
refinery
The data scientist's open-source choice to scale, assess and maintain natural language data. Treat training data like a software artifact.
APACHE-2.0 License
Bot releases are hidden (Show)
Published by jhoetter over 2 years ago

We have been working tirelessly towards this day for a long time. Finally, we can say that Kern refinery goes open-source, and we celebrate this with our version 1.0!
There are three main reasons why we decided to do that step:
1. Community
We strive to create a community of like-minded devs who want to participate in the movement toward data-centric AI.
2. Innovation
We want to drive innovation through collaboration. Open-source software provides a faster response time to current market needs.
3. Transparency
It is important to us that the access and individualization of our software are possible for all of our users.
Now that we've finished our open-source go-live, we are looking forward to working towards those three goals every day.
Our work towards the release was mainly put into - again - three areas:
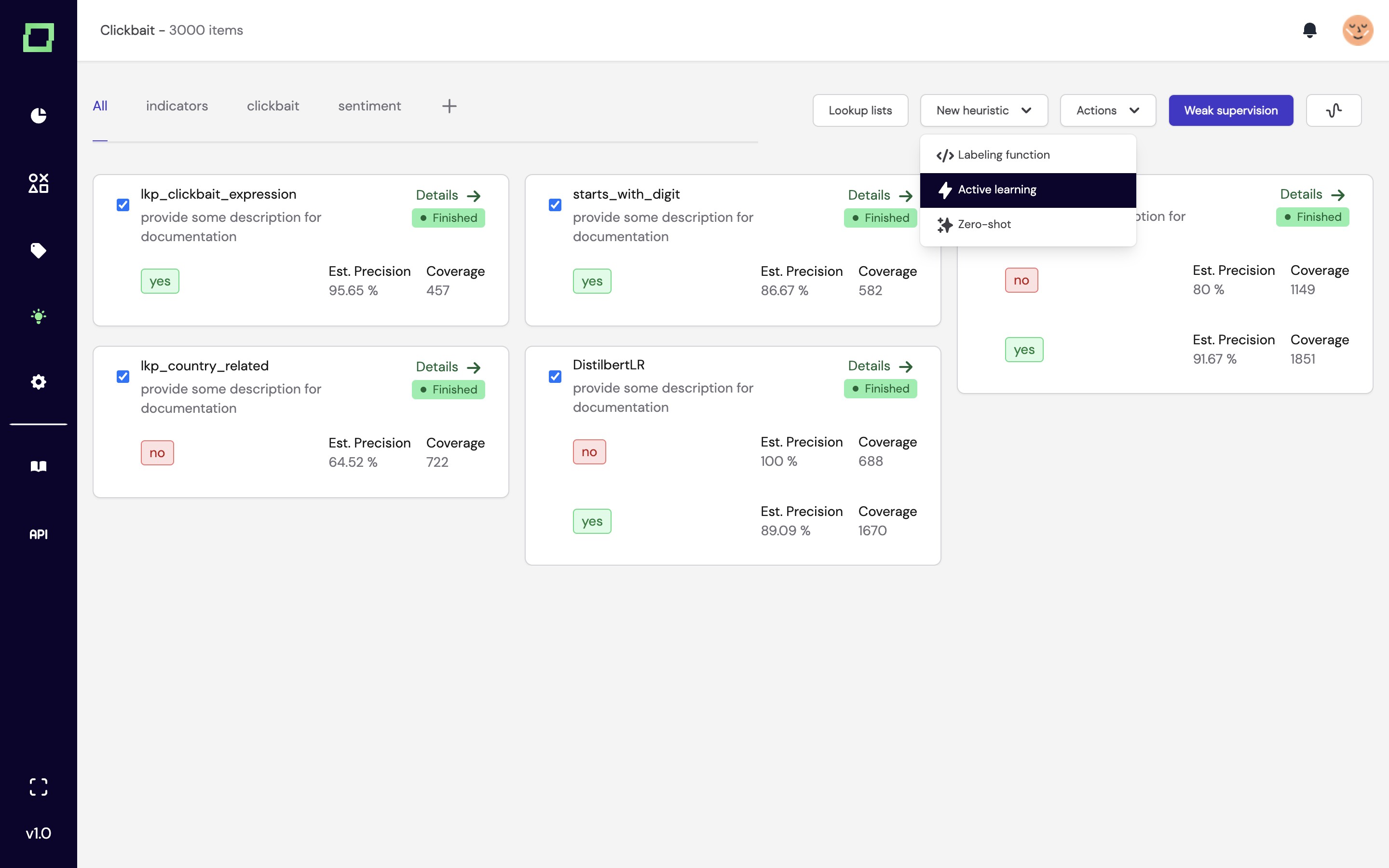
1. New UI and improved UX
You might have noticed that our app has a new look. We did several user tests, rebranded our app, and went for the following look:
Also, we integrated some features that make it easier to play around with the data from a programmatic point of view, such as the record IDE:
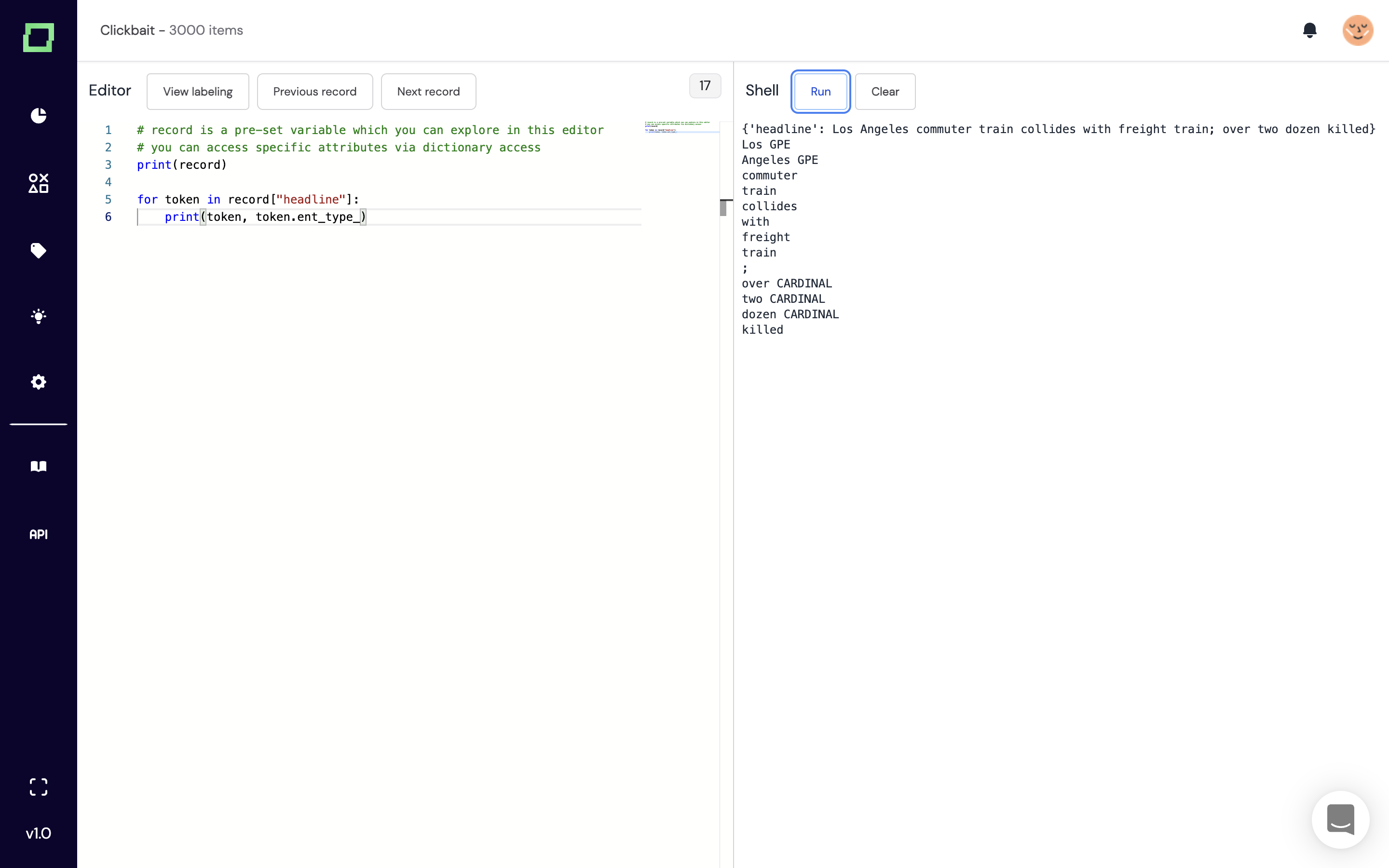
You can check out those things in our guide.
What do you think of the new UI look? Let us know, we're excited about your feedback!
2. Extended documentation and use cases
We've put extra effort into everything related to your first impression and first successes of using Kern refinery. And what's super important for that is documentation and use cases. You can now not only find more insights in this very documentation but can also find hands-on examples on YouTube, on our GitHub, and on our community spaces (discussion forum and Discord).
3. Architectural changes
Lastly, with an open-source release, we wanted to improve our architectural design. We've spent lots of effort on refactoring services and making sure that we can quickly iterate on your product feedback and ideas. In total, we've spent now more than 18 months on this very application, from initial design to the first MVP and now version 1.0 - but of course, we are still only getting started to build the data-centric development environment specifically designed to help data scientists in building great AI models. Help us, and we'll make sure to continue building something people love!
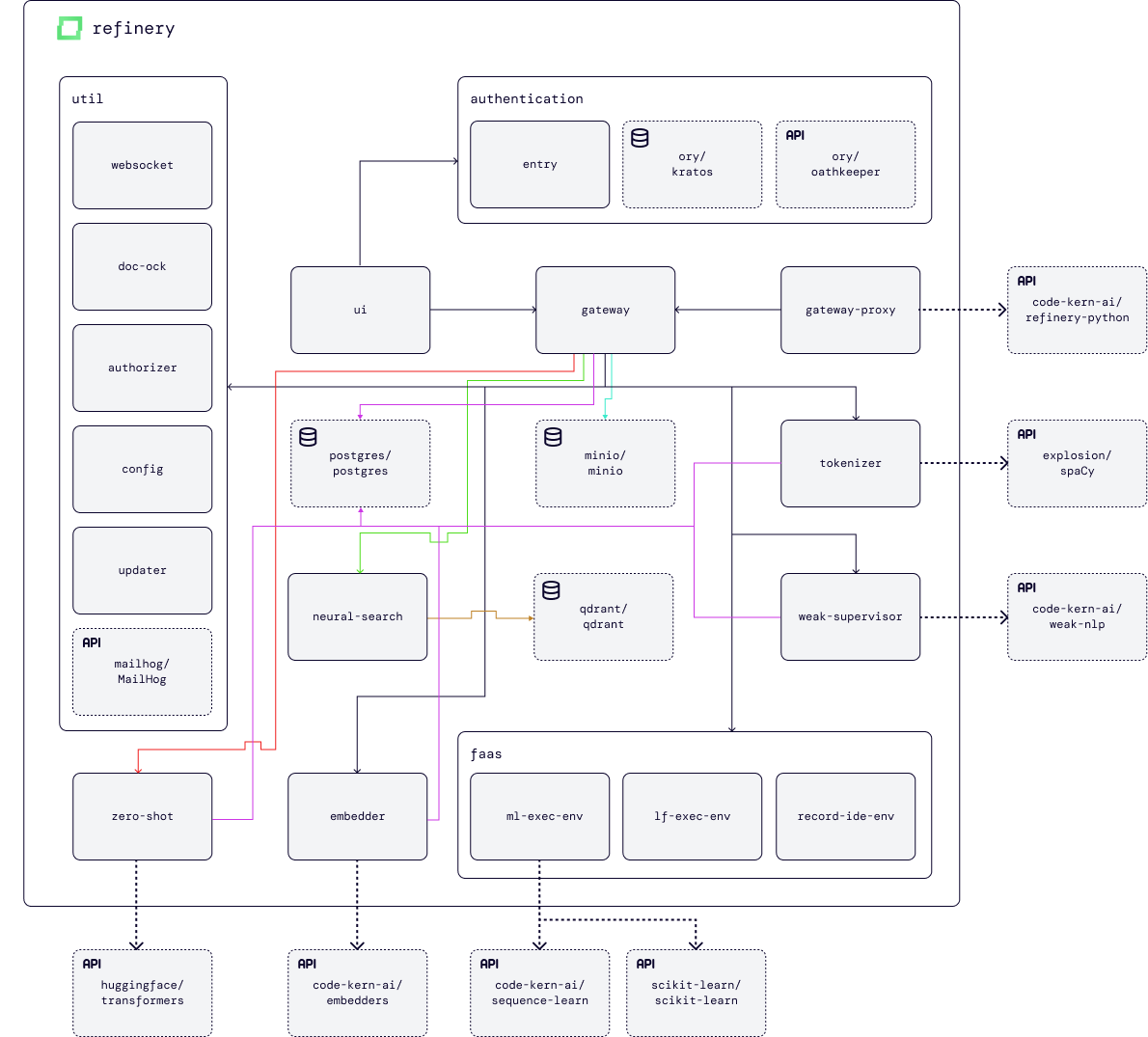
To get started, take a look at our self-hosted version. Also, we continue to provide a managed version.
To stay up-to-date with everything, make sure to subscribe to our newsletter, and don't forget to give us a star on GitHub. We couldn't be more excited for the future!