking ~1h runs in less than 2 min!"
- Fix trigger edit bug— eliminates bug that would reset fields in trigger.
- Fix default filepath in ConfigFileLoader (Thanks Ethan!)
- Move
COPYstep to reduce Docker build time. - Validate env values in trigger config.
- Fix overview crashing.
- Fix cron settings when editing in trigger.
- Fix editing pipeline’s executor type from settings.
- Fix block pipeline policy issue.
🗣️ Shout outs
- @ethanbrown3 made their first contribution in https://github.com/mage-ai/mage-ai/pull/2976 🎉
- @erictse made their first contribution in https://github.com/mage-ai/mage-ai/pull/2977 🥳
Published by thomaschung408 over 1 year ago

Workspace management
You can use Mage with multiple workspaces in the cloud now. Mage has a built in workspace manager that can be enabled in production. This feature is similar to the multi-development environments, but there are settings that can be shared across the workspaces. For example, the project owner can set workspace level permissions for users. The current additional features supported are:
- workspace level permissions
- workspace level git settings
Upcoming features:
- common workspace metadata file
- customizable permissions and roles
- pipeline level permissions
Doc: https://docs.mage.ai/developing-in-the-cloud/workspaces/overview
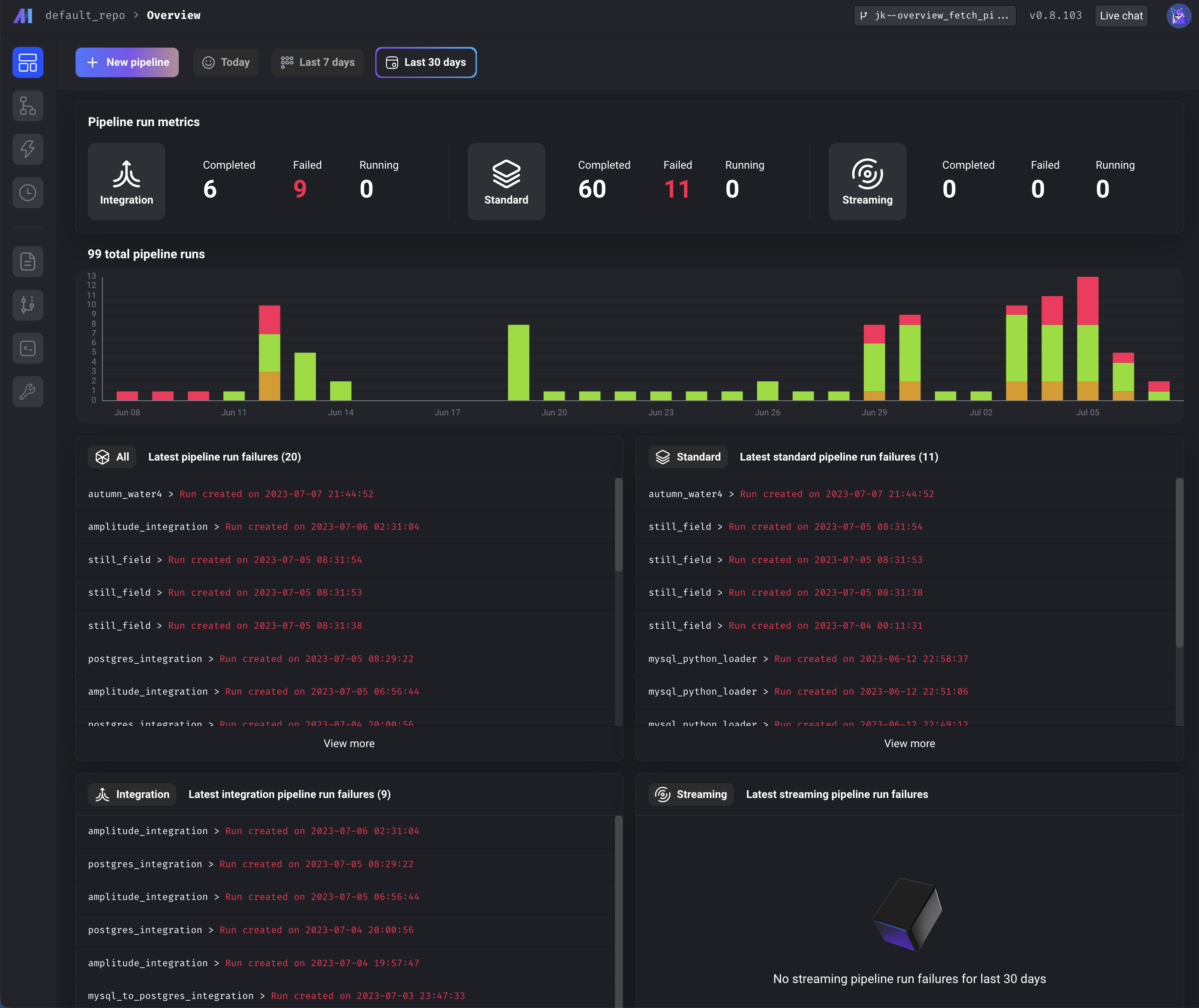
Pipeline monitoring dashboard
Add "Overview" page to dashboard providing summary of pipeline run metrics and failures.
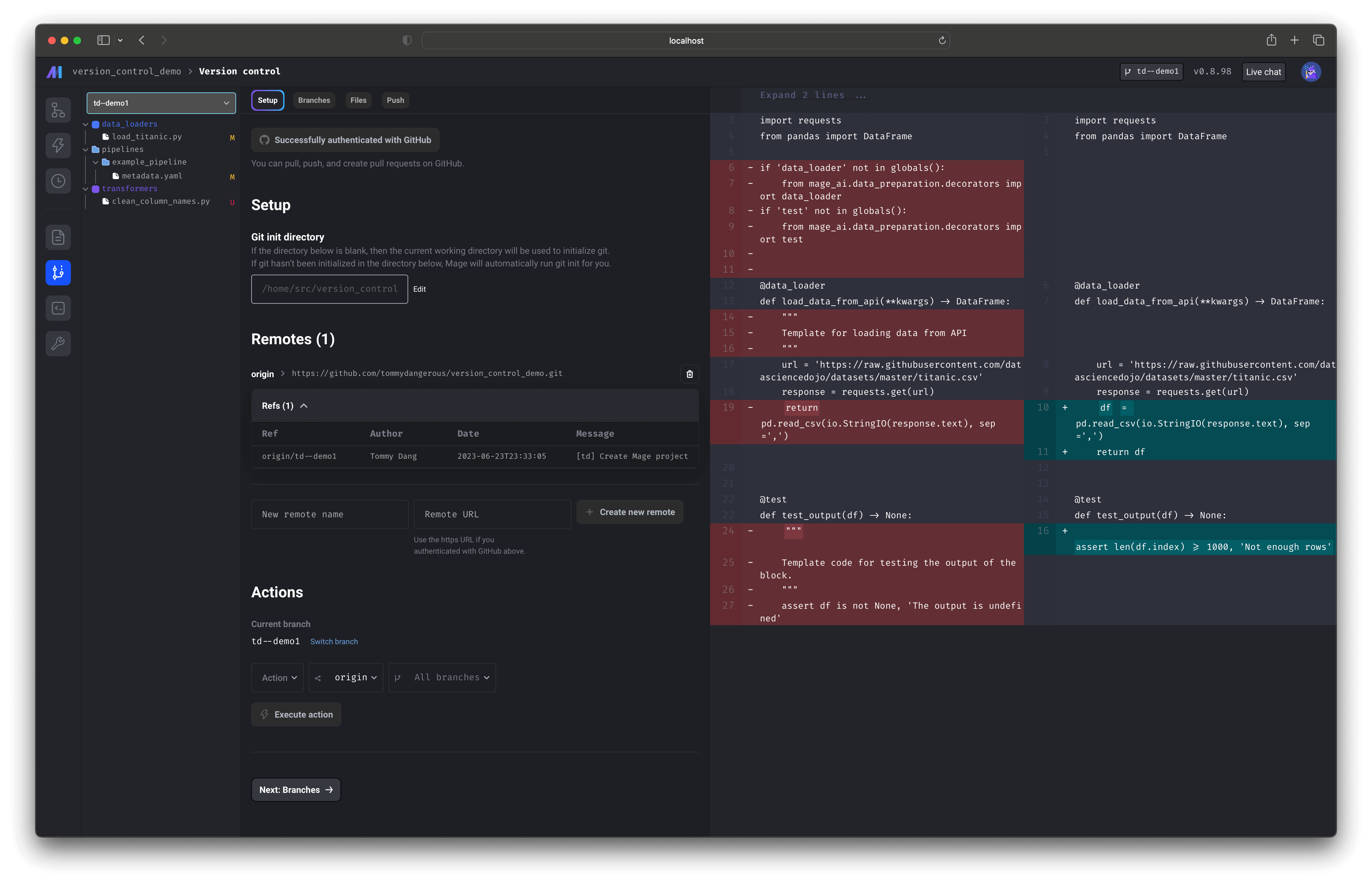
Version control application
Support all Git operations through UI. Authenticate with GitHub then pull from a remote repository, push local changes to a remote repository, and create pull requests for a remote repository.
Doc: https://docs.mage.ai/production/data-sync/github
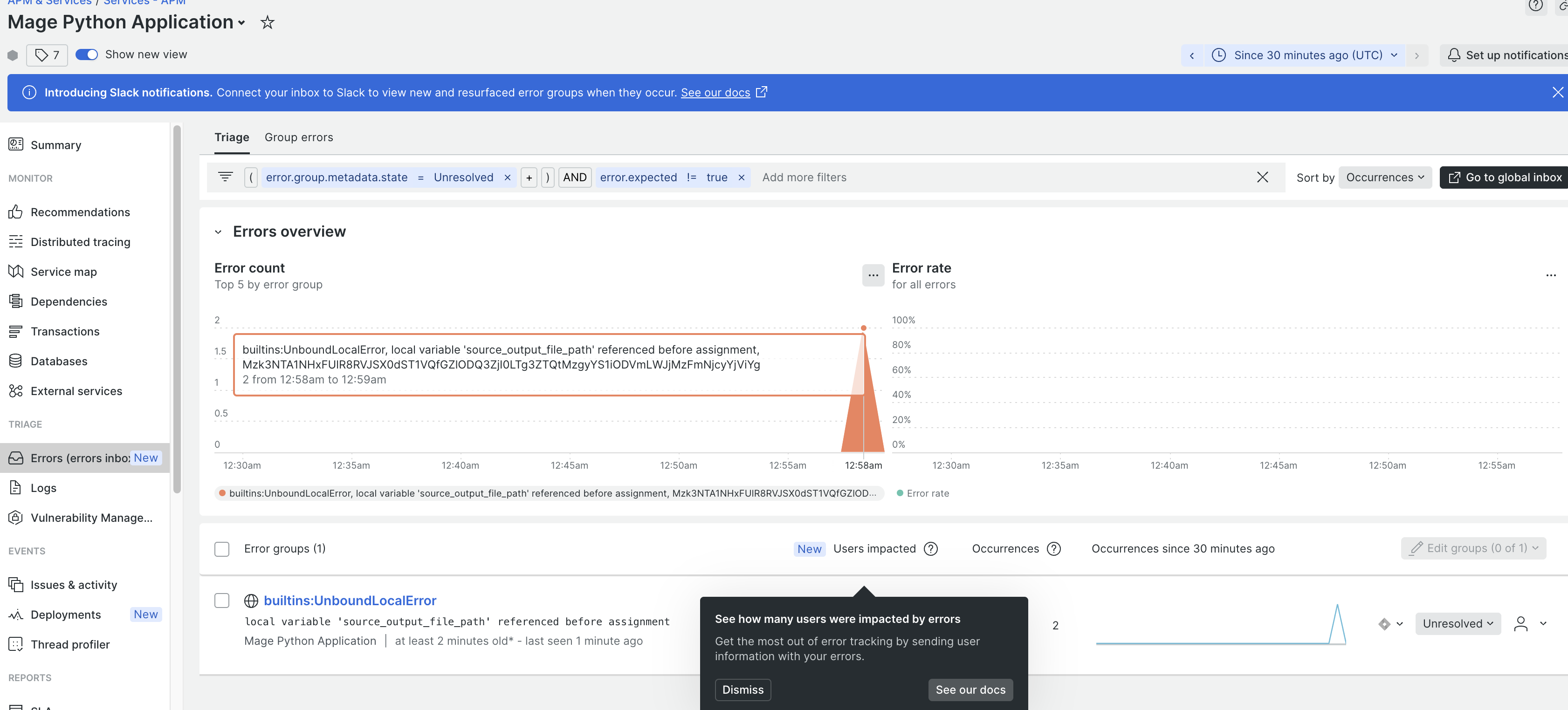
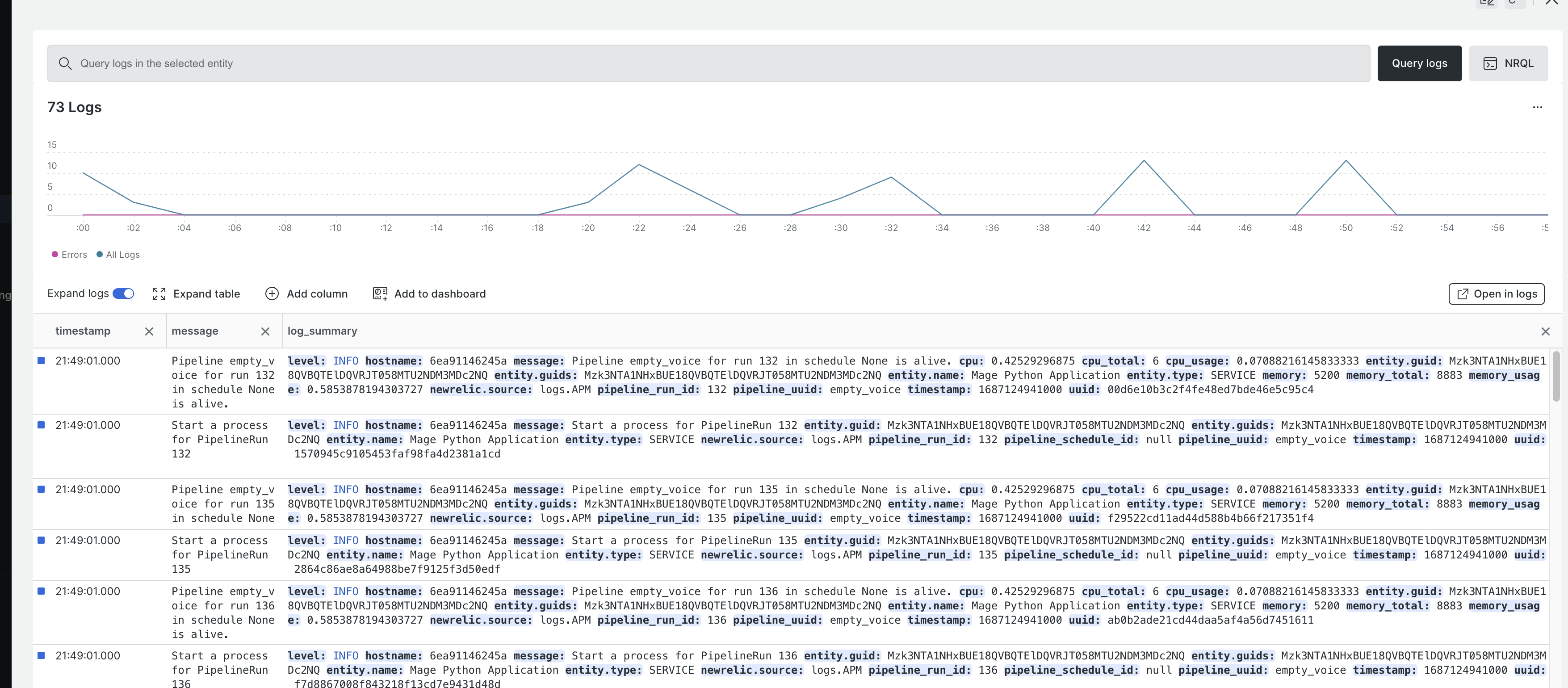
New Relic monitoring
- Set the
ENABLE_NEW_RELICenvironment variable to enable or disable new relic monitoring. - User need to follow new relic guide to create configuration file with license_key and app name.
Doc: https://docs.mage.ai/production/observability/newrelic
Authentication
Active Directory OAuth
Enable signing in with Microsoft Active Directory account in Mage.
Doc: https://docs.mage.ai/production/authentication/microsoft
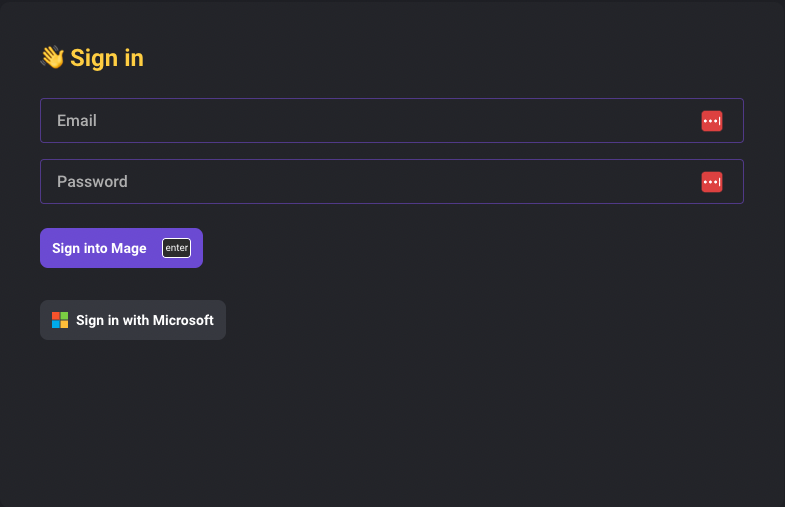
LDAP
https://docs.mage.ai/production/authentication/overview#ldap
- Update default LDAP user access from editor to no access. Add an environment variable
LDAP_DEFAULT_ACCESSso that the default access can be customized.
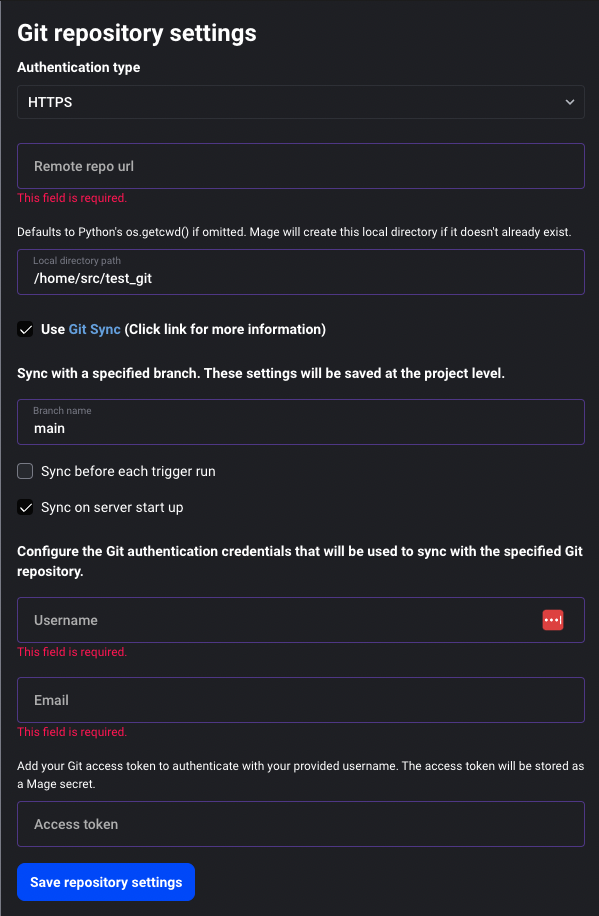
Add option to sync from Git on server start
There are two ways to configure Mage to sync from Git on server start
- Toggle
Sync on server start upoption in Git settings UI - Set
GIT_SYNC_ON_STARTenvironment variable (options: 0 or 1)
Doc: https://docs.mage.ai/production/data-sync/git#git-settings-as-environment-variables
Data integration pipeline
Mode Analytics Source
Shout out to Mohamad Balouza for his contribution of adding the Mode Analytics source to Mage data integration pipeline.
OracleDB Destination
MinIO support for S3 in Data integrations pipeline
Support using S3 source to connect to MinIO by configuring the aws_endpoint in the config.
Bug fixes and improvements
-
Snowflake: Use
TIMESTAMP_TZas column type for snowflake datetime column. - BigQuery: Not require key file for BigQuery source and destination. When Mage is deployed on GCP, it can use the service account to authenticate.
- Google Cloud Storage: Allow authenticating with Google Cloud Storage using service account
-
MySQL
- Fix inserting DOUBLE columns into MySQL destination
- Fix comparing datetime bookmark column in MySQL source
- Use backticks to wrap column name in MySQL
- MongoDB source: Add authSource and authMechanism options for MongoDB source.
- Salesforce source: Fix loading sample data for Salesforce source
- Improve visibility into non-functioning "test connection" and "load sample data" features for integration pipelines:
- Show unsupported error is "Test connection" is not implemented for an integration source.
- Update error messaging for "Load sample data" to let user know that it may not be supported for the currently selected integration source.
- Interpolate pipeline name and UUID in data integration pipelines. Doc: https://docs.mage.ai/data-integrations/configuration#variable-names
SQL block
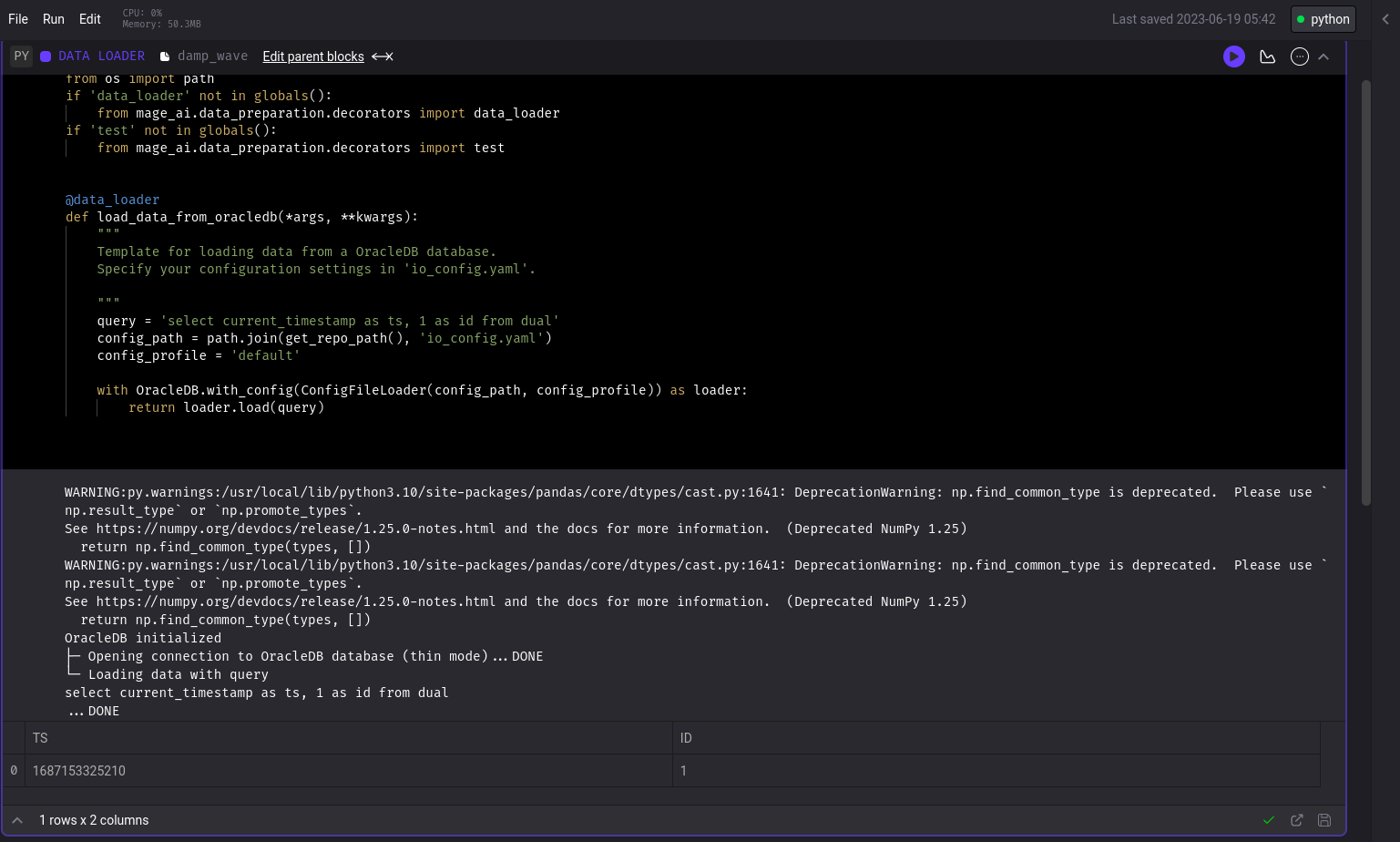
OracleDB Loader Block
Added OracleDB Data Loader block
Bug fixes
-
MSSQL: Fix MSSQL sql block schema.
Schemawas not properly set when checking table existence. Usedboas the default schema if no schema is set. - Trino: Fix inserting datetime column into Trino
- BigQuery: Throw exception in BigQuery SQL block
- ClickHouse: Support automatic table creation for ClickHouse data exporter
DBT block
DBT ClickHouse
Shout out to Daesgar for his contribution of adding support running ClickHouse DBT models in Mage.
Add DBT generic command block
Add a DBT block that can run any generic command
Bug fixes and improvements
- Fix bug: Running DBT block preview would sometimes not use sample limit amount.
- Fix bug: Existing upstream block would get overwritten when adding a dbt block with a ref to that existing upstream block.
- Fix bug: Duplicate upstream block added when new block contains upstream block ref and upstream block already exists.
- Use UTF-8 encoding when logging output from DBT blocks.
Notebook improvements
-
Turn on output to logs when running a single block in the notebook
-
When running a block in the notebook, provide an option to only run the upstream blocks that haven’t been executed successfully.
-
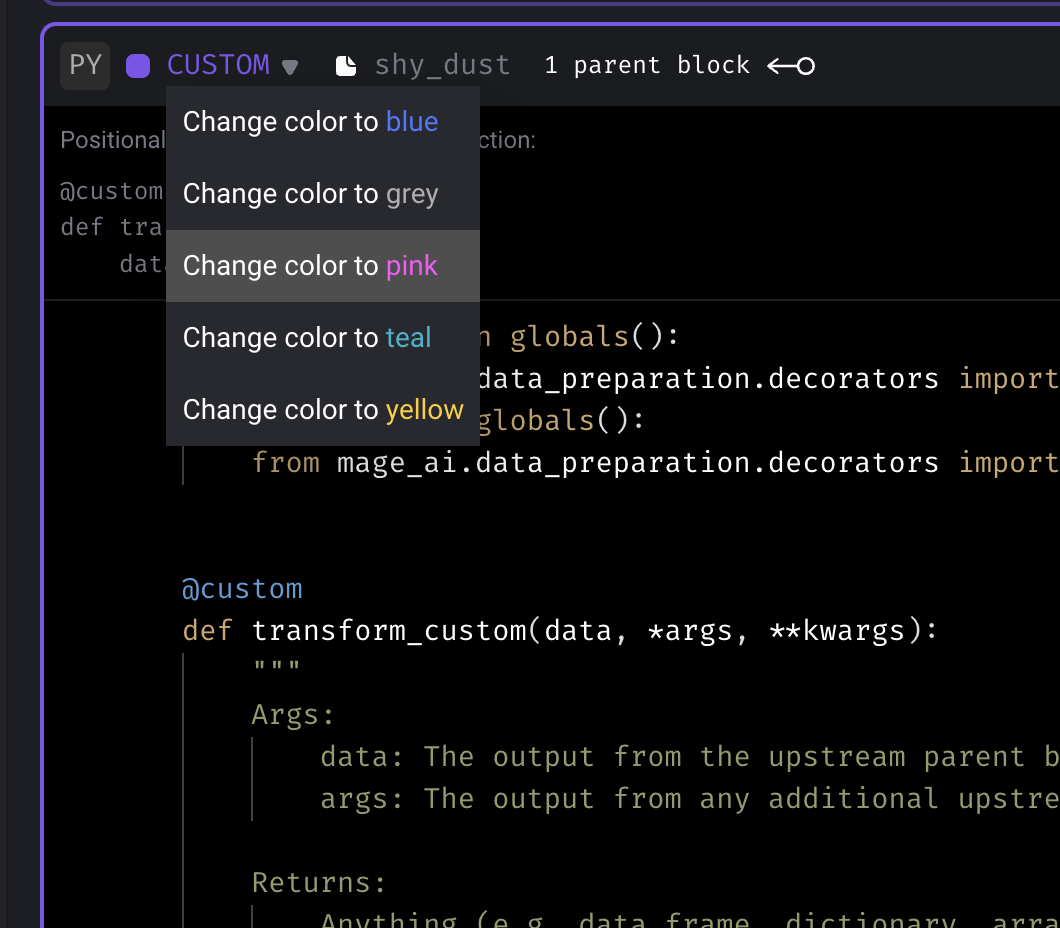
Change the color of a custom block from the UI.
-
Show what pipelines are using a particular block
- Show block settings in the sidekick when selecting a block
- Show which pipelines a block is used in
- Create a block cache class that stores block to pipeline mapping
-
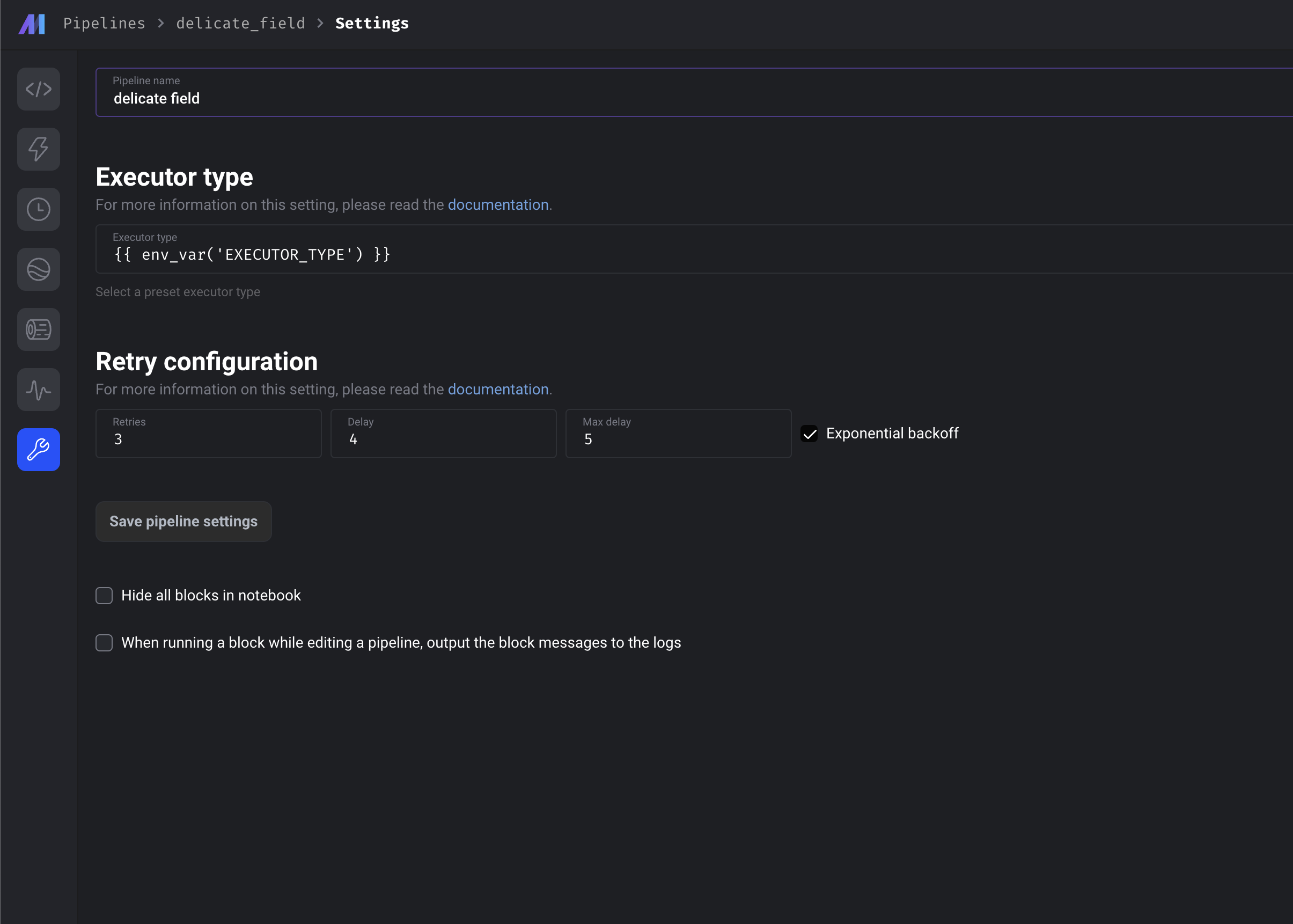
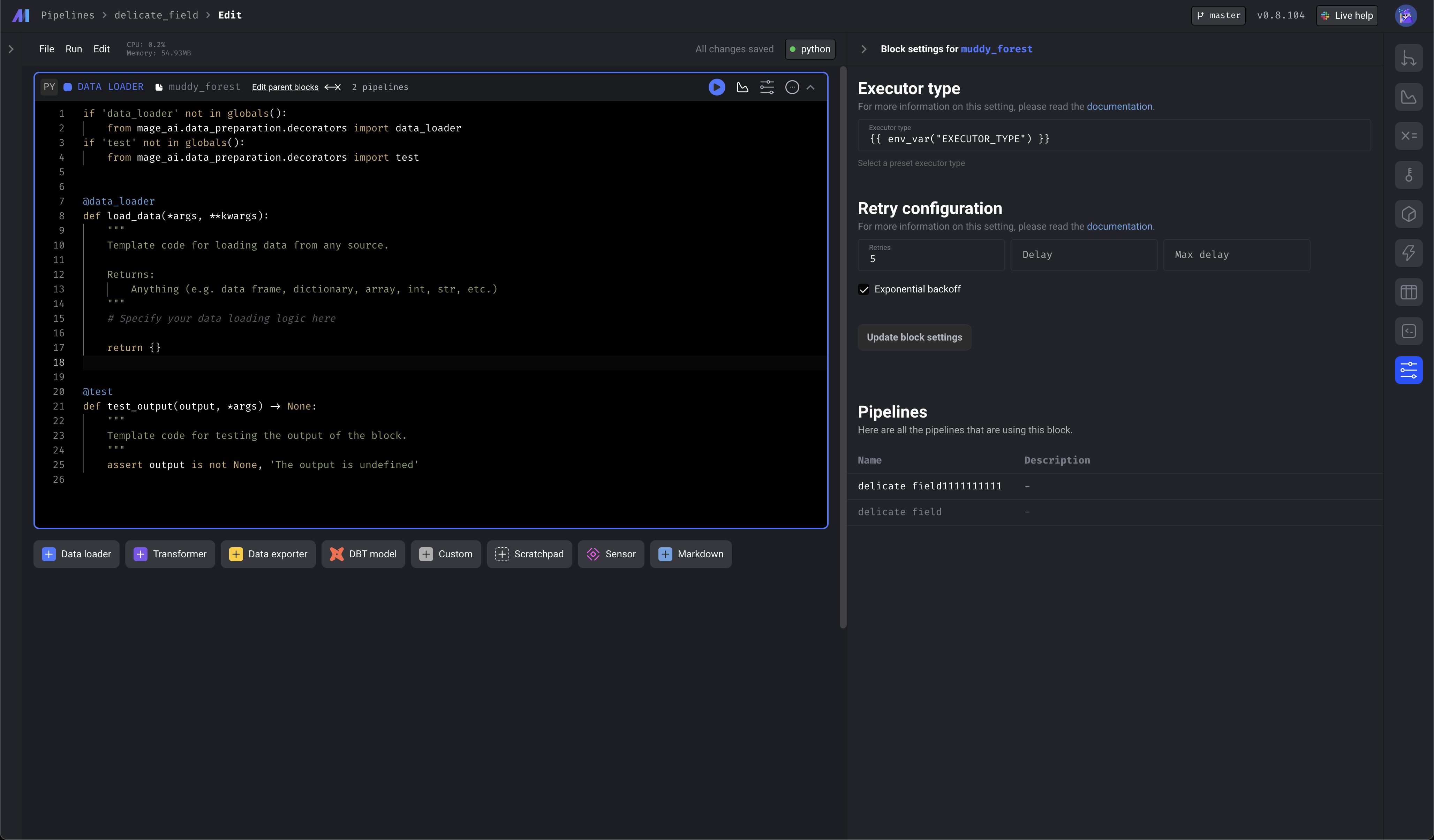
Enhanced pipeline settings page and block settings page
- Edit pipeline and block executor type and interpolate
- Edit pipeline and block retry config from the UI
- Edit block name and color from block settings
-
Enhance dependency tree node to show callbacks, conditionals, and extensions
-
Save trigger from UI to code
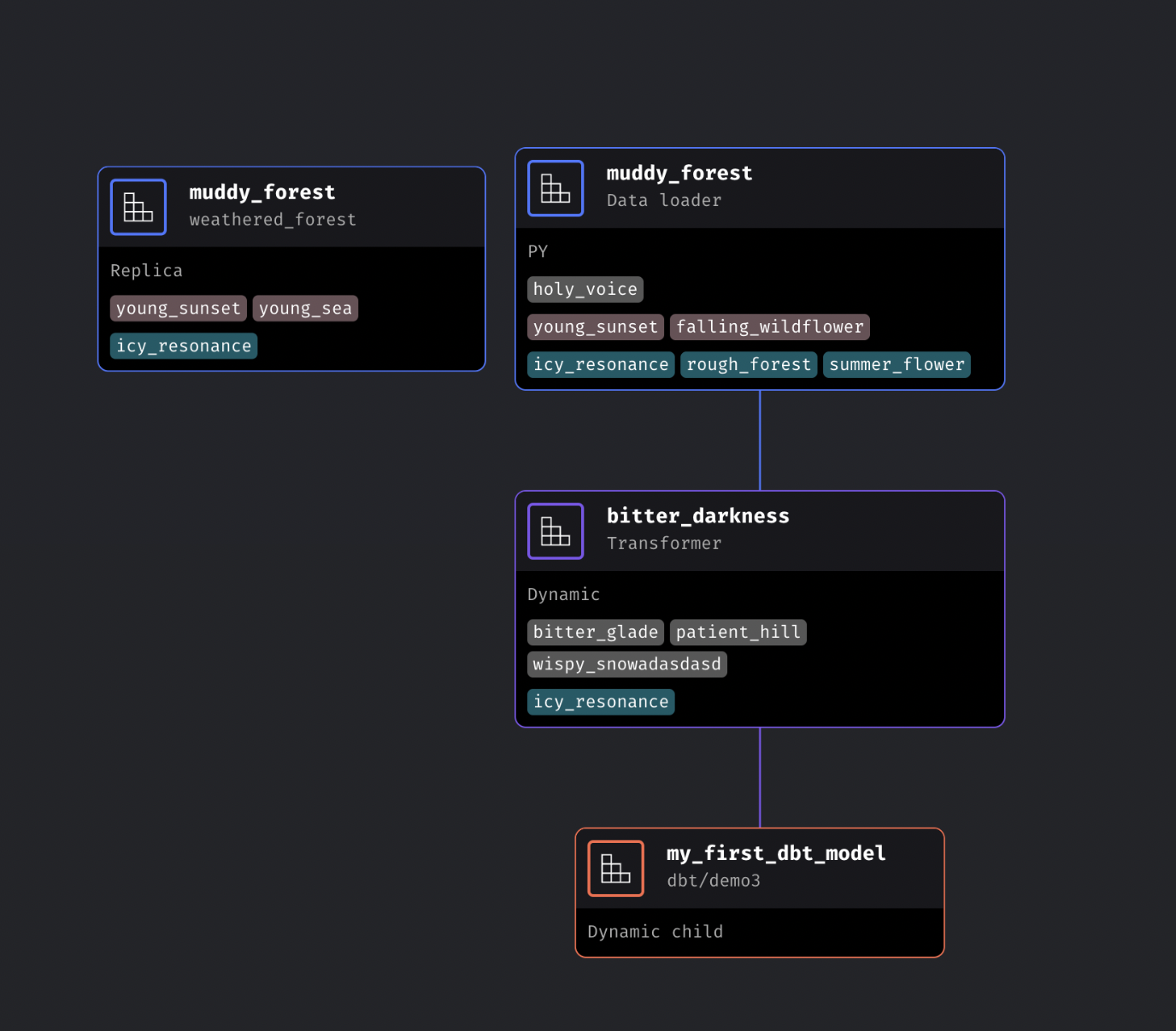
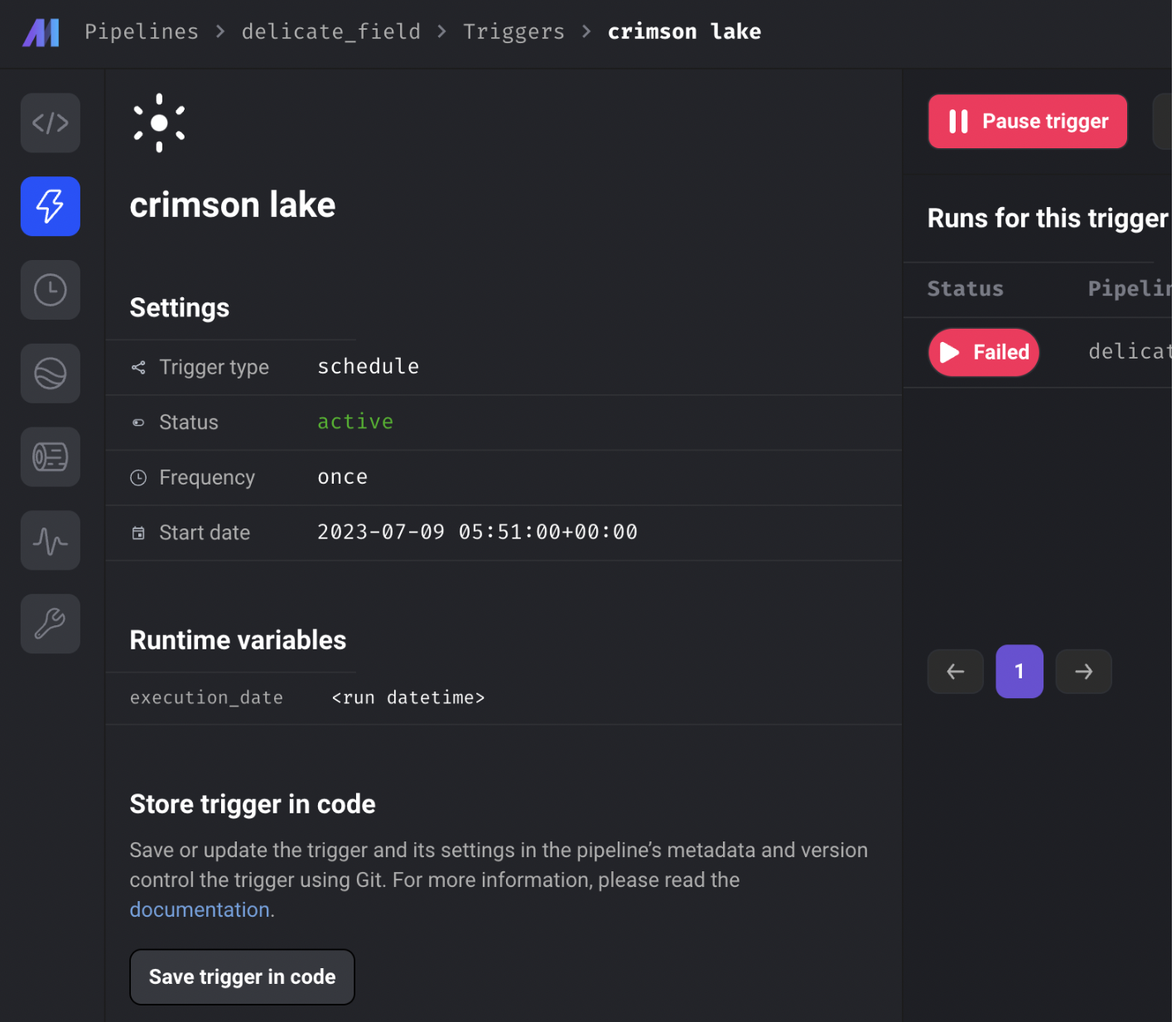
Cloud deployment
-
Allow setting service account name for k8s executor
- Example k8s executor config:
k8s_executor_config: resource_limits: cpu: 1000m memory: 2048Mi resource_requests: cpu: 500m memory: 1024Mi service_account_name: custom_service_account_name -
Support customizing the timeout seconds in GCP cloud run config.
- Example config
gcp_cloud_run_config: path_to_credentials_json_file: "/path/to/credentials_json_file" project_id: project_id timeout_seconds: 600 -
Check ECS task status after running the task.
Streaming pipeline
- Fix copy output in streaming pipeline. Catch deepcopy error (
TypeError: cannot pickle '_thread.lock' object in the deepcopy from the handle_batch_events_recursively) and fallback to copy method.
Spark pipeline
- Fix an issue with setting custom Spark pipeline config.
- Fix testing Spark DataFrame. Pass the correct Spark DataFrame to the test method.
Other bug fixes & polish
-
Add json value macro. Example usage:
"{{ json_value(aws_secret_var('test_secret_key_value'), 'k1') }}" -
Allow slashes in block_uuid when downloading block output. The regex for the block output download endpoint would not capture block_uuids with slashes in them, so this fixes that.
-
Fix renaming block.
-
Fix user auth when disable notebook edits is enabled.
-
Allow JWT_SECRET to be modified via env var. The
JWT_SECRETfor encoding and decoding access tokens was hardcoded, the fix allows users to update it through an environment variable. -
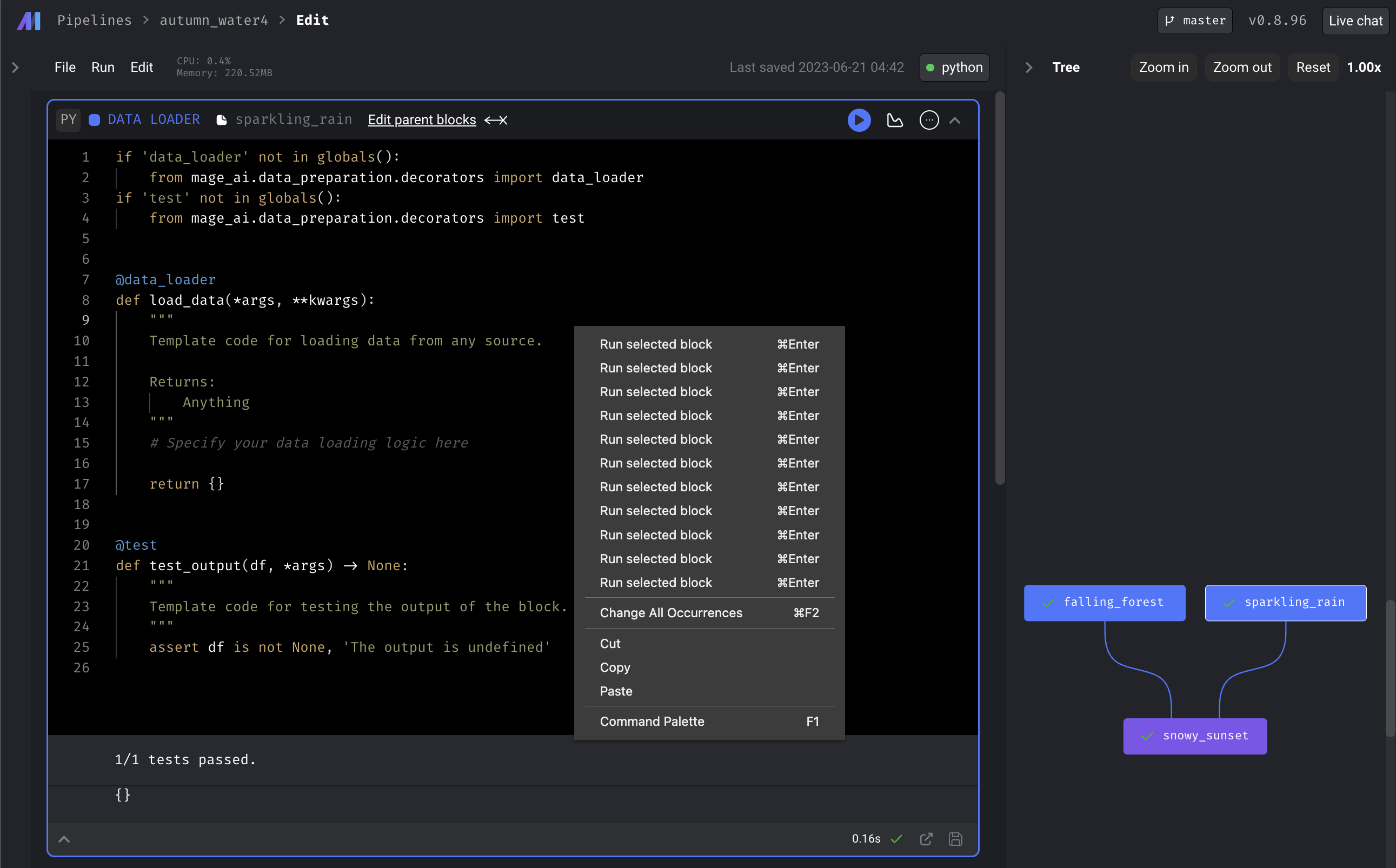
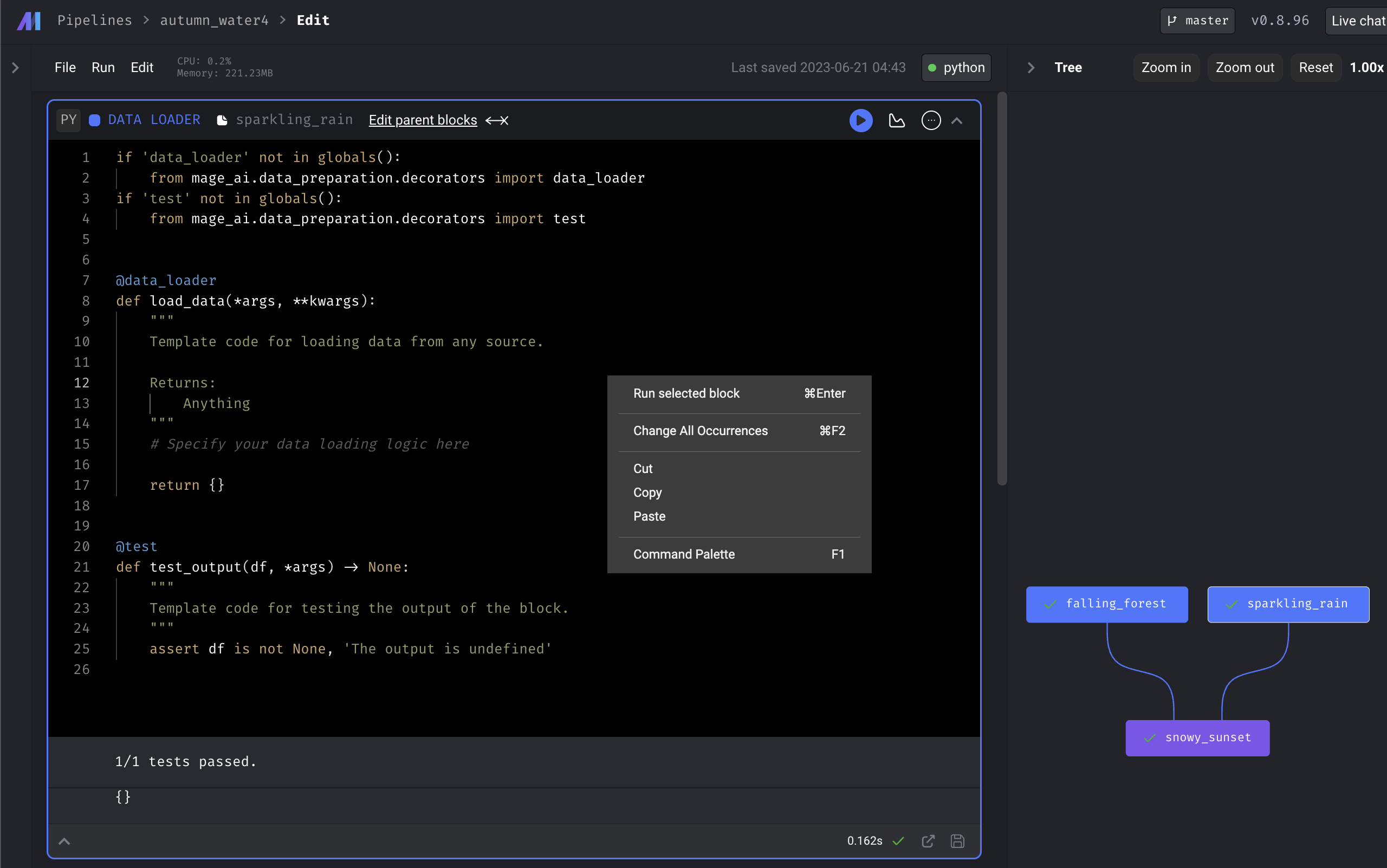
Hide duplicate shortcut items in editor context menu
- Before (after running the block a few times and removing/adding block connections):
- After (after following the same steps and running the block a few times and removing/adding block connections):
-
When changing the name of a block or creating a new block, auto-create non-existent folders if the block name is using nested block names.
-
Fix trigger count in pipeline dashboard
-
Fix copy text for secrets
-
Fix git sync
asyncioissue -
Fix Circular Import when importing
get_secret_valuemethod -
Shorten branch name in the header. If branch name is greater than 21 characters, show ellipsis.
-
Replace hard-to-read dark blue font in code block output with much more legible yellow font.
-
Show error popup if error occurs when updating pipeline settings.
-
Update tree node when block status changes
-
Prevent sending notification multiple times for multiple block failures
Published by thomaschung408 over 1 year ago

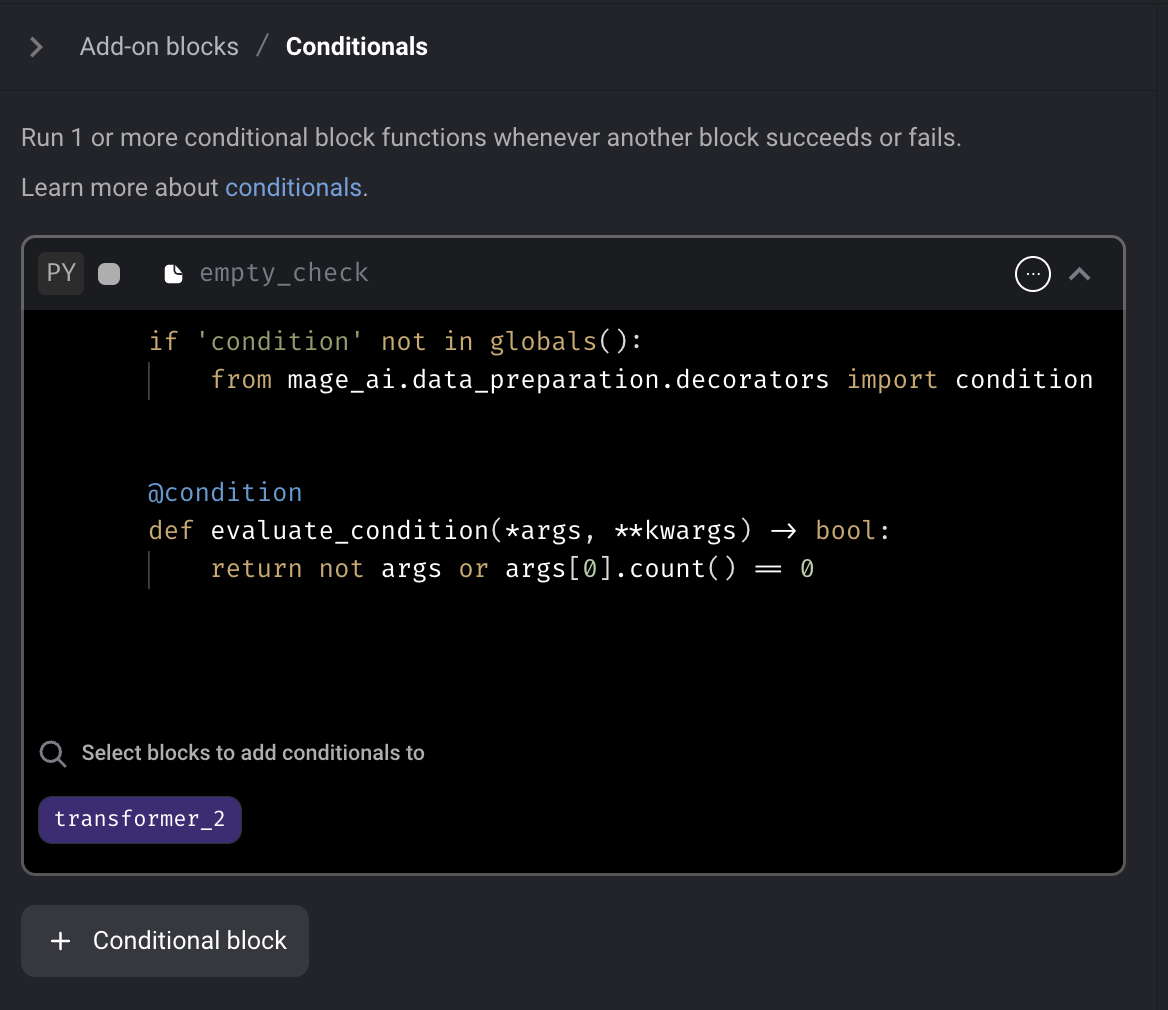
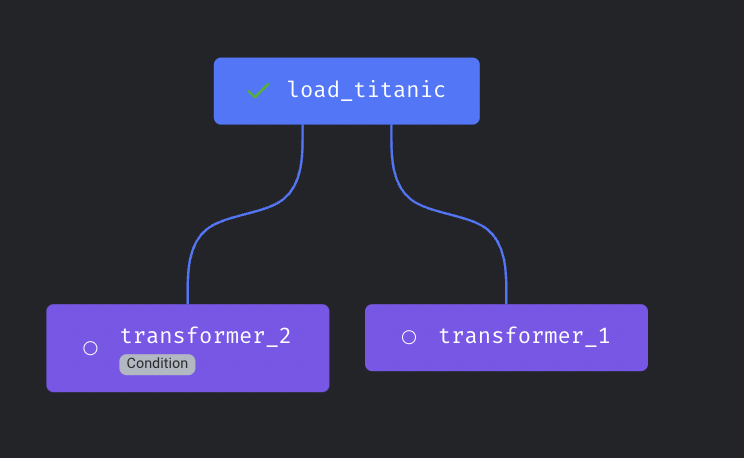
Conditional block
Add conditional block to Mage. The conditional block is an "Add-on" block that can be added to an existing block within a pipeline. If the conditional block evaluates as False, the parent block will not be executed.
Doc: https://docs.mage.ai/development/blocks/conditionals/overview
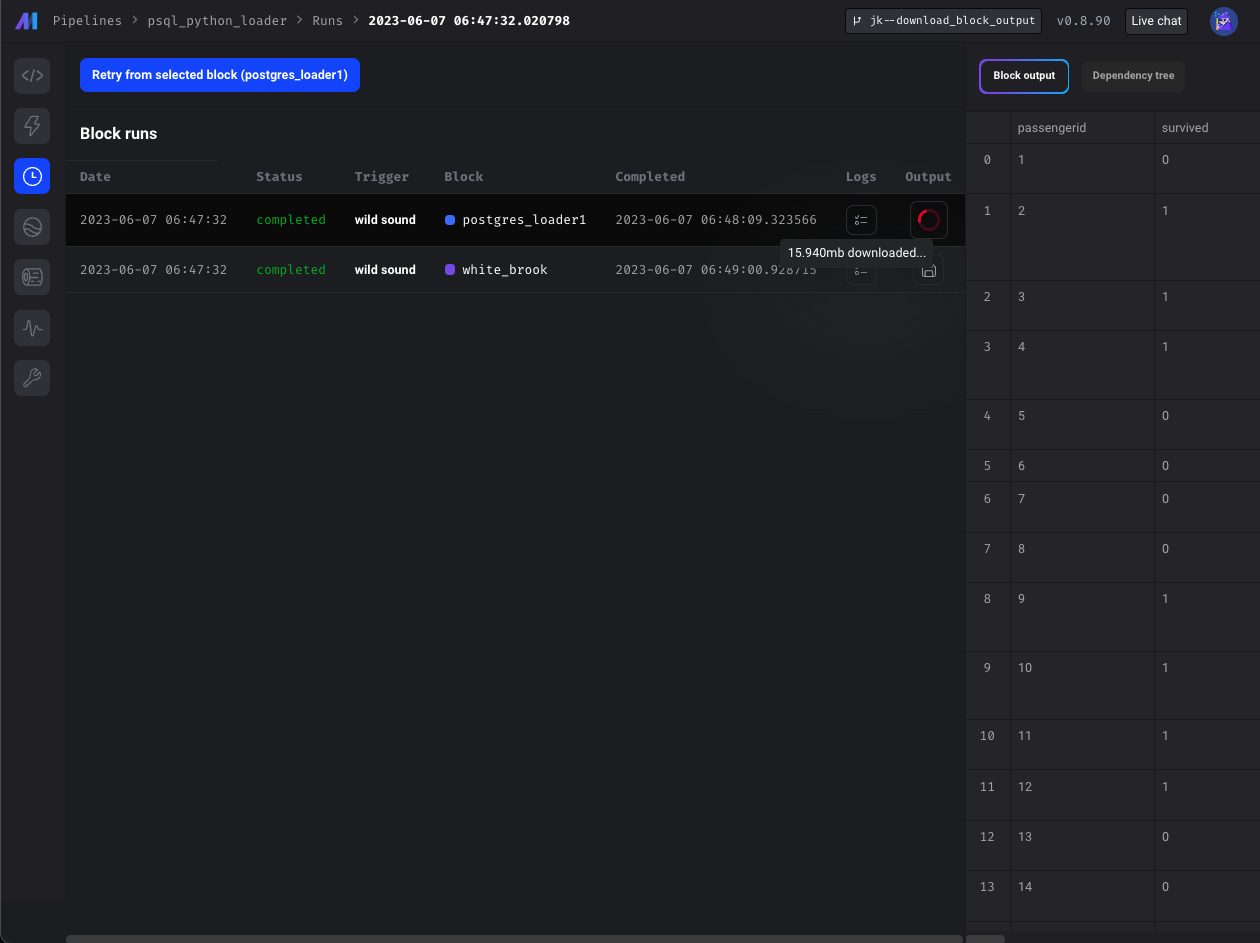
Download block output
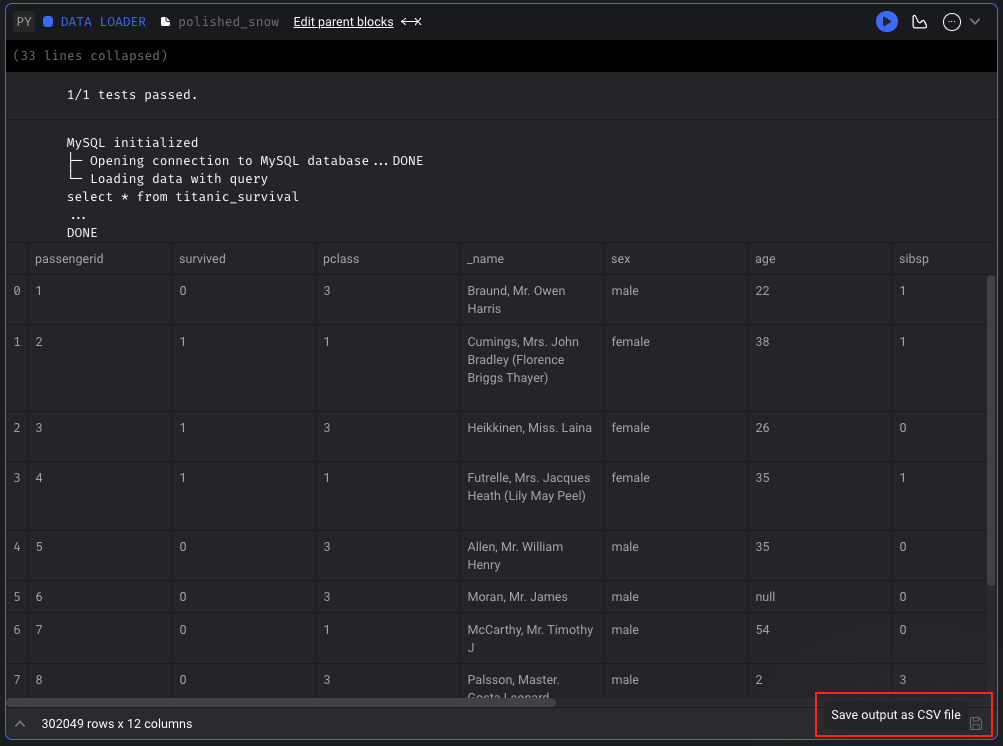
For standard pipelines (not currently supported in integration or streaming pipelines), you can save the output of a block that has been run as a CSV file. You can save the block output in Pipeline Editor page or Block Runs page.
Doc: https://docs.mage.ai/orchestration/pipeline-runs/saving-block-output-as-csv
Customize Pipeline level spark config
Mage supports customizing Spark session for a pipeline by specifying the spark_config in the pipeline metadata.yaml file. The pipeline level spark_config will override the project level spark_config if specified.
Doc: https://docs.mage.ai/integrations/spark-pyspark#custom-spark-session-at-the-pipeline-level
Data integration pipeline
Oracle DB source
Download file data in the API source
Doc: https://github.com/mage-ai/mage-ai/tree/master/mage_integrations/mage_integrations/sources/api
Personalize notification messages
Users can customize the notification templates of different channels (slack, email, etc.) in project metadata.yaml. Hare are the supported variables that can be interpolated in the message templates: execution_time , pipeline_run_url , pipeline_schedule_id, pipeline_schedule_name, pipeline_uuid
Example config in project's metadata.yaml
notification_config:
slack_config:
webhook_url: "{{ env_var('MAGE_SLACK_WEBHOOK_URL') }}"
message_templates:
failure:
details: >
Failure to execute pipeline {pipeline_run_url}.
Pipeline uuid: {pipeline_uuid}. Trigger name: {pipeline_schedule_name}.
Test custom message."

Doc: https://docs.mage.ai/production/observability/alerting-slack#customize-message-templates
Support MSSQL and MySQL as the database engine
Mage stores orchestration data, user data, and secrets data in a database. In addition to SQLite and Postgres, Mage supports using MSSQL and MySQL as the database engine now.
MSSQL docs:
- https://docs.mage.ai/production/databases/default#mssql
- https://docs.mage.ai/getting-started/setup#using-mssql-as-database
MySQL docs:
- https://docs.mage.ai/production/databases/default#mysql
- https://docs.mage.ai/getting-started/setup#using-mysql-as-database
Add MinIO and Wasabi support via S3 data loader block
Mage supports connecting to MinIO and Wasabi by specifying the AWS_ENDPOINT field in S3 config now.
Doc: https://docs.mage.ai/integrations/databases/S3#minio-support
Use dynamic blocks with replica blocks
To maximize block reuse, you can use dynamic and replica blocks in combination.
- https://docs.mage.ai/design/blocks/dynamic-blocks
- https://docs.mage.ai/design/blocks/replicate-blocks
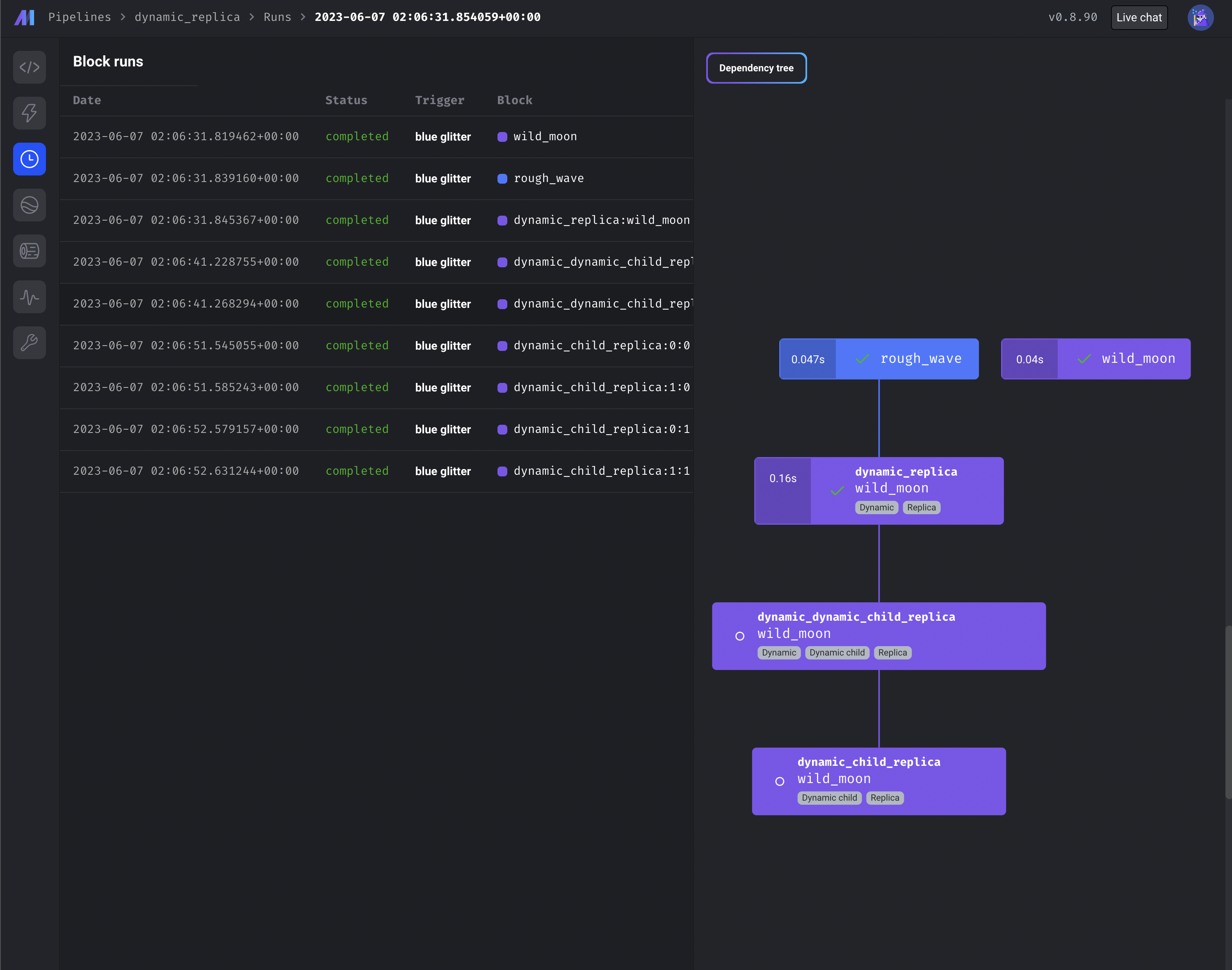
Other bug fixes & polish
- The command
CREATE SCHEMA IF NOT EXISTSis not supported by MSSQL. Provided a default command in BaseSQL -> build_create_schema_command, and an overridden implementation in MSSQL -> build_create_schema_command containing compatible syntax. (Kudos to gjvanvuuren) - Fix streaming pipeline
kwargspassing so that RabbitMQ messages can be acknowledged correctly. - Interpolate variables in streaming configs.
- Git integration: Create known hosts if it doesn't exist.
- Do not create duplicate triggers when DB query fails on checking existing triggers.
- Fix bug: when there are multiple downstream replica blocks, those blocks are not getting queued.
- Fix block uuid formatting for logs.
- Update WidgetPolicy to allow editing and creating widgets without authorization errors.
- Update sensor block to accept positional arguments.
- Fix variables for GCP Cloud Run executor.
- Fix MERGE command for Snowflake destination.
- Fix encoding issue of file upload.
- Always delete the temporary DBT profiles dir to prevent file browser performance degrade.
Published by thomaschung408 over 1 year ago

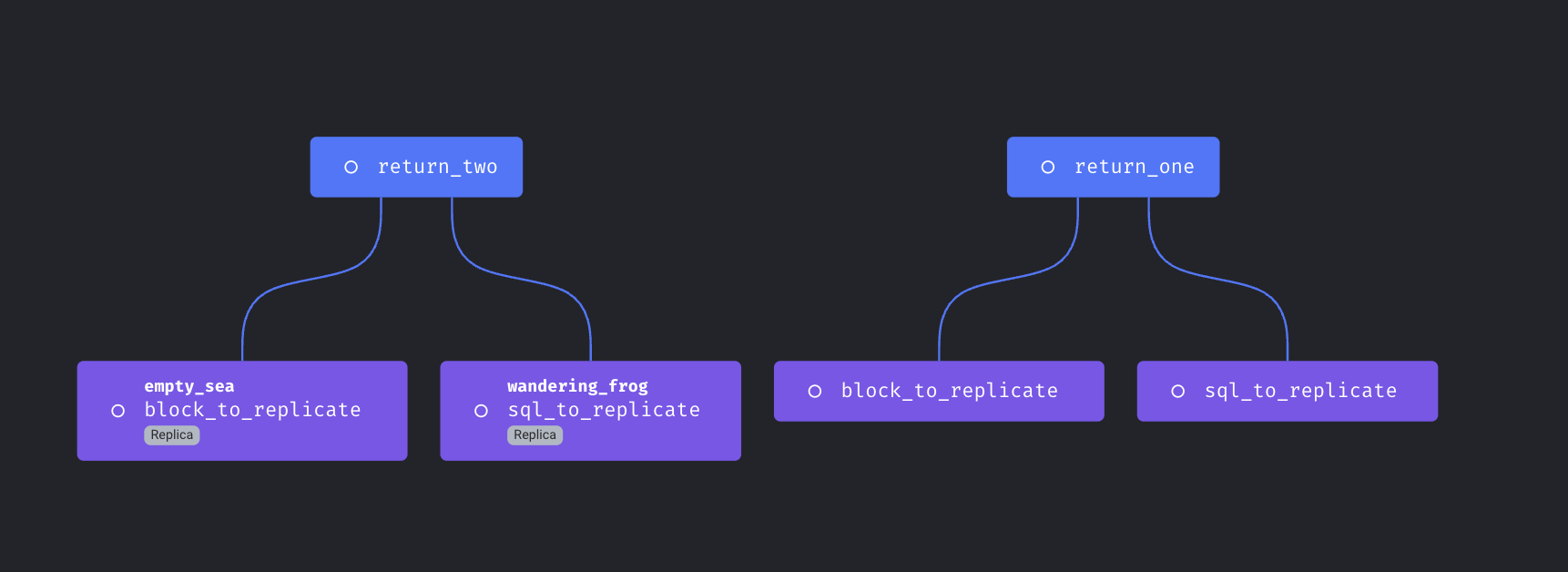
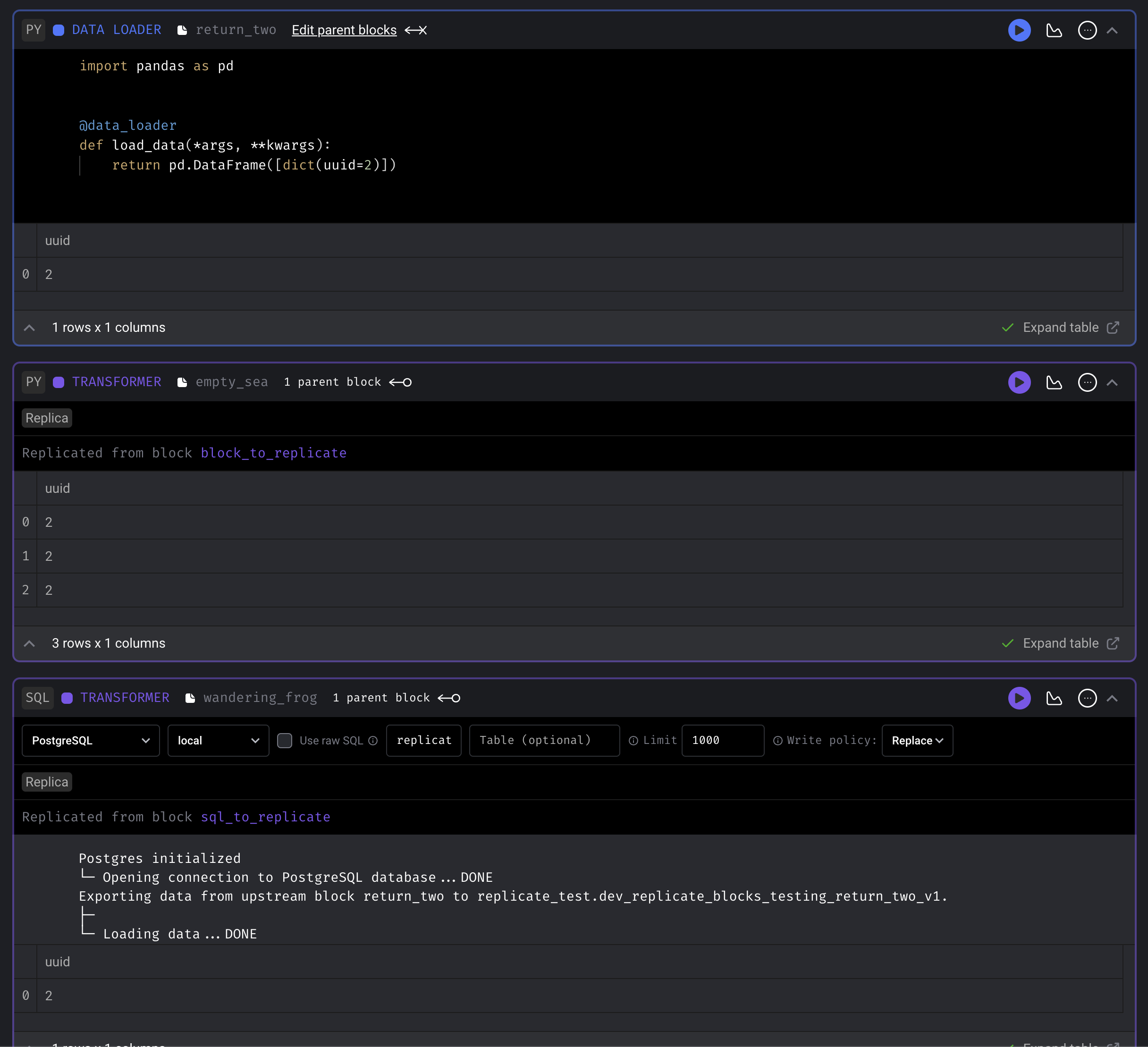
Replicate blocks
Support reusing same block multiple times in a single pipeline.
Doc: https://docs.mage.ai/design/blocks/replicate-blocks
Spark on Yarn
Support running Spark code on Yarn cluster with Mage.
Doc: https://docs.mage.ai/integrations/spark-pyspark#hadoop-and-yarn-cluster-for-spark
Customize retry config
Mage supports configuring automatic retry for block runs with the following ways
- Add
retry_configto project’smetadata.yaml. Thisretry_configwill be applied to all block runs. - Add
retry_configto the block config in pipeline’smetadata.yaml. The block levelretry_configwill override the globalretry_config.
Example config:
retry_config:
# Number of retry times
retries: 0
# Initial delay before retry. If exponential_backoff is true,
# the delay time is multiplied by 2 for the next retry
delay: 5
# Maximum time between the first attempt and the last retry
max_delay: 60
# Whether to use exponential backoff retry
exponential_backoff: true
Doc: https://docs.mage.ai/orchestration/pipeline-runs/retrying-block-runs#automatic-retry
DBT improvements
-
When running DBT block with language YAML, interpolate and merge the user defined --vars in the block’s code into the variables that Mage automatically constructs
- Example block code of different formats
--select demo/models --vars '{"demo_key": "demo_value", "date": 20230101}' --select demo/models --vars {"demo_key":"demo_value","date":20230101} --select demo/models --vars '{"global_var": {{ test_global_var }}, "env_var": {{ test_env_var }}}' --select demo/models --vars {"refresh":{{page_refresh}},"env_var":{{env}}} -
Support
dbt_project.ymlcustom project names and custom profile names that are different than the DBT folder name -
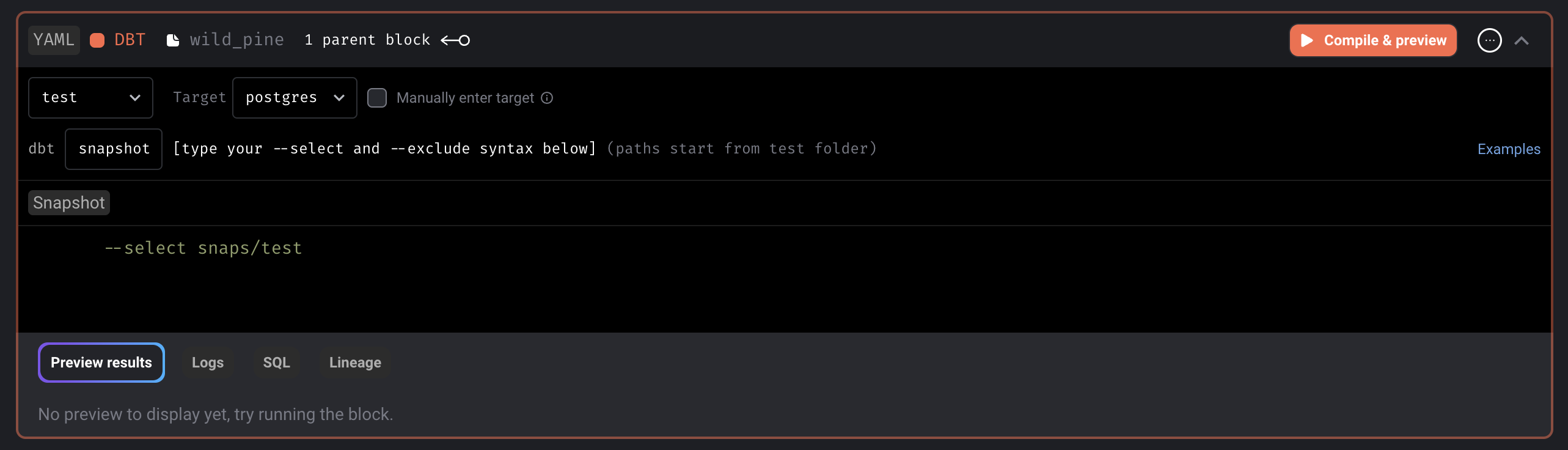
Allow user to configure block to run DBT snapshot
Dynamic SQL block
Support using dynamic child blocks for SQL blocks
Doc: https://docs.mage.ai/design/blocks/dynamic-blocks#dynamic-sql-blocks
Run blocks concurrently in separate containers on Azure
If your Mage app is deployed on Microsoft Azure with Mage’s terraform scripts, you can choose to launch separate Azure container instances to execute blocks.
Run the scheduler and the web server in separate containers or pods
- Run scheduler only:
mage start project_name --instance-type scheduler - Run web server only:
mage start project_name --instance-type web_server- web server can be run in multiple containers or pods
- Run both server and scheduler:
mage start project_name --instance-type server_and_scheduler
Support all operations on folder
Support “Add”, “Rename”, “Move”, “Delete” operations on folder.
Configure environments for triggers in code
Allow specifying envs value to apply triggers only in certain environments.
Example:
triggers:
- name: test_example_trigger_in_prod
schedule_type: time
schedule_interval: "@daily"
start_time: 2023-01-01
status: active
envs:
- prod
- name: test_example_trigger_in_dev
schedule_type: time
schedule_interval: "@hourly"
start_time: 2023-03-01
status: inactive
settings:
skip_if_previous_running: true
allow_blocks_to_fail: true
envs:
- dev
Doc: https://docs.mage.ai/guides/triggers/configure-triggers-in-code#create-and-configure-triggers
Replace current logs table with virtualized table for better UI performance
- Use virtual table to render logs so that loading thousands of rows won't slow down browser performance.
- Fix formatting of logs table rows when a log is selected (the log detail side panel would overly condense the main section, losing the place of which log you clicked).
- Pin logs page header and footer.
- Tested performance using Lighthouse Chrome browser extension, and performance increased 12 points.
Other bug fixes & polish
-
Add indices to schedule models to speed up DB queries.
-
“Too many open files issue”
- Check for "Too many open files" error on all pages calling "displayErrorFromReadResponse" util method (e.g. pipeline edit page), not just Pipelines Dashboard.
- Update terraform scripts to set the
ULIMIT_NO_FILEenvironment variable to increase maximum number of open files in Mage deployed on AWS, GCP and Azure.
-
Fix git_branch resource blocking page loads. The
git clonecommand could cause the entire app to hang if the host wasn't added to known hosts.git clonecommand is updated to run as a separate process with the timeout, so it won't block the entire app if it's stuck. -
Fix bug: when adding a block in between blocks in pipeline with two separate root nodes, the downstream connections are removed.
-
Fix DBT error:
KeyError: 'file_path'. Check forfile_pathbefore callingparse_attributesmethod to avoid KeyError. -
Improve the coding experience when working with Snowflake data provider credentials. Allow more flexibility in Snowflake SQL block queries. Doc: https://docs.mage.ai/integrations/databases/Snowflake#methods-for-configuring-database-and-schema
-
Pass parent block’s output and variables to its callback blocks.
-
Fix missing input field and select field descriptions in charts.
-
Fix bug: Missing values template chart doesn’t render.
-
Convert
numpy.ndarraytolistif column type is list when fetching input variables for blocks. -
Fix runtime and global variables not available in the keyword arguments when executing block with upstream blocks from the edit pipeline page.
View full Changelog
Published by thomaschung408 over 1 year ago

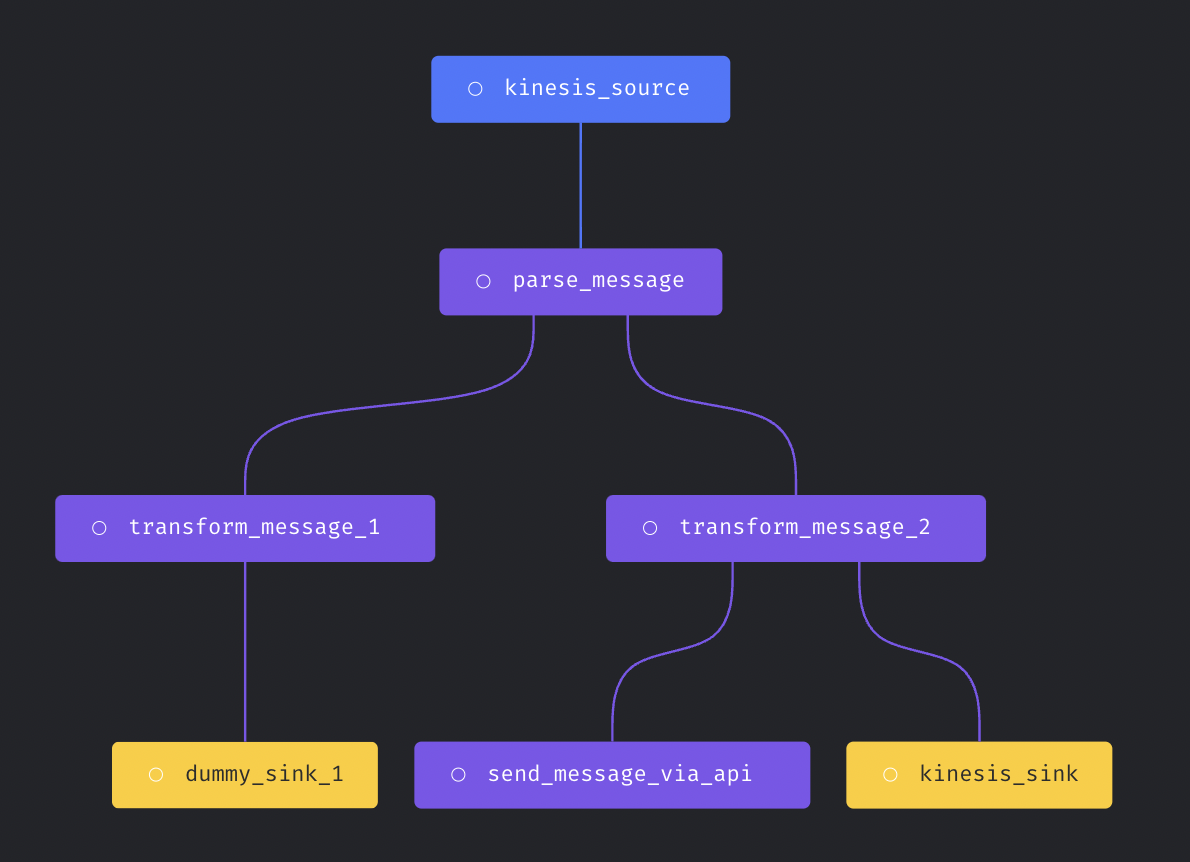
Support more complex streaming pipeline
More complex streaming pipeline is supported in Mage now. You can use more than transformer and more than one sinks in the streaming pipeline.
Here is an example streaming pipeline with multiple transformers and sinks.
Doc for streaming pipeline: https://docs.mage.ai/guides/streaming/overview
Custom Spark configuration
Allow using custom Spark configuration to create Spark session used in the pipeline.
spark_config:
# Application name
app_name: 'my spark app'
# Master URL to connect to
# e.g., spark_master: 'spark://host:port', or spark_master: 'yarn'
spark_master: 'local'
# Executor environment variables
# e.g., executor_env: {'PYTHONPATH': '/home/path'}
executor_env: {}
# Jar files to be uploaded to the cluster and added to the classpath
# e.g., spark_jars: ['/home/path/example1.jar']
spark_jars: []
# Path where Spark is installed on worker nodes,
# e.g. spark_home: '/usr/lib/spark'
spark_home: null
# List of key-value pairs to be set in SparkConf
# e.g., others: {'spark.executor.memory': '4g', 'spark.executor.cores': '2'}
others: {}
Doc for running PySpark pipeline: https://docs.mage.ai/integrations/spark-pyspark#standalone-spark-cluster
Data integration pipeline
DynamoDB source
New data integration source DynamoDB is added.
Bug fixes
- Use
timestamptzas data type for datetime column in Postgres destination. - Fix BigQuery batch load error.
Show file browser outside edit pipeline
Improved the file editor of Mage so that user can edit the files without going into a pipeline.
Add all file operations
Speed up writing block output to disk
Mage uses Polars to speed up writing block output (DataFrame) to disk, reducing the time of fetching and writing a DataFrame with 2 million rows from 90s to 15s.
Add default .gitignore
Mage automatically adds the default .gitignore file when initializing project
.DS_Store
.file_versions
.gitkeep
.log
.logs/
.preferences.yaml
.variables/
__pycache__/
docker-compose.override.yml
logs/
mage-ai.db
mage_data/
secrets/
Other bug fixes & polish
- Include trigger URL in slack alert.

- Fix race conditions for multiple runs within one second
- If DBT block is language YAML, hide the option to add upstream dbt refs
- Include event_variables in individual pipeline run retry
- Callback block
- Include parent block uuid in callback block kwargs
- Pass parent block’s output and variables to its callback blocks
- Delete GCP cloud run job after it's completed.
- Limit the code block output from print statements to avoid sending excessively large payload request bodies when saving the pipeline.
- Lock typing extension version to fix error
TypeError: Instance and class checks can only be used with @runtime protocols. - Fix git sync and also updates how we save git settings for users in the backend.
- Fix MySQL ssh tunnel: close ssh tunnel connection after testing connection.
View full Changelog
Published by thomaschung408 over 1 year ago

MongoDB code templates
Add code templates to fetch data from and export data to MongoDB.
Example MongoDB config in io_config.yaml :
version: 0.1.1
default:
MONGODB_DATABASE: database
MONGODB_HOST: host
MONGODB_PASSWORD: password
MONGODB_PORT: 27017
MONGODB_COLLECTION: collection
MONGODB_USER: user
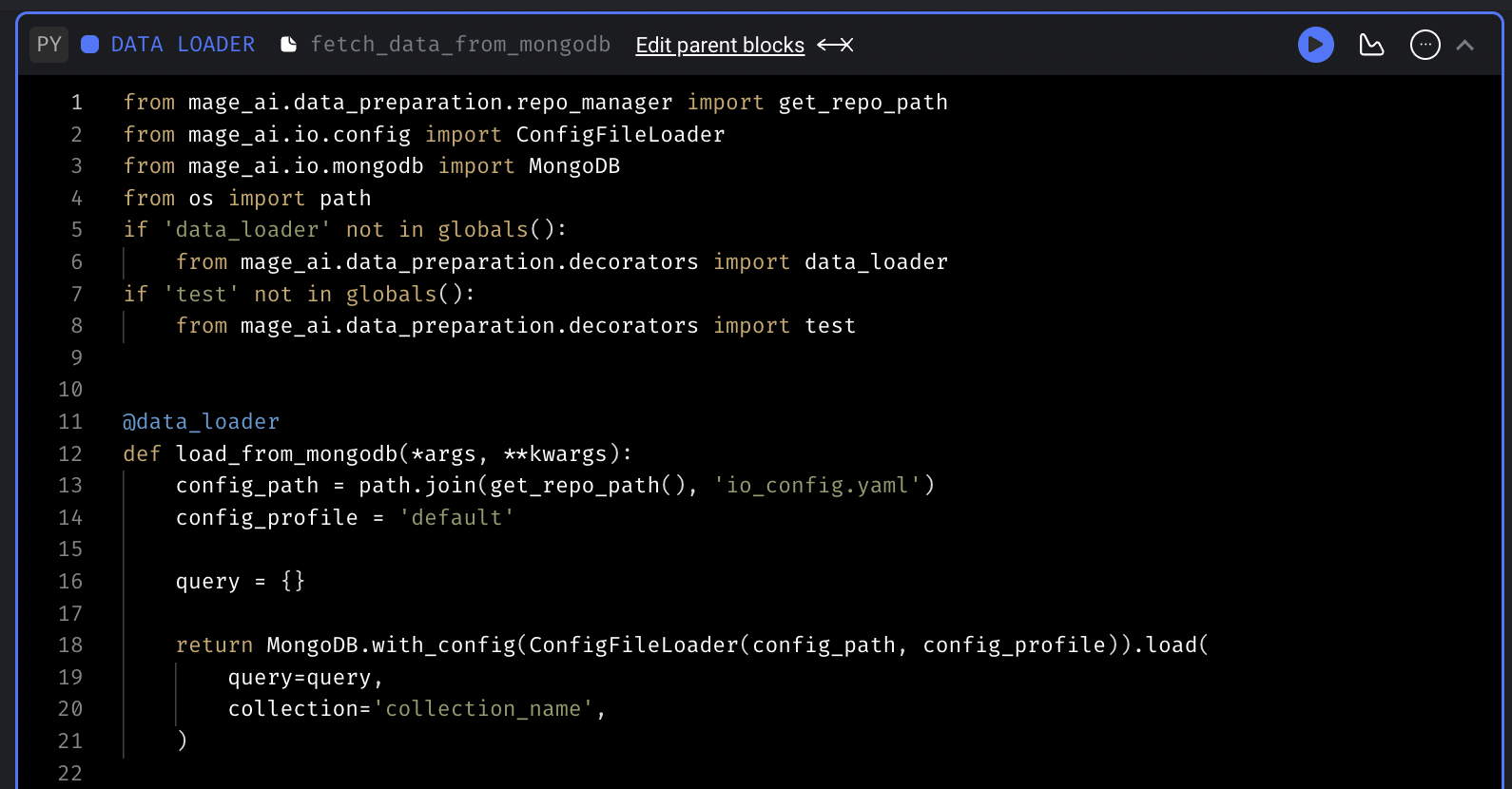
Data loader template
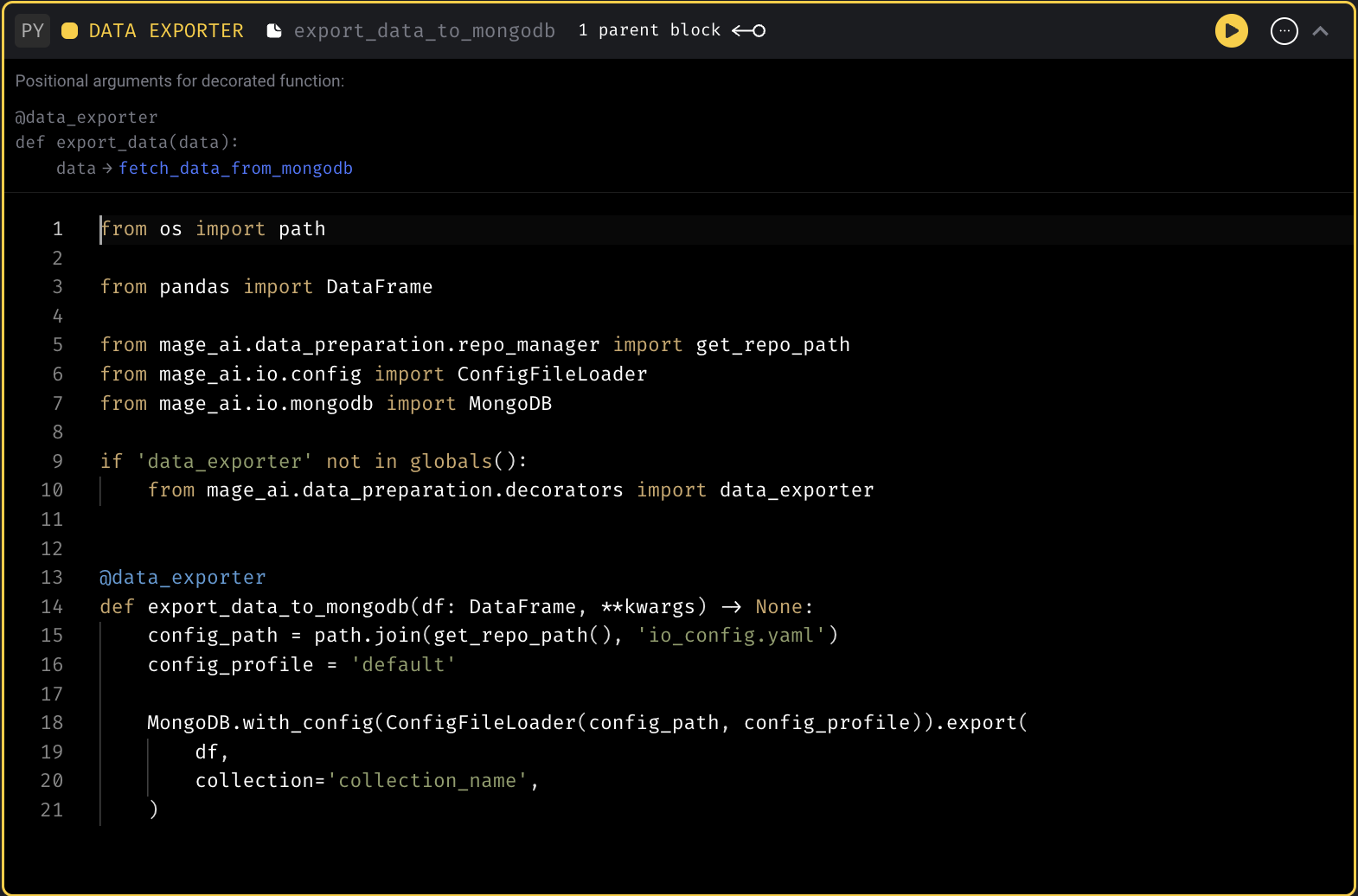
Data exporter template
Support using renv for R block
renv is installed in Mage docker image by default. User can use renv package to manage R dependency for your project.
Doc for renv package: https://cran.r-project.org/web/packages/renv/vignettes/renv.html
Run streaming pipeline in separate k8s pod
Support running streaming pipeline in k8s executor to scale up streaming pipeline execution.
It can be configured in pipeline metadata.yaml with executor_type field. Here is an example:
blocks:
- ...
- ...
executor_count: 1
executor_type: k8s
name: test_streaming_kafka_kafka
uuid: test_streaming_kafka_kafka
When cancelling the pipeline run in Mage UI, Mage will kill the k8s job.
DBT support for Spark
Support running Spark DBT models in Mage. Currently, only the connection method session is supported.
Follow this doc to set up Spark environment in Mage. Follow the instructions in https://docs.mage.ai/tutorials/setup-dbt to set up the DBT. Here is an example DBT Spark profiles.yml
spark_demo:
target: dev
outputs:
dev:
type: spark
method: session
schema: default
host: local
Doc for staging/production deployment
- Add doc for setting up the CI/CD pipeline to deploy Mage to staging and production environments: https://docs.mage.ai/production/ci-cd/staging-production/github-actions
- Provide example Github Action template for deployment on AWS ECS: https://github.com/mage-ai/mage-ai/blob/master/templates/github_actions/build_and_deploy_to_aws_ecs_staging_production.yml
Enable user authentication for multi-development environment
Update the multi-development environment to go through the user authentication flow. Multi-development environment is used to manage development instances on cloud.
Doc for multi-development environment: https://docs.mage.ai/developing-in-the-cloud/cloud-dev-environments/overview
Refined dependency graph
- Add buttons for zooming in/out of and resetting dependency graph.
- Add shortcut to reset dependency graph view (double-clicking anywhere on the canvas).
Add new block with downstream blocks connected
- If a new block is added between two blocks, include the downstream connection.
- If a new block is added after a block that has multiple downstream blocks, the downstream connections will not be added since it is unclear which downstream connections should be made.
- Hide Add transformer block button in integration pipelines if a transformer block already exists (Mage currently only supports 1 transformer block for integration pipelines).
Improve UI performance
- Reduce number of API requests made when refocusing browser.
- Decrease notebook CPU and memory consumption in the browser by removing unnecessary code block re-renders in Pipeline Editor.
Add pre-commit and improve contributor friendliness
Shout out to Joseph Corrado for his contribution of adding pre-commit hooks to Mage to run code checks before committing and pushing the code.
Doc: https://github.com/mage-ai/mage-ai/blob/master/README_dev.md
Create method for deleting secret keys
Shout out to hjhdaniel for his contribution of adding the method for deleting secret keys to Mage.
Example code:
from mage_ai.data_preparation.shared.secrets import delete_secret
delete_secret('secret_name')
Retry block
Retry from selected block in integration pipeline
If a block is selected in an integration pipeline to retry block runs, only the block runs for the selected block's stream will be ran.
Automatic retry for blocks
Mage now automatically retries blocks twice on failures (3 total attempts).
Other bug fixes & polish
-
Display error popup with link to docs for “too many open files” error.
-
Fix DBT block limit input field: the limit entered through the UI wasn’t taking effect when previewing the model results. Fix this and set a default limit of 1000.
-
Fix BigQuery table id issue for batch load.
-
Fix unique conflict handling for BigQuery batch load.
-
Remove startup_probe in GCP cloud run executor.
-
Fix run command for AWS and GCP job runs so that job run logs can be shown in Mage UI correctly.
-
Pass block configuration to
kwargsin the method. -
Fix SQL block execution when using different schemas between upstream block and current block.
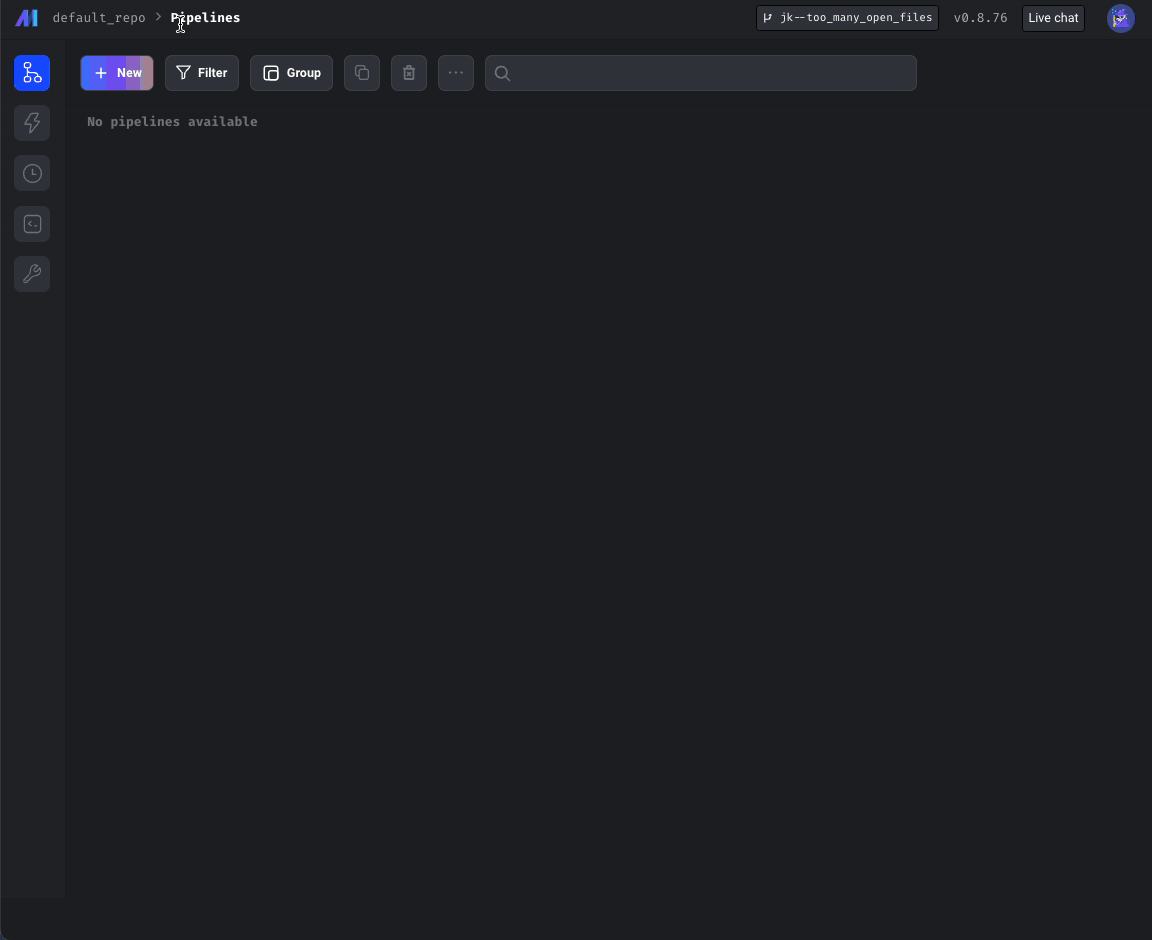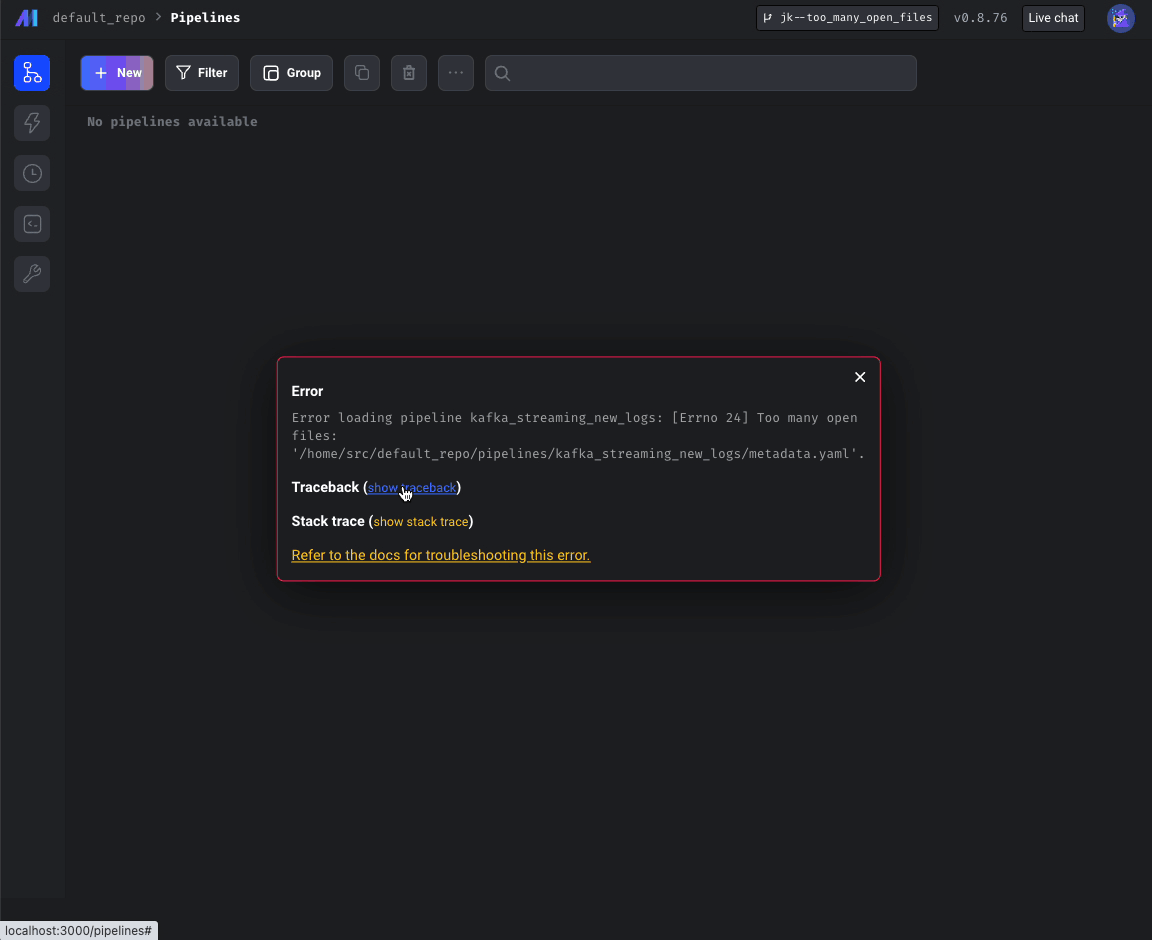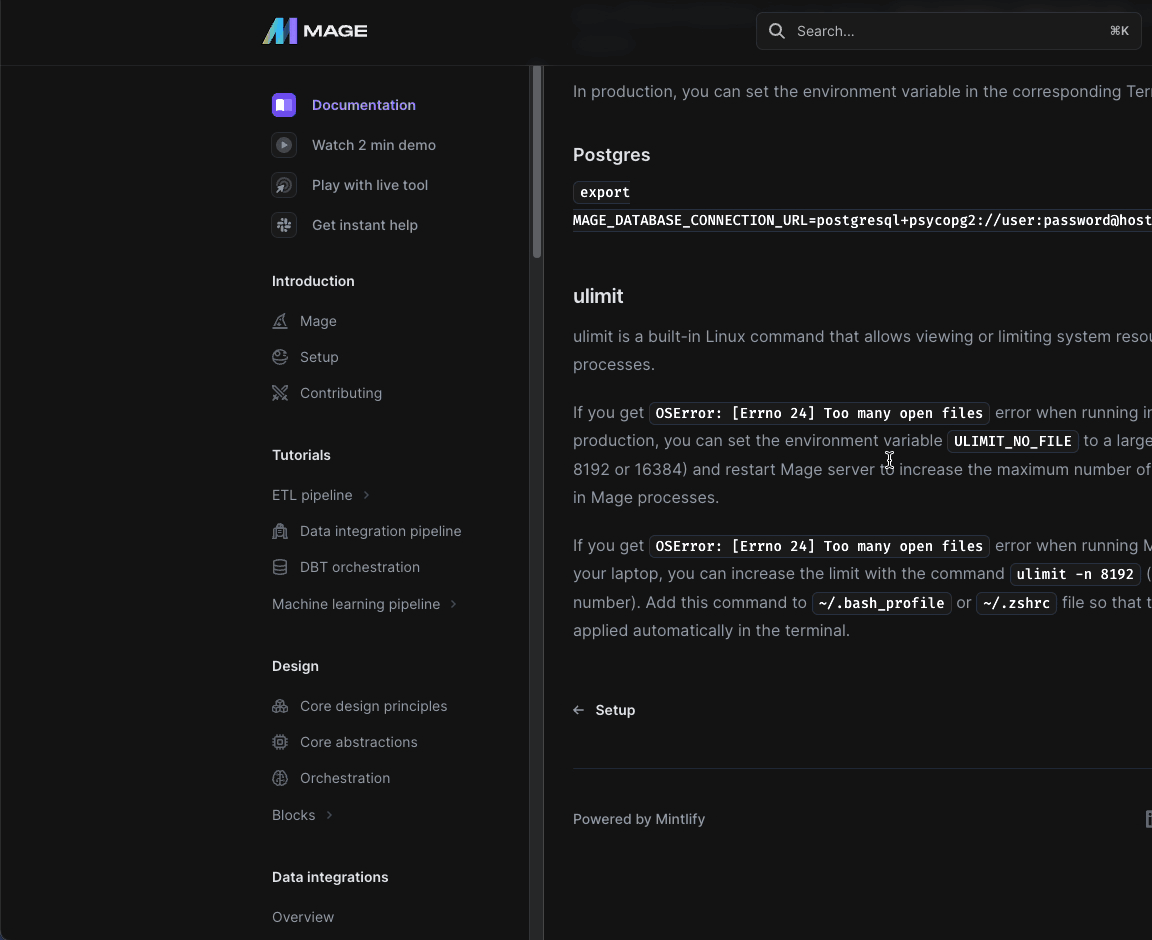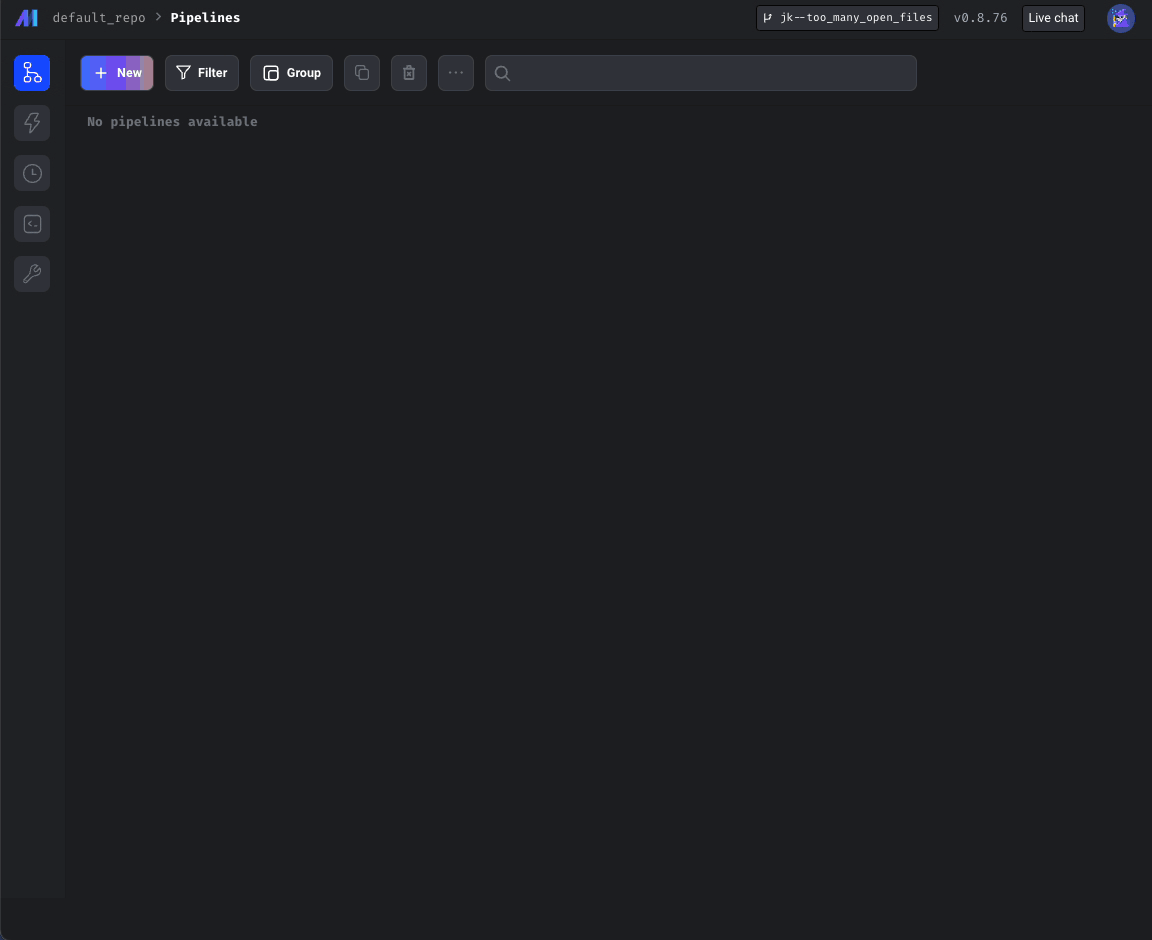
View full Changelog
Published by thomaschung408 over 1 year ago

Polars integration
Support using Polars DataFrame in Mage blocks.
Opsgenie integration
Shout out to Sergio Santiago for his contribution of integrating Opsgenie as an alerting option in Mage.
Doc: https://docs.mage.ai/production/observability/alerting-opsgenie
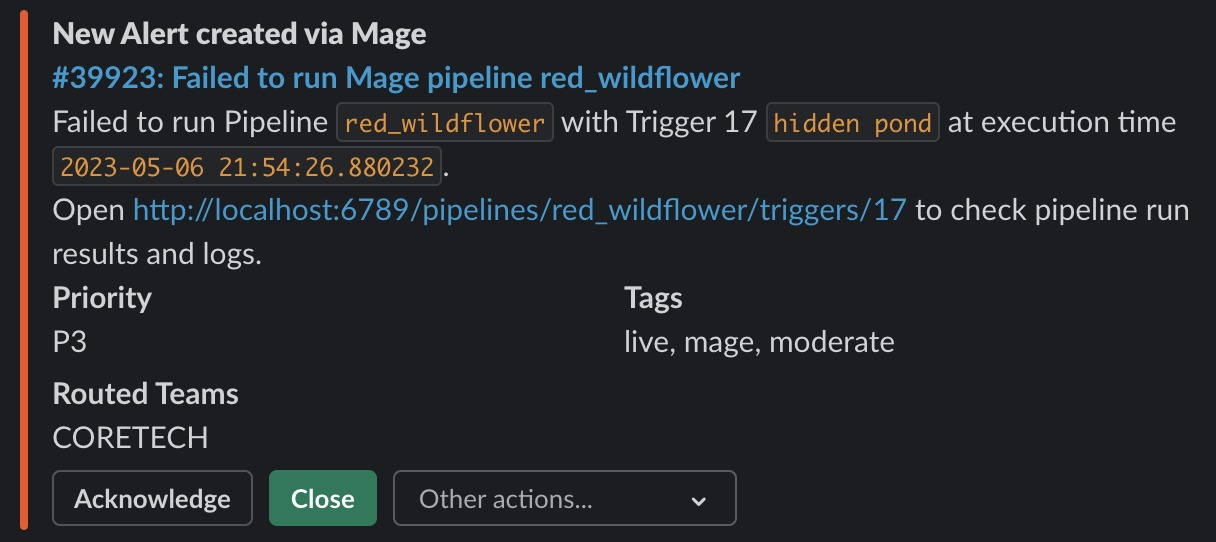
Data integration
Speed up exporting data to BigQuery destination
Add support for using batch load jobs instead of the query API in BigQuery destination. You can enable it by setting use_batch_load to true in BigQuery destination config.
When loading ~150MB data to BigQuery, using batch loading reduces the time from 1 hour to around 2 minutes (30x the speed).
Microsoft SQL Server destination improvements
- Support ALTER command to add new columns
- Support MERGE command with multiple unique columns (use AND to connect the columns)
- Add MSSQL config fields to
io_config.yaml - Support multiple keys in MSSQL destination
Other improvements
- Fix parsing int timestamp in intercom source.
- Remove the “Execute” button from transformer block in data integration pipelines.
- Support using ssh tunnel for MySQL source with private key content
Git integration improvements
- Pass in Git settings through environment variables
- Use
git switchto switch branches - Fix git ssh key generation
- Save cwd as repo path if user leaves the field blank
Update disable notebook edit mode to allow certain operations
Add another value to DISABLE_NOTEBOOK_EDIT_ACCESS environment variable to allow users to create secrets, variables, and run blocks.
The available values are
- 0: this is the same as omitting the variable
- 1: no edit/execute access to the notebook within Mage. Users will not be able to use the notebook to edit pipeline content, execute blocks, create secrets, or create variables.
- 2: no edit access for pipelines. Users will not be able to edit pipeline/block metadata or content.
Doc: https://docs.mage.ai/production/configuring-production-settings/overview#read-only-access
Update Admin abilities
- Allow admins to view and update existing users' usernames/emails/roles/passwords (except for owners and other admins).
- Admins can only view Viewers/Editors and adjust their roles between those two.
- Admins cannot create or delete users (only owners can).
- Admins cannot make other users owners or admins (only owners can).
Retry block runs from specific block
For standard python pipelines, retry block runs from a selected block. The selected block and all downstream blocks will be re-ran after clicking the Retry from selected block button.
Other bug fixes & polish
-
Fix terminal user authentication. Update terminal authentication to happen on message.
-
Fix a potential authentication issue for the Google Cloud PubSub publisher client
-
Dependency graph improvements
- Update dependency graph connection depending on port side
- Show all ports for data loader and exporter blocks in dependency graph
-
DBT
- Support DBT alias and schema model config
- Fix
limitproperty in DBT block PUT request payload.
-
Retry pipeline run
- Fix bug: Individual pipeline run retries does not work on sqlite.
- Allow bulk retry runs when DISABLE_NOTEBOOK_EDIT_ACCESS enabled
- Fix bug: Retried pipeline runs and errors don’t appear in Backfill detail page.
-
Fix bug: When Mage fails to fetch a pipeline due to a backend exception, it doesn't show the actual error. It uses "undefined" in the pipeline url instead, which makes it hard to debug the issue.
-
Improve job scheduling: If jobs with QUEUED status are not in queue, re-enqueue them.
-
Pass
imagePullSecretsto k8s job when usingk8sas the executor. -
Fix streaming pipeline cancellation.
-
Fix the version of google-cloud-run package.
-
Fix query permissions for block resource
-
Catch
sqlalchemy.exc.InternalErrorin server and roll back transaction.
View full Changelog
Published by thomaschung408 over 1 year ago

Markdown blocks aka Note blocks or Text blocks
Added Markdown block to Pipeline Editor.
Doc: https://docs.mage.ai/guides/blocks/markdown-blocks

Git integration improvements
Add git clone action
Allow users to select which files to commit
Add HTTPS authentication
Doc: https://docs.mage.ai/production/data-sync/git#https-token-authentication
Add a terminal toggle, so that users have easier access to the terminal
Callback block improvements
Doc: https://docs.mage.ai/development/blocks/callbacks/overview
Make callback block more generic and support it in data integration pipeline.
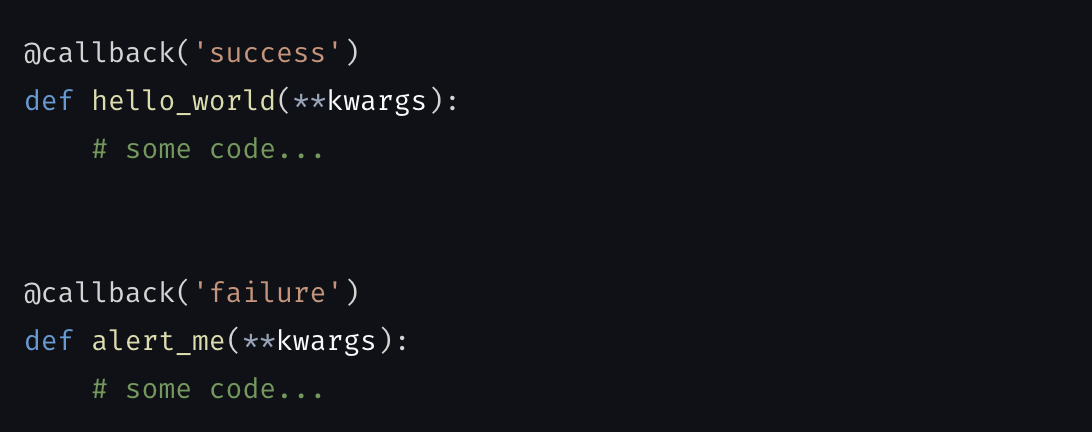
Keyword arguments available in data integration pipeline callback blocks: https://docs.mage.ai/development/blocks/callbacks/overview#data-integration-pipelines-only
Transfer owner status or edit the owner account email
- Owners can make other users owners.
- Owners can edit other users' emails.
- Users can edit their emails.
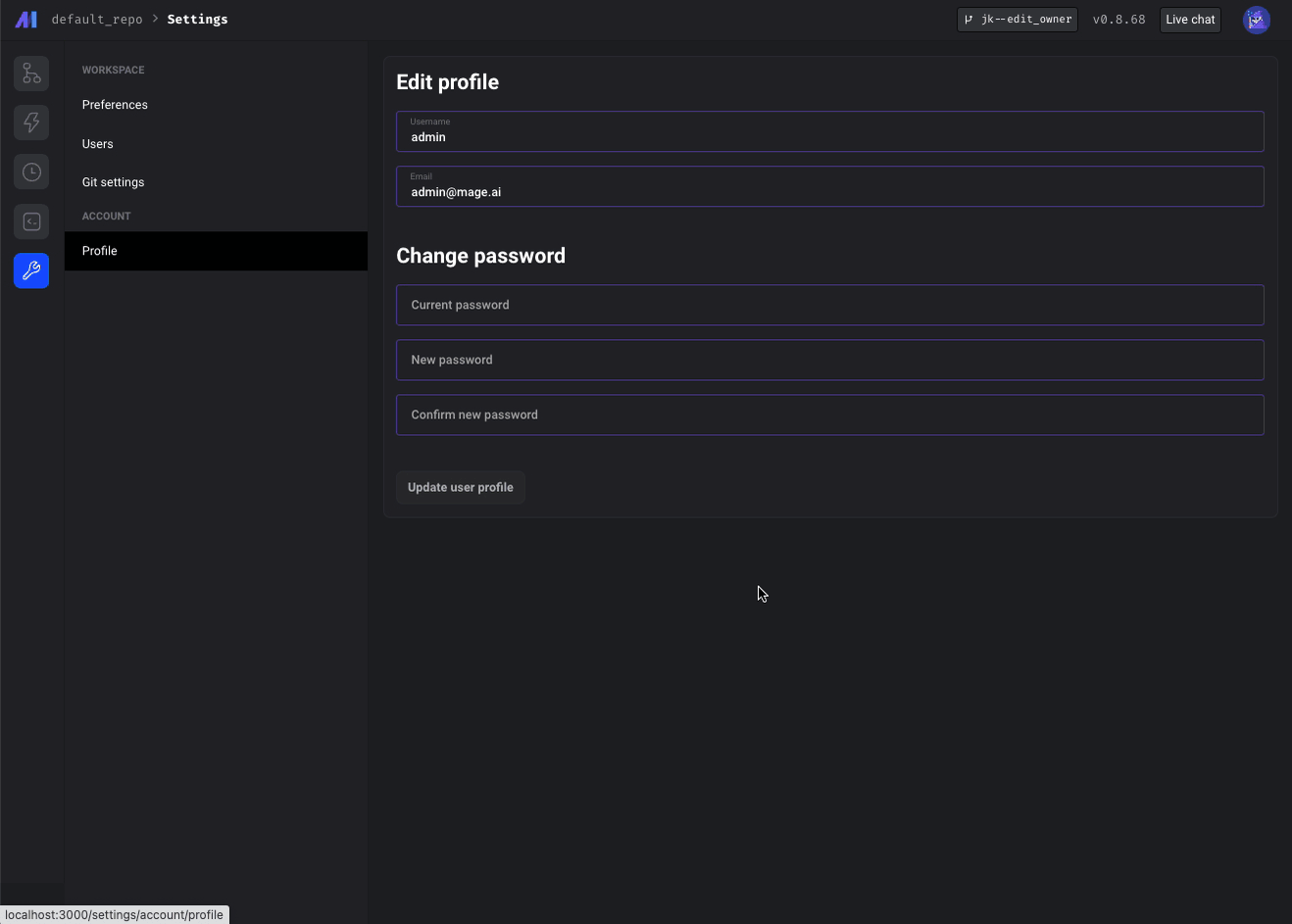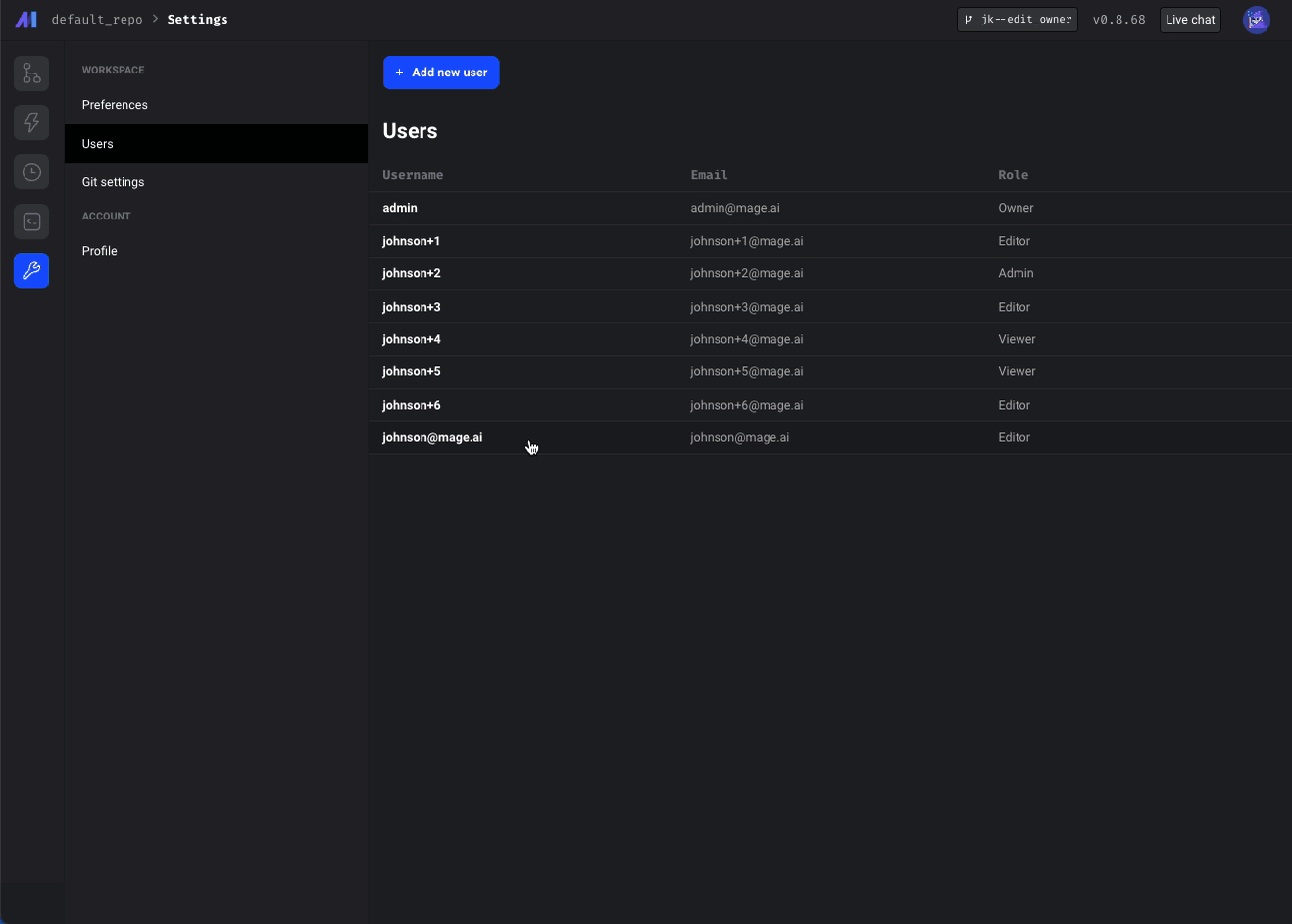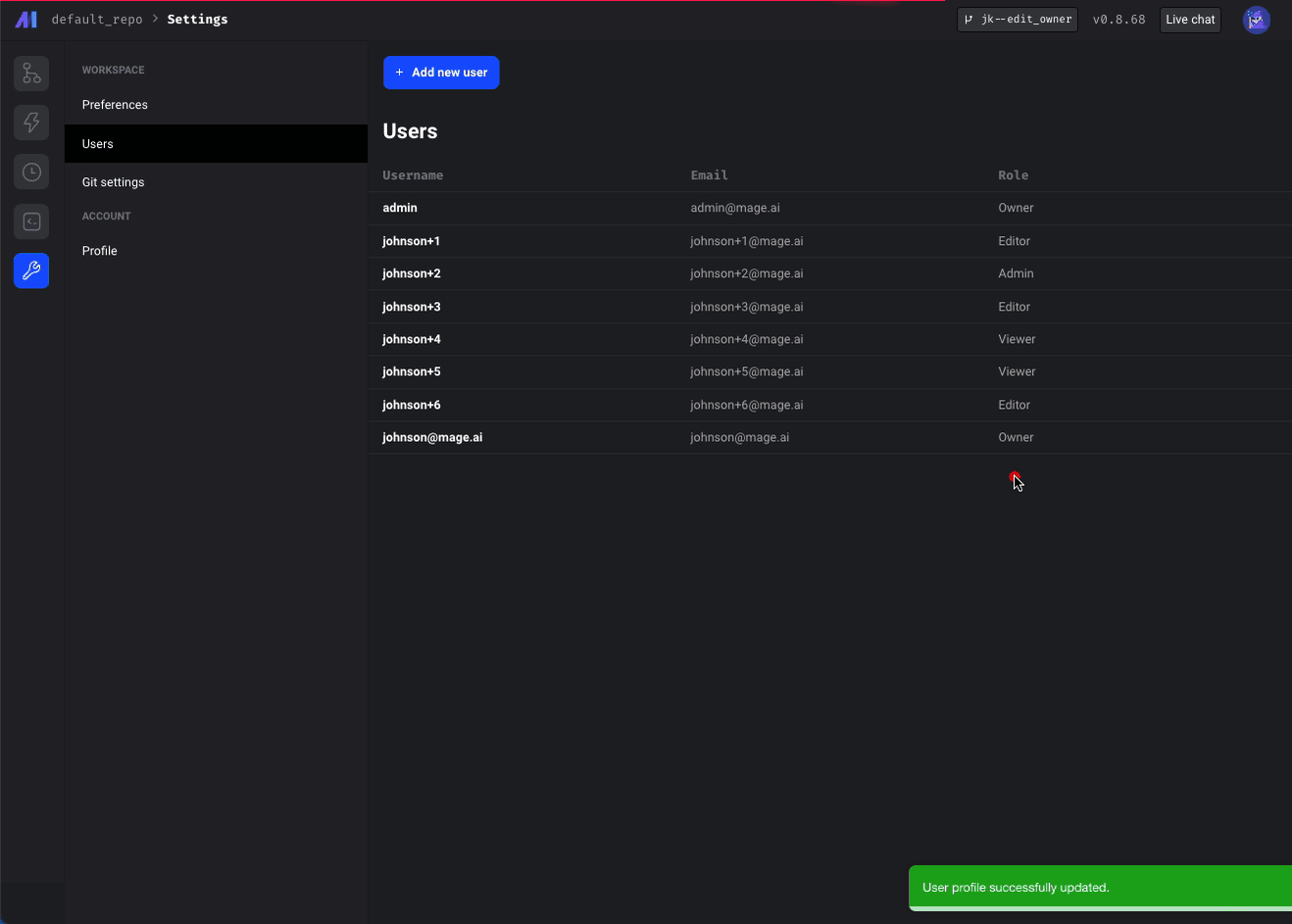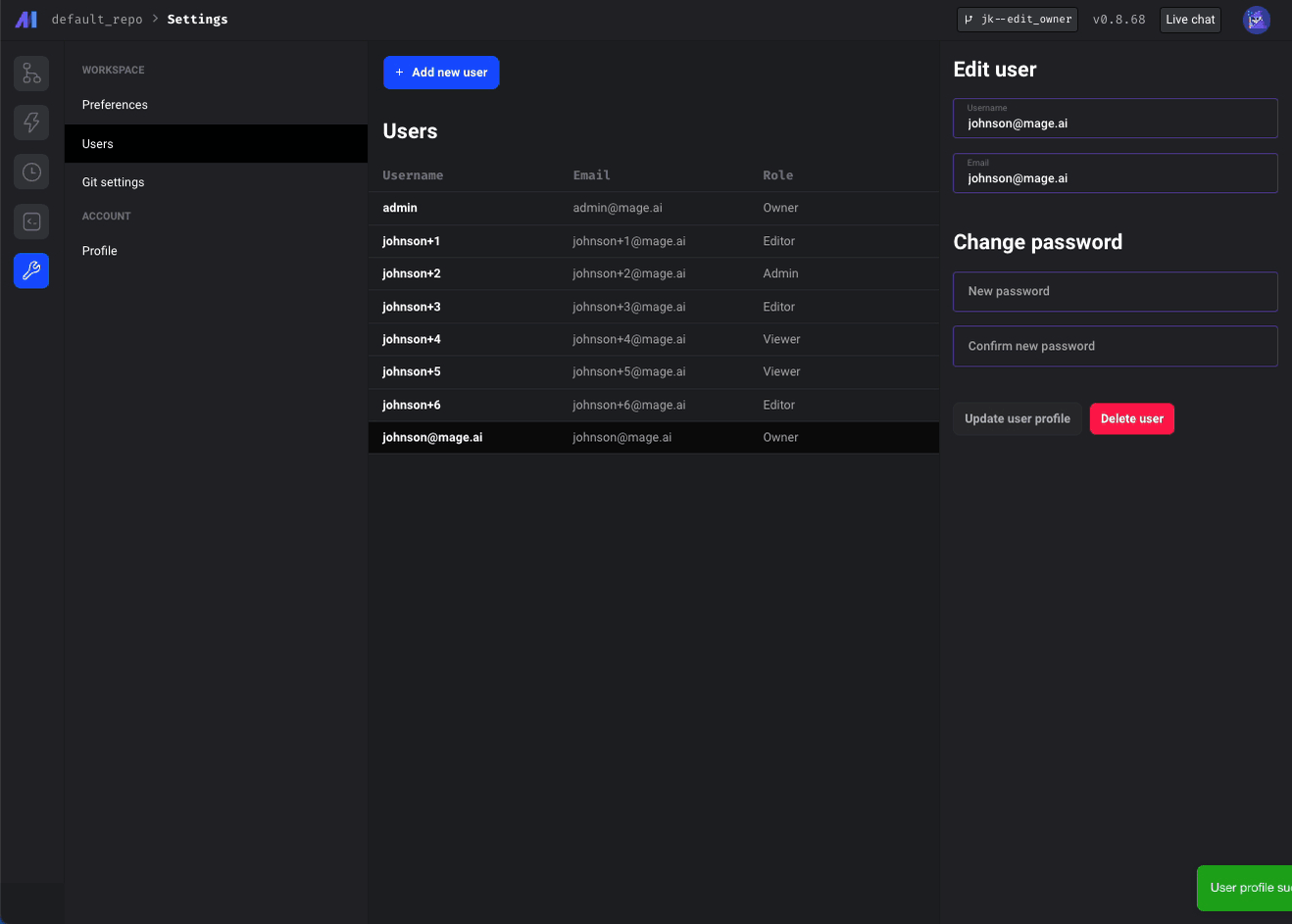
Bulk retry pipeline runs.
Support bulk retrying pipeline runs for a pipeline.
Right click context menu
Add right click context menu for row on pipeline list page for pipeline actions (e.g. rename).
Navigation improvements
When hovering over left and right vertical navigation, expand it to show navigation title like BigQuery’s UI.
Use Great Expectations suite from JSON object or JSON file
Doc: https://docs.mage.ai/development/testing/great-expectations#json-object
Support DBT incremental models
Doc: https://docs.mage.ai/dbt/incremental-models
Data integration pipeline
New destination: Google Cloud Storage
Shout out to André Ventura for his contribution of adding the Google Cloud Storage destination to data integration pipeline.
Other improvements
- Use bookmarks properly in Intercom incremental streams.
- Support IAM role based authentication in the Amazon S3 source and Amazon S3 destination for data integration pipelines
SQL module improvements
Add Apache Druid data source
Shout out to Dhia Eddine Gharsallaoui again for his contribution of adding Druid data source to Mage.
Doc: https://docs.mage.ai/integrations/databases/Druid
Add location as a config in BigQuery IO

Speed up Postgres IO export method
Use COPY command in mage_ai.io.postgres.Postgres export method to speed up writing data to Postgres.
Streaming pipeline
New source: Google Cloud PubSub
Doc: https://docs.mage.ai/guides/streaming/sources/google-cloud-pubsub
Deserialize message with Avro schema in Confluent schema registry
Kubernetes executor
Add config to set all pipelines use K8s executor
Setting the environment variable DEFAULT_EXECUTOR_TYPE to k8s to use K8s executor by default for all pipelines. Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#2-set-executor-type-and-customize-the-compute-resource-of-the-mage-executor
Add the k8s_executor_config to project’s metadata.yaml to apply the config to all the blocks that use k8s executor in this project. Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#kubernetes-executor
Support configuring GPU for k8s executor
Allow specifying GPU resource in k8s_executor_config.
Not use default as service account namespace in Helm chart
Fix service account permission for creating Kubernetes jobs by not using default namespace.
Doc for deploying with Helm: https://docs.mage.ai/production/deploying-to-cloud/using-helm
Other bug fixes & polish
- Fix error: When selecting or filtering data from parent block, error occurs: "AttributeError: list object has no attribute tolist".
- Fix bug: Web UI crashes when entering edit page (github issue).
- Fix bug: Hidden folder (.mage_temp_profiles) disabled in File Browser and not able to be minimized
- Support configuring Mage server public host used in the email alerts by setting environment variable
MAGE_PUBLIC_HOST. - Speed up PipelineSchedule DB query by adding index to column.
- Fix EventRulesResource AWS permissions error
- Fix bug: Bar chart shows too many X-axis ticks

View full Changelog
Published by thomaschung408 over 1 year ago

Trigger pipeline from a block
Provide code template to trigger another pipeline from a block within a different pipeline.****
Doc: https://docs.mage.ai/orchestration/triggers/trigger-pipeline
Data integration pipeline
New source: Twitter Ads
Streaming pipeline
New sink: MongoDB
Doc: https://docs.mage.ai/guides/streaming/destinations/mongodb
Allow deleting SQS message manually
Mage supports two ways to delete messages:
- Delete the message in the data loader automatically after deserializing the message body.
- Manually delete the message in transformer after processing the message.
Doc: https://docs.mage.ai/guides/streaming/sources/amazon-sqs#message-deletion-method
Allow running multiple executors for streaming pipeline
Set executor_count variable in the pipeline’s metadata.yaml file to run multiple executors at the same time to scale the streaming pipeline execution
Doc: https://docs.mage.ai/guides/streaming/overview#run-pipeline-in-production
Improve instructions in the sidebar for getting block output variables
- Update generic block templates for custom, transformer, and data exporter blocks so it's easier for users to pass the output from upstream blocks.
- Clarified language for block output variables in Sidekick.

Paginate block runs in Pipeline Detail page and schedules on Trigger page
Added pagination to Triggers and Block Run pages
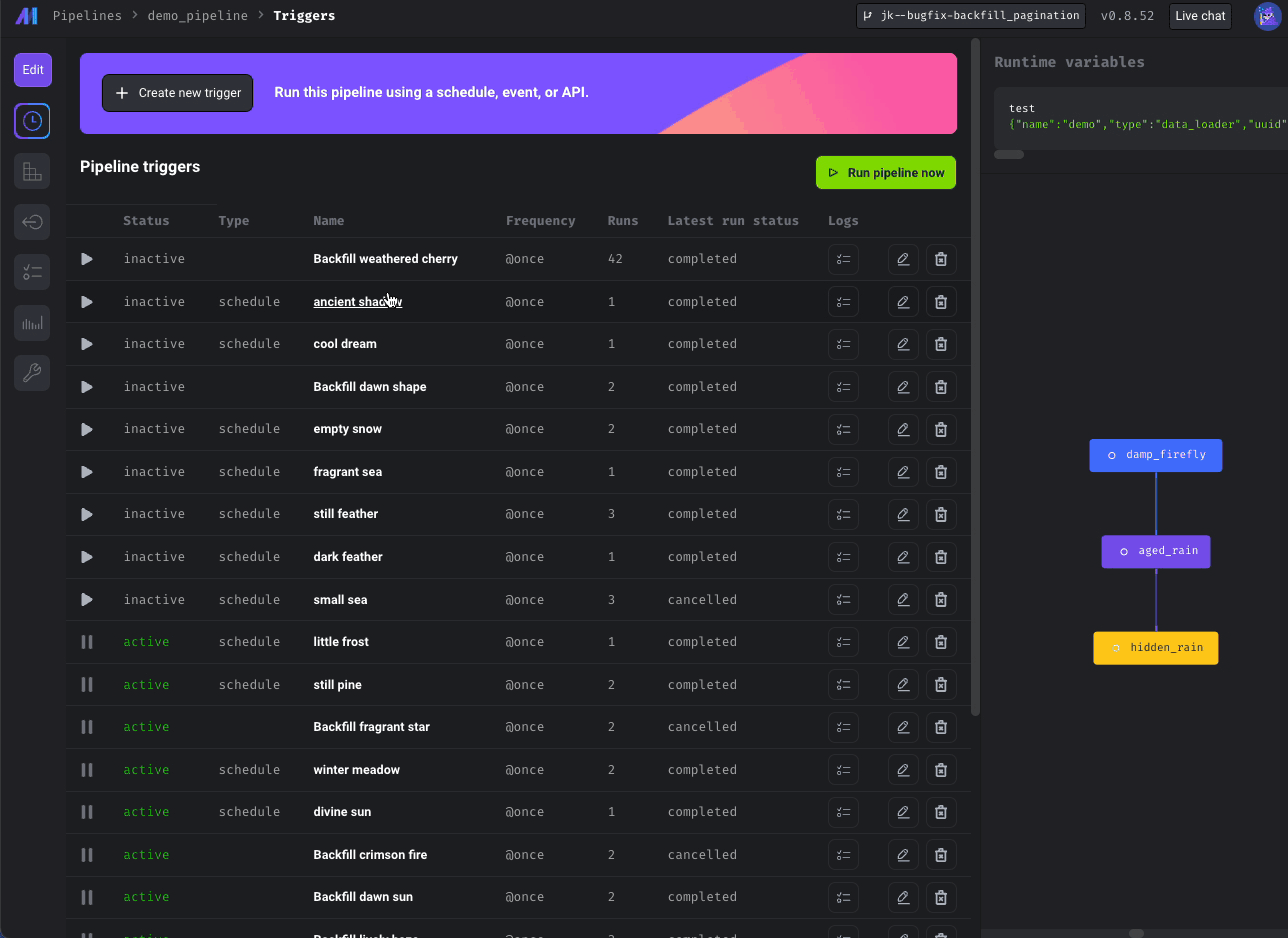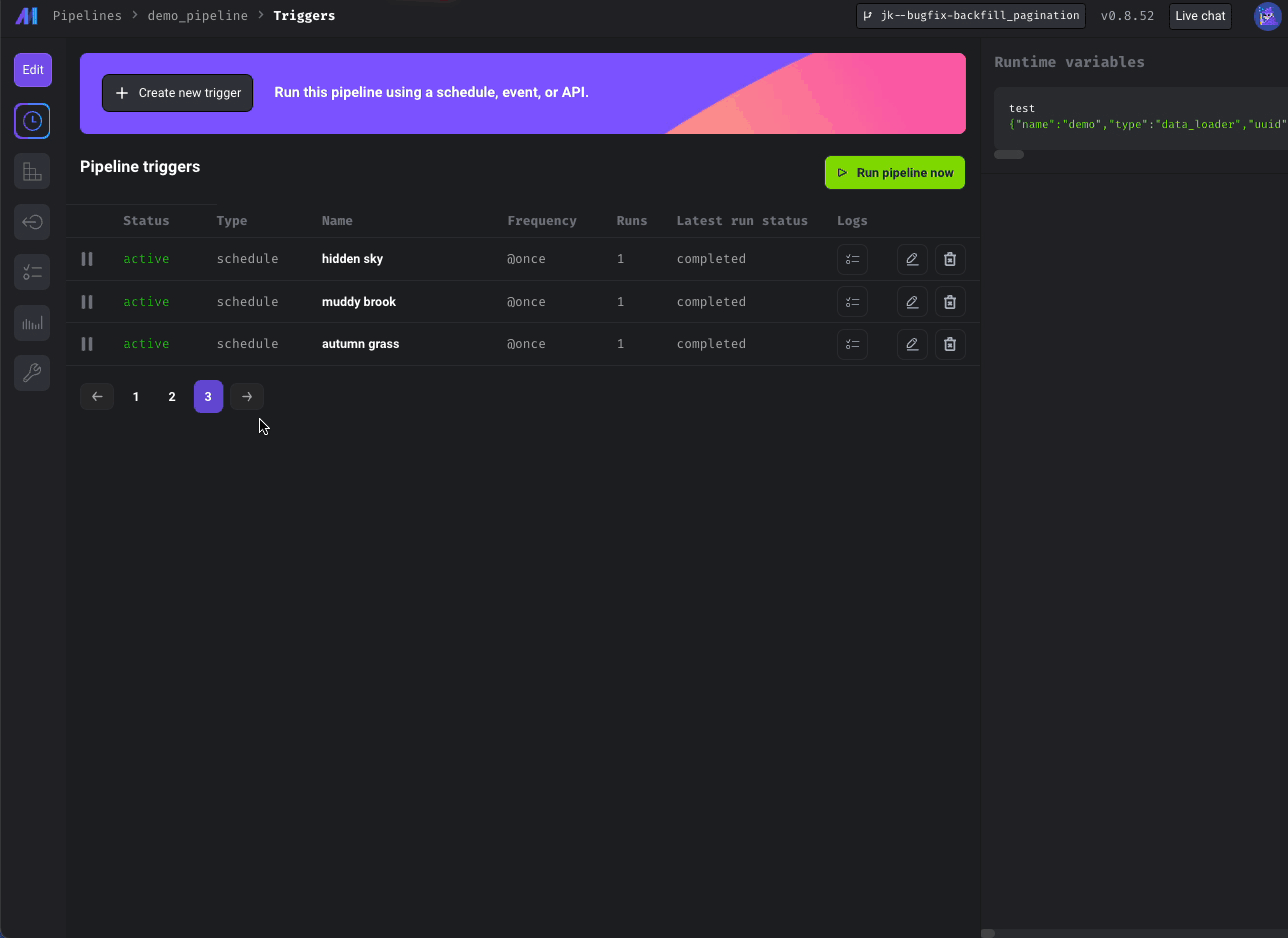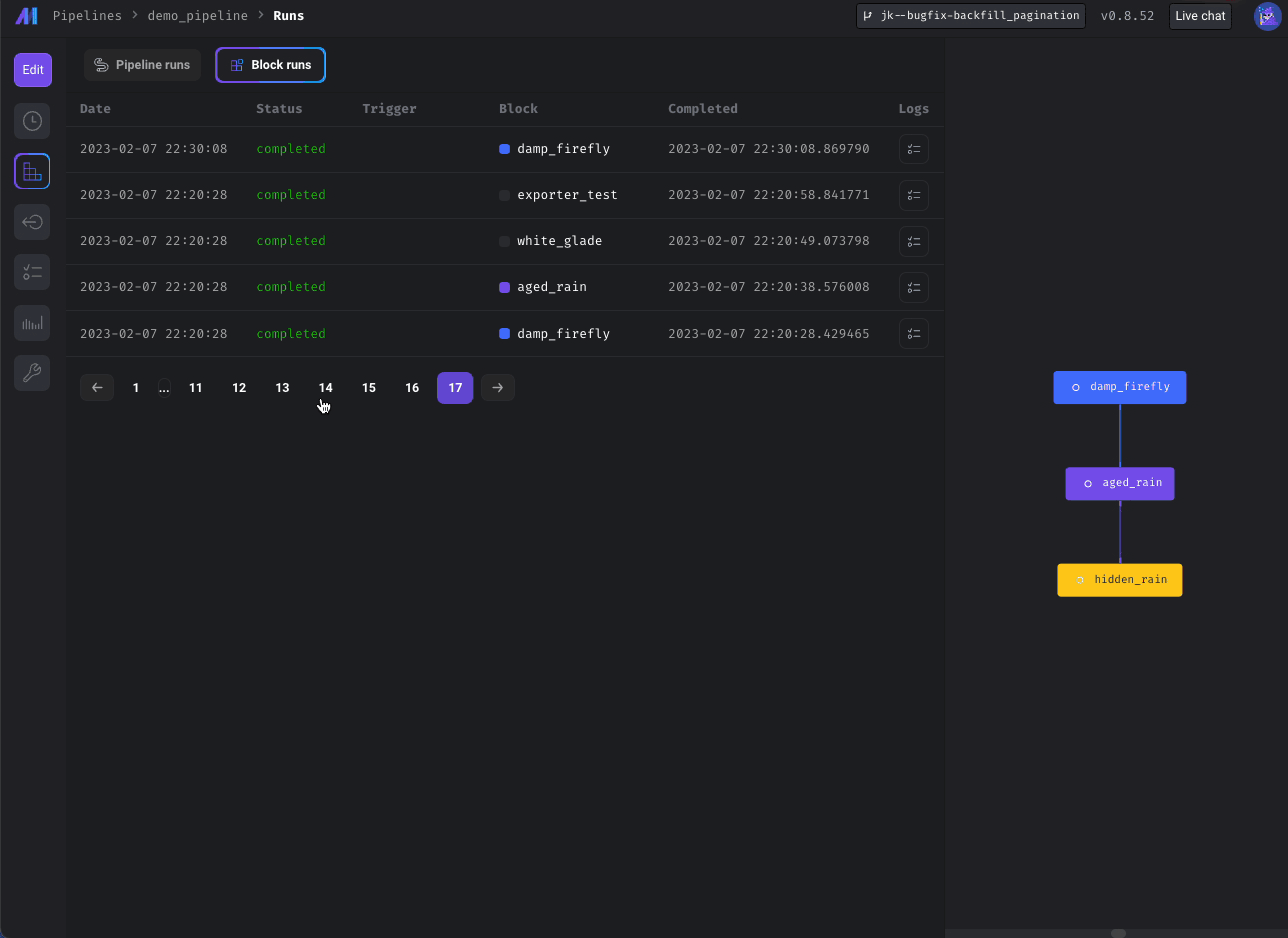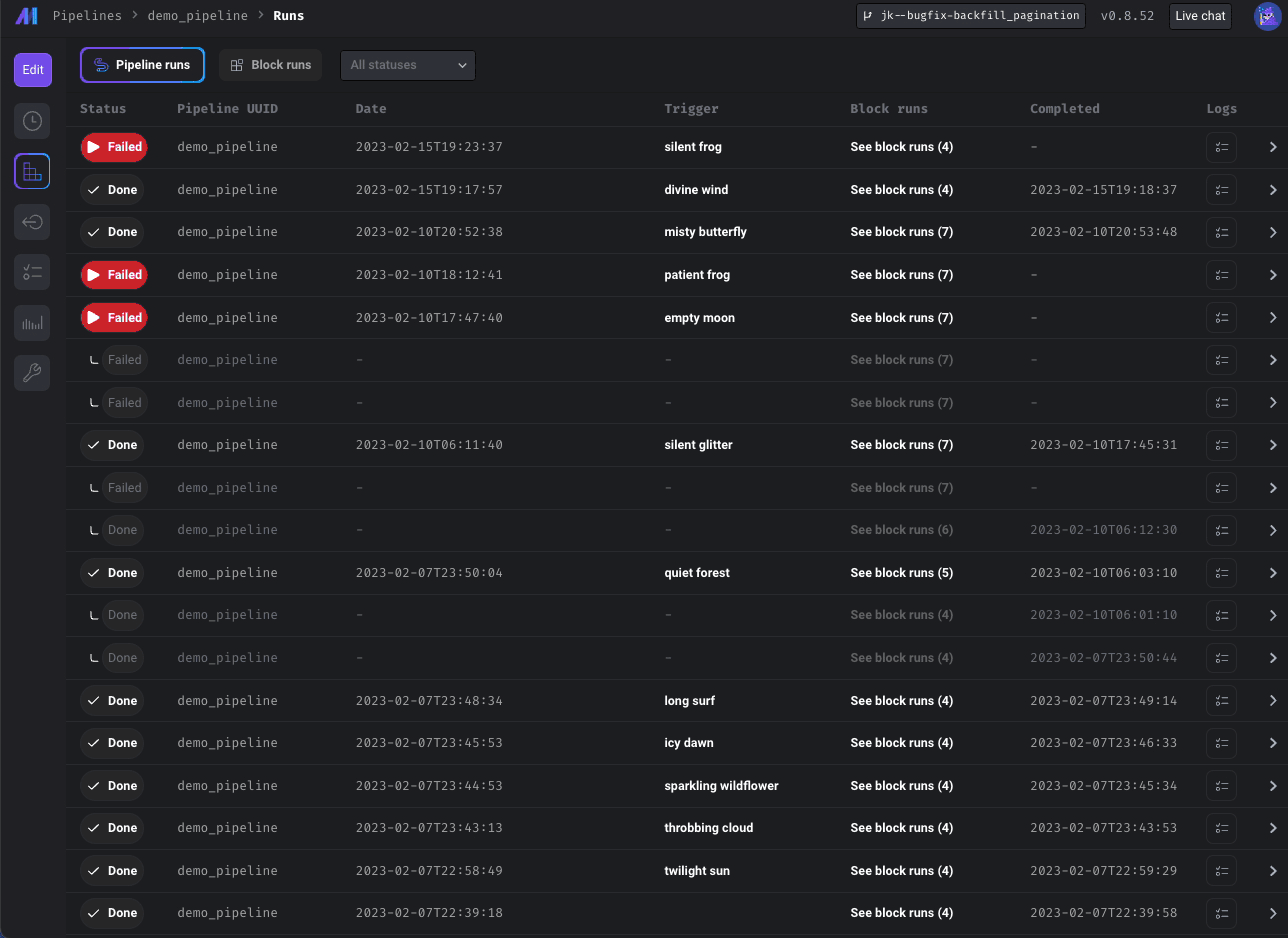
Automatically install requirements.txt file after git pulls
After pulling the code from git repository to local, automatically install the libraries in requirements.txt so that the pipelines can run successfully without manual installation of the packages.
Add warning for kernel restarts and show kernel metrics
- Add warning for kernel if it unexpectedly restarts.
- Add memory and cpu metrics for the kernel.
SQL block: Customize upstream table names
Allow setting the table names for upstream blocks when using SQL blocks.
Other bug fixes & polish
- Fix “Too many open files” error by providing the option to increase the “maximum number of open files” value: https://docs.mage.ai/production/configuring-production-settings/overview#ulimit
- Add
connect_timeoutto PostgreSQL IO - Add
locationto BigQuery IO - Mitigate race condition in Trino IO
- When clicking the sidekick navigation, don’t clear the URL params
- UI: support dynamic child if all dynamic ancestors eventually reduce before dynamic child block
- Fix PySpark pipeline deletion issue. Allow pipeline to be deleted without switching kernel.
- DBT block improvement and bug fixes
- Fix the bug of running all models of DBT
- Fix DBT test not reading profile
- Disable notebook shortcuts when adding new DBT model.
- Remove
.sqlextension in DBT model name if user includes it (the.sqlextension should not be included). - Dynamically size input as user types DBT model name with
.sqlsuffix trailing to emphasize that the.sqlextension should not be included. - Raise exception and display in UI when user tries to add a new DBT model to the same file location/path.
- Fix
onSuccesscallback logging issue - Fixed
mage runcommand. Set repo_path before initializing the DB so that we can get correct db_connection_url. - Fix bug: Code block running spinner keeps spinning when restarting kernel.
- Fix bug: Terminal doesn’t work in mage demo
- Automatically redirect users to the sign in page if they are signed in but can’t load anything.
- Add folder lines in file browser.
- Fix
ModuleNotFoundError: No module named 'aws_secretsmanager_caching'when running pipeline from command line
View full Changelog
