
swirl-search
SWIRL AI Connect: AI infrastructure software that powers your Search & Retrieval Augmented Generation (RAG) applications. Simplify and enhance your AI pipelines with seamless integration of large language models (LLMs) and data sources.
APACHE-2.0 License
Bot releases are hidden (Show)
Published by sidprobstein over 1 year ago
![]()
SWIRL SEARCH 1.8.2
This version upgrades the version of python used in Docker setup.
PLEASE STAR OUR REPO: http://swirl.today/
New Features
🔹 Docker will now run python 3.11.1
FROM python:3.11.1-slim
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch AKA predictive service. Turn off Chrome prediction service. Turn off Safari prefetch
Please report any issues with this to support.
Upgrading
⚠️ Version 1.8.2 does not require database migration.
Documentation Wiki
🔹 Quick Start
🔹 User Guide
🔹 Developer Guide
🔹 Admin Guide
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented
🔹 Email: [email protected] with issues, requests, questions, etc - we'd love to hear from you!
Published by sidprobstein over 1 year ago
![]()
SWIRL SEARCH 1.8.1
This version resolves issues found in 1.8 and eliminates two installation steps.
PLEASE STAR OUR REPO: http://swirl.today/
New Features
🔹 SWIRL 1.8.1 ships with a SQLite3 database pre-loaded with a super user and the Google PSE examples!
This simplifies all Quick Start procedures dramatically.
Issues Resolved
🔹 Stack2Mixer produces 500 error
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch AKA predictive service. Turn off Chrome prediction service. Turn off Safari prefetch
Please report any issues with this to support.
Upgrading
⚠️ Version 1.8.1 does not require database migration.
Documentation Wiki
🔹 Quick Start
🔹 User Guide
🔹 Developer Guide
🔹 Admin Guide
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented
🔹 Email: [email protected] with issues, requests, questions, etc - we'd love to hear from you!
Published by sidprobstein almost 2 years ago
![]()
SWIRL SEARCH 1.8
This version adds the ability to target specific providers with tag searches (e.g. company:tesla), and the new subscribe feature that causes SWIRL to continuously monitor for new, relevant results - plus a new BigQuery connector!
PLEASE STAR OUR REPO: http://swirl.today/

New Features
🔹 SWIRL now supports targeting of tagged SearchProviders using the tag: prefix.
For example:
electric vehicle company:tesla
The AdaptiveQueryProcessor rewrites this query to electric vehicle tesla for most providers. But providers with the tag company will have it rewritten to just tesla. So this search retrieves typical news results PLUS funding records from BigQuery:

The latter would not have matched the full query. Tag enables expressive querying where specific types of repositories are targeted with appropriate search terms, and SWIRL unifies the results.
🔹 Subscribe to any Search. SWIRL will check for new results every few hours, and automatically detects & discards duplicates by URL or document similarity.

More details: Subscribing to a Search
🔹 New Google BigQuery Connector plus SearchProvider for the Funding Dataset:
{
"name": "Company Funding Records (cloud/BigQuery)",
"connector": "BigQuery",
"query_template": "select {fields} from `{table}` where search({field1}, '{query_string}') or search({field2}, '{query_string}');",
"query_processor": "",
"query_processors": [
"AdaptiveQueryProcessor"
],
"query_mappings": "fields=*,sort_by_date=fundedDate,table=funding.funding,field1=company,field2=city",
"result_processor": "",
"result_processors": [
"MappingResultProcessor"
],
"result_mappings": "title='{company}',body='{company} raised ${raisedamt} series {round} on {fundeddate}. The company is located in {city} {state} and has {numemps} employees.',url=permalink,date_published=fundeddate,NO_PAYLOAD",
"credentials": "/path/to/bigquery/token.json",
"tags": [
"Company",
"BigQuery"
]
}
More details: Google BigQuery Connector
🔹 SWIRL 1.8 supports pipelining of Processors for pre-query, query, result and post-result transformation of queries, responses and results.
For example, the new Search post-result pipeline:
"post_result_processors": [
"DedupeByFieldPostResultProcessor",
"CosineRelevancyPostResultProcessor"
]
More details: Processing Pipelines
🔹 The new DedupeByFieldPostResultProcessor detects and removes duplicates on any field - 'url' by default.
🔹 The new DedupeBySimilarityPostResultProcessor detects and removes duplicates by similarity between - 'title' and 'body' field (by default), with a cut-off threshold of .95.
More details: Detecting and Removing Duplicate Results
Changes
🔹 swirl.py can now be invoked with --debug
python swirl.py --debug restart core
This configuration starts django using the built-in runserver, instead of daphne, and sets the logging level to DEBUG.
Known Issues
🔹 The PostgreSQL Connector no longer causes errors in the celery-worker log if PostgreSQL isn't installed
Please follow the updated installation instructions before attempting to install a SearchProvider that uses the PostgreSQL Connector. We hope to make this easier in a future release.
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch AKA predictive service. Turn off Chrome prediction service. Turn off Safari prefetch
Please report any issues with this to support.
Upgrading
⚠️ Version 1.8 requires database migration. Details: Upgrading SWIRL
Documentation Wiki
🔹 Quick Start 🔹 User Guide 🔹 Developer Guide 🔹 Admin Guide
Support
🔹 Join SWIRL SEARCH #support on Slack!
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented
🔹 Email: [email protected] with issues, requests, questions, etc - we'd love to hear from you!
Published by sidprobstein almost 2 years ago
![]()
SWIRL SEARCH 1.7
This version incorporates feedback around UI and hosting usability.
PLEASE STAR OUR REPO: http://swirl.today/

New Features
🔹 The new qs URL parameter provides a synchronous response, with no need to poll or handle a redirect.
qs accepts the same arguments as the q parameter:
localhost:8000/swirl/search/?qs=knowledge+management
localhost:8000/swirl/search/?qs=knowledge+management+software+NOT+practice
localhost:8000/swirl/search/?qs='knowledge+management'+software+NOT+practice&providers=news,email,companies
The result_mixer can be specified as well:
localhost:8000/swirl/search/?qs=knowledge+management&result_mixer=DateMixer
Only the first page of results are provided. Use the next_page link in the info.results block to access additional pages.
More details: Getting synchronous results with the qs URL Parameter
🔹 Django User permissions are now enforced on SearchProvider, Search and Result objects.
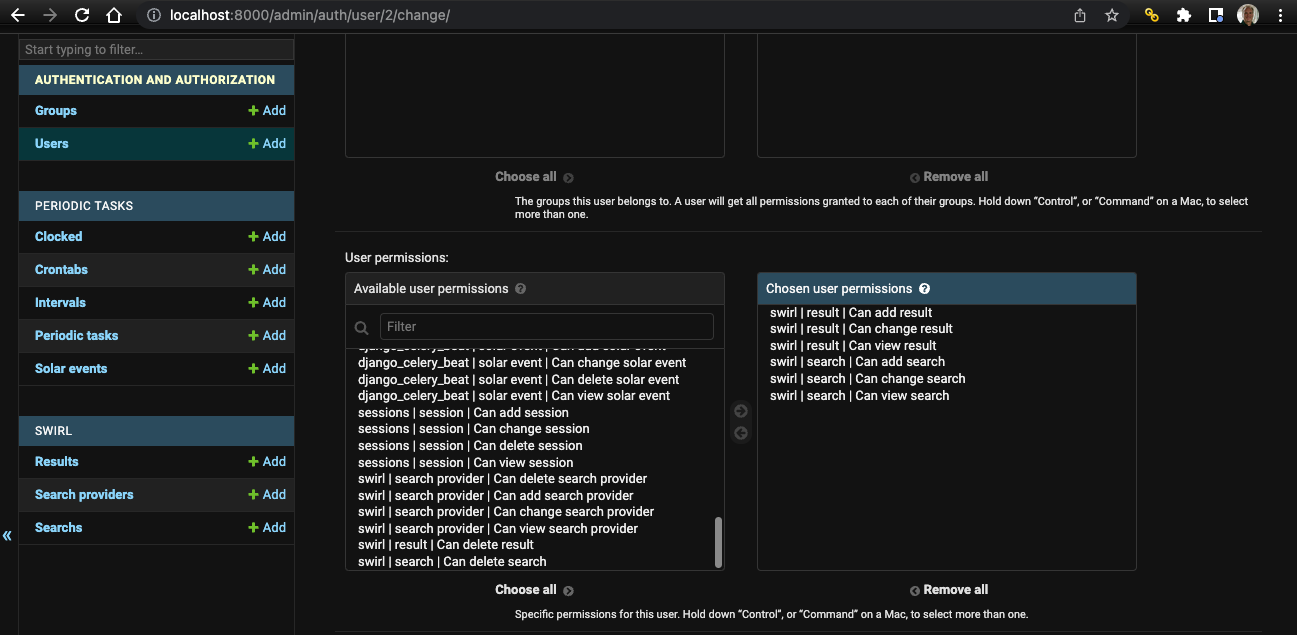
More details: Permissioning Users
Changes
🔹 swirl.py now supports a logs command that will output all log files to the console
swirl-search% python swirl.py logs
__S_W_I_R_L__1_._7______________________________________________________________
tail -f logs/*.log - hit ^C to stop:
==> logs/django.log <==
127.0.0.1:58635 - - [02/Dec/2022:19:27:10] "GET /admin/" 200 8932
...etc...
Issues Resolved
🔹 key error: 'searchprovider_rank' when processing results with GenericResultProcessor
🔹 PostgreSQL driver Psycopg2 issues
The PostgreSQL connector has been removed from [swirl.connectors.init]](../swirl/connectors/init.py) to avoid warnings, and the documentation has been updated.
Known Issues
🔹 SWIRL won't highlight terms that have preceeding or trailing quotes
For example 'hello or 'hello'. These may be quite acceptable to search engines as phrase searches. This will be fixed in a future release.
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this to support.
Upgrading
⚠️ Version 1.7 requires database migration. Details: Upgrading SWIRL
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented
🔹 Email: [email protected] with issues, requests, questions, etc - we'd love to hear from you!
Published by sidprobstein almost 2 years ago
This minor release resolves two issues as noted in the release notes:
https://github.com/sidprobstein/swirl-search/blob/main/docs/RELEASE_NOTES_1.6.1.md
Published by sidprobstein almost 2 years ago
![]()
SWIRL SEARCH 1.6
Version 1.6 shifts focus from relevancy to query adaptation with the new AdaptiveQueryProcessor that rewrites NOT or -term queries depending on SearchProvider configuration:



Also new: AND, + and OR are passed along to each SearchProvider and ignored by SWIRL SEARCH for relevancy and highlighting purposes.
PLEASE STAR OUR REPO: http://swirl.today/
New Features
🔹 The new AdaptiveQueryProcessor rewrites simple NOT and -term queries to the format supported by each SearchProvider, as defined in the query_mappings.
"query_mappings": "cx=7d473806dcdde5bc6,DATE_SORT=sort=date,PAGE=start=RESULT_INDEX,NOT_CHAR=-",
This indicates that the SearchProvider supports only the -term format. SWIRL rewrites a query like ...
elon musk NOT twitter
...to...
elon musk -twitter
This is noted in the Mixed results set under the SearchProvider block:
"Mergers & Acquisitions (web/Google PSE)": {
"query_string_to_provider": "elon musk -twitter",
"query_to_provider": "https://www.googleapis.com/customsearch/v1?cx=b384c4e79a5394479&key=AIzaSyDeB1y9l6OQW0dhVdZ9X_Xb2br_SK1K8YM&q=elon+musk+-twitter",
"result_processor": "MappingResultProcessor",
}
...etc...
},
"search": {
"query_string": "elon musk NOT twitter",
"query_string_processed": "elon musk NOT twitter",
},
🔹 The MappingResultsProcessor can map multiple result fields to a single SWIRL field using the | operator:
"result_mappings": "body=content|description...",
This configures SWIRL to populate the body result field with the content and/or description if populated. If both are populated, the second description field is placed in the payload for clarity.

🔹 scripts/email_load.py has been included to make it easy to load the Enron email dataset into ElasticSearch
Changes
🔹 swirl_load.py has been moved to the SWIRL root directory
swirl-search% python swirl_load.py SearchProviders/google_pse.json -a admin -p some-admin-password
##S#W#I#R#L##1#.#6##############################################################
swirl_load.py: fed 3 into SWIRL, 0 errors
🔹 The former GenericResultProcessor has been renamed MappingResultProcessor
A new GenericResultProcessor now takes no option on results, allowing connectors that already produce the SWIRL format to save processing.
Issues Resolved
🔹 Need to highlight alternative word forms
"explain": {
"stems": "agil oper",
"body": {
"agile_operations_*": 0.7048520990053376,
"agile_24": 0.589995250602152,
"operations_10": 0.8256623948725578,
"operating_19": 0.6893337836077386
}
}
🔹 Highlighting of terms with 's
"body": "*Elon* *Musk’s* top lieutenant at Tesla ... is now working at SpaceX after leaving Tesla over a strange controversy. more… The post *Elon* *Musk* moves his top lieutenant at Tesla to SpaceX after a controversy appeared first on Electrek ."
The updated CosineRelevancyProcessor should not allow this. Each term is highlighted once and only once. Please screen shot & report any examples to support.
🔹 swirl.py not working on some Ubuntu configs
swirl.py now checks to see if rabbitmq is running, and skips it if so:
sid@agentcooper swirl-search-master % python swirl.py start
##S#W#I#R#L##1#.#6##############################################################
Warning: rabbitmq appears to be running, skipping it:
501 95899 95503 0 1:54PM ttys000 0:00.01 /bin/sh /usr/local/sbin/rabbitmq-server
Start: django -> daphne swirl_server.asgi:application ... Ok, pid: 95948
Start: celery-worker -> celery -A swirl_server worker --loglevel=info ... Ok, pid: 95963
Start: celery-beats -> celery -A swirl_server beat -l INFO --scheduler django_celery_beat.schedulers:DatabaseScheduler ... Ok, pid: 95994
Updating .swirl... Ok
❤️ Thanks to all who reported this issue!!
Upgrading
For all platforms other than Docker, run the following from the command line, in the swirl installation folder:
./install.sh
Windows users should run install.bat instead!
🔑 If these scripts don't work for any reason, install manually:
pip install -r requirements.txt
python -m spacy download en_core_web_lg
python -m nltk.downloader stopwords
python -m nltk.downloader punkt
⚠️ Docker users need to restart their image to get the new version. Containers using sqlite3 for storage delete all content upon shut down! Read more: Docker Build for SWIRL
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this to support.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented
🔹 Email: [email protected] with issues, requests, questions, etc - we'd love to hear from you!
Published by sidprobstein almost 2 years ago
![]()
SWIRL SEARCH 1.5
This version consists of a new relevancy model supported by stemmed matching and cleaning of source responses.
⚠️ Installing the new packages is required before upgrading! Read more: Upgrading to 1.5
Changes
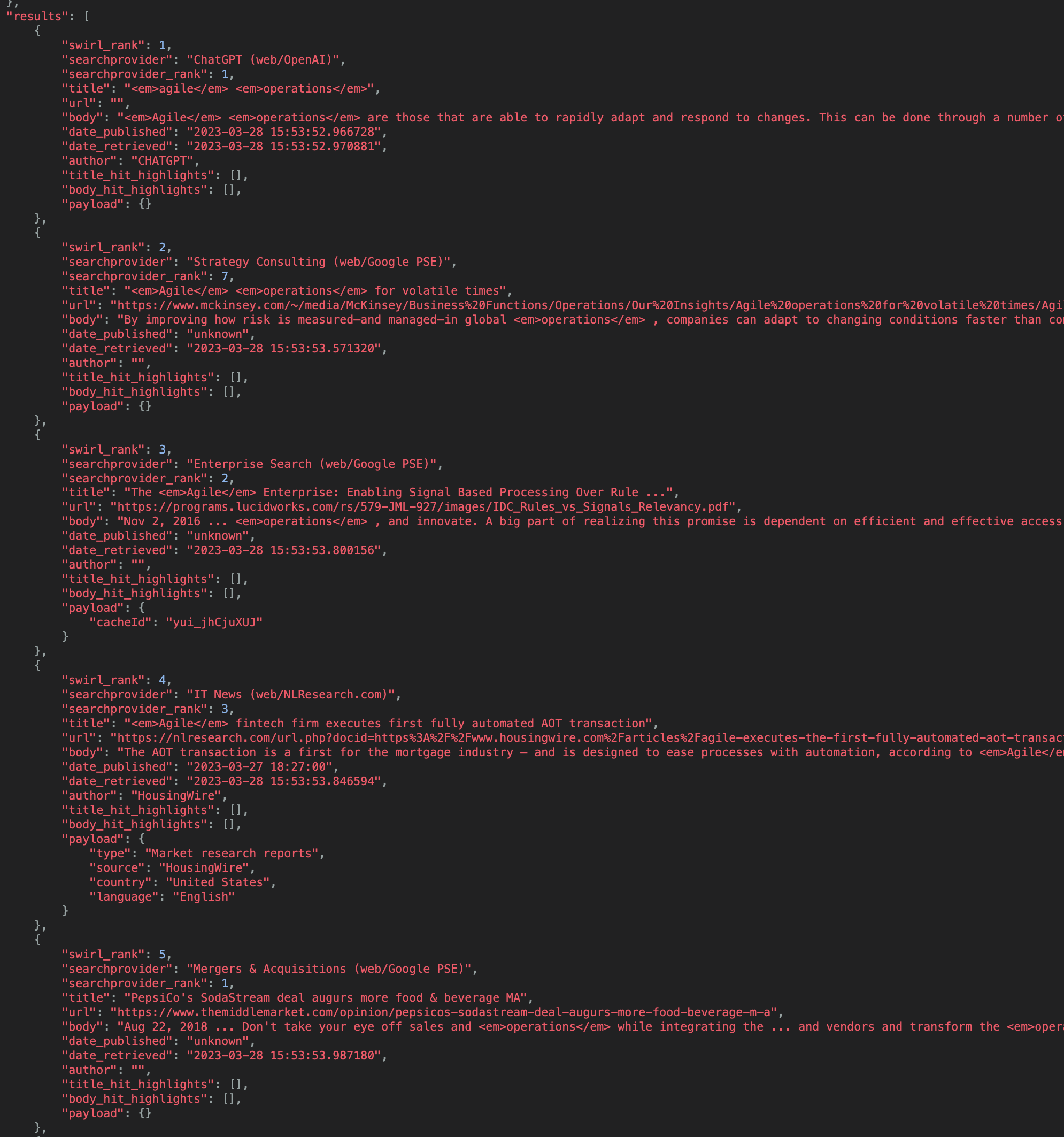
🔹 New relevancy model which weights and aggregates the similarity of each query match against the most relevant section of text, and normalizes results by length
🔹 Matching on stems using nltk and highlighting of actual matches
🔹 Removal of html tags and entities with Beautiful Soup
🔹 Relevancy scores are now broken by date_published, descending
Issues Resolved
🔹 Re-run and re-score now remove previous search.messages, and provide an update with timestamp
🔹 Fixed highlighting interaction with tags by removing tags prior to highlighting
Upgrading
For all platforms other than docker, run the following from the command line, in the swirl installation folder:
python install.py
./install.sh
(Windows users, run install.bat)
If these scripts don't work for any reason, install manually:
pip install -r requirements.txt
python -m spacy download en_core_web_lg
⚠️ Docker users need to restart their image to get the new version. Containers using sqlite3 for storage delete all content upon shut down! Read more: Docker Build for SWIRL
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this to support.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein almost 2 years ago
![]()
SWIRL SEARCH 1.5 BETA
This version consists of a new relevancy model supported by stemmed matching and cleaning of source responses.
⚠️ Installing the new packages is required before upgrading. Read more: Upgrading to 1.5
Changes
🔹 New relevancy model which weights and aggregates the similarity of each query match against the most relevant section of text, and normalizes results by length
🔹 Matching on stems using nltk and highlighting of actual matches
🔹 Removal of html tags and entities with Beautiful Soup
🔹 Relevancy scores are now broken by date_published, descending
Issues Resolved
🔹 Re-run and re-score now remove previous search.messages, and provide an update with timestamp
🔹 Fixed highlighting interaction with tags by removing tags prior to highlighting
Upgrading
For all platforms other than docker, run the following from the command line, in the swirl installation folder:
python install.py
./install.sh
(Windows users, run install.bat)
If these scripts don't work for any reason, install manually:
pip install -r requirements.txt
python -m spacy download en_core_web_lg
⚠️ Docker users need to restart their image to get the new version. Containers using sqlite3 for storage delete all content upon shut down! Read more: Docker Build for SWIRL
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this to support.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
![]()
SWIRL SEARCH 1.4
This version expands usability for multiple topics by adding default providers plus tagging of searchproviders, search and result objects. Tags can be specified freely in combination with provider name and/or id. More tag-based enhancements are coming soon.
Additions
🔹New SearchProvider properties "Default" and "Tags"
SearchProviders can now be organized using Tags - json lists that can hold any monicker desired for one or more providers. Tags can be specified in search objects using the searchprovider_list, and freely combined with provider names or IDs. If no searchprovider_list is specified, only providers with Default = True will be run.
This allows you to set up a set of general use providers as 'default' and ones for specific topics under various tags. For example:
SearchProvider:
{
"active": true,
"default": false,
"name": "Maritime News (web/Google PSE)",
"connector": "RequestsGet",
...etc...
"tags": [
"maritime"
]
},
Search:
{
"query_string": "strategic consulting",
"searchprovider_list": [ 6, 12, "maritime" ]
}
Read more: Organizing SearchProviders with Active, Default and Tags
🔹 New PostGresql Connector
The funding database example has also been updated to run with PostGresql.
{
"name": "Company Funding Records (local/sqlite3)",
"connector": "PostGresql",
"url": "host:port:database:username:password",
"query_template": "select {fields} from {table} where {field1} ilike '%{query_string}%' or {field2} ilike '%{query_string}%';",
"query_mappings": "fields=*,sort_by_date=fundedDate,table=funding,field1=city,field2=company",
"result_mappings": "title='{company} series {round}',body='{city} {fundeddate}: {company} raised usd ${raisedamt}\nThe company is headquartered in {city} and employs {numemps}',date_published=fundeddate,NO_PAYLOAD"
}
Read more: PostGresql Connector
Changes
🔹 New property SWIRL_EXPLAIN in swirl_server/settings.py now controls the default Relevancy explain setting.
SWIRL_EXPLAIN = True
The default is True.
🔹 Relevancy has been improved, particularly for one-term queries, and the all-terms boost has been retired.
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this to support.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
![]()
SWIRL SEARCH 1.3
This version incorporates additional usability feedback plus improvements to performance, configurability and
result format.
Changes
🔹 Mixers now support a single-provider filter.
For example:
http://localhost:8000/swirl/results/?search_id=1&provider=1
This allows front-ends to easily drill-down into a single source. Note that unless the SearchProvider is configured to request more than the default of 10 results, only one page of results will be available.
Paging beyond the initial result set is not currently supported by SWIRL, but could be in a future release.
🔹 Timings are now reported for each SearchProvider, and each search overall, in seconds.
"info": {
"Enterprise Search (web/Google PSE)": {
"found": 10,
"retrieved": 10,
"filter_url": "http://localhost:8000/swirl/results/?search_id=522&provider=3",
"query_to_provider": "https://www.googleapis.com/customsearch/v1?cx=0c38029ddd002c006&key=AIzaSyDeB1y9l6OQW0dhVdZ9X_Xb2br_SK1K8YM&q=strategic+consulting",
"result_processor": "GenericResultProcessor",
"search_time": 2.2
},
"results": {
"retrieved_total": 10,
"retrieved": 10,
"federation_time": 5.4
}
}
The "federation_time" includes:
- Pre-query processing
- Federation (query processing, response normalization, result processing)
- Post-result processing, including relevancy processing by default
🔹 Mappings have been reversed for clarity, and are now in the form swirl_key = source_mapping
All included SearchProviders have been updated. To migrate an existing SearchProvider, make the right-most key the left-most.
For example, change:
"query_mappings": "cx=0c38029ddd002c006,sort=date=DATE_SORT,start=RESULT_INDEX=PAGE",
"response_mappings": "searchInformation.totalResults=FOUND,queries.request[0].count=RETRIEVED,items=RESULTS",
"result_mappings": "link=url,htmlSnippet=body,cacheId,NO_PAYLOAD",
to:
"query_mappings": "cx=0c38029ddd002c006,DATE_SORT=sort=date,PAGE=start=RESULT_INDEX",
"response_mappings": "FOUND=searchInformation.totalResults,RETRIEVED=queries.request[0].count,RESULTS=items",
"result_mappings": "url=link,body=htmlSnippet,cacheId,NO_PAYLOAD",
🔹 Many hard-wired items are now in the swirl_server/settings.py file:
| Configuration item | Explanation | Example |
|---|---|---|
| HOSTNAME | Used to construct SWIRL URLs; as of SWIRL 1.3 this is the first ALLOWED_HOST entry | HOSTNAME = ALLOWED_HOSTS[0]\nHOSTNAME = 'myserver' |
| SWIRL_BANNER | The string to display in SWIRL data structures; please don't remove it (but you don't have to display it) | |
| SWIRL_TIMEOUT | The number of seconds to wait until declaring federation complete, and terminating any connectors that haven't responded | SWIRL_TIMEOUT = 10 |
| SWIRL_Q_WAIT | The number of seconds to wait before redirecting to the result mixer after using the q= parameter | SWIRL_Q_WAIT = 7 |
| SWIRL_RERUN_WAIT | The number of seconds to wait before redirecting to the result mixer when rerunning a search | SWIRL_Q_WAIT = 8 |
| SWIRL_RESCORE_WAIT | The number of seconds to wait before redirecting to the result mixer when rescoring a search | SWIRL_Q_WAIT = 3 |
Note that the configuration names must be UPPER_CASE per the django settings convention.
🔹 The relevancy explain block is now suppressed by default
To view the explain for any mixed result set, add explain=True to the mixer URL. For example:
http://localhost:8000/swirl/results/?search_id=1&explain=True
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this or the rerun function.
🔹 The Django admin form for managing Result objects throws a 500 error. P2.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
![]()
SWIRL SEARCH 1.2.1
This version continues improving developer usability and resolves issues found in 1.2.
Changes
🔹 New Object Oriented Processors
Query Processors: GenericQueryProcessor, GenericQueryCleaningProcessor
Result Processors: GenericResultProcessor
Post-Result Processors: CosineRelevancyProcessor
Here's the new GenericQueryCleaningProcessor - again around a 90% reduction in code vs 1.1:
class GenericQueryCleaningProcessor(QueryProcessor):
type = 'GenericQueryCleaningProcessor'
chars_allowed_in_query = [' ', '+', '-', '"', "'", '(', ')', '_', '~']
def process(self):
try:
query_clean = ''.join(ch for ch in self.query_string.strip() if ch.isalnum() or ch in self.chars_allowed_in_query)
except NameError as err:
self.error(f'NameError: {err}')
except TypeError as err:
self.warning(f'TypeError: {err}')
if self.input != query_clean:
logger.info(f"{self}: rewrote query from {self.input} to {query_clean}")
self.query_string_processed = query_clean
return self.query_string_processed
The only change required to use these processors is to change the "various processor" settings in the SearchProvider and Search objects).
All of the included SearchProviders have been updated.
For more information consult the Developers Guide Processors section.
🔹 Added use of django-environ to ease future deployments.
If you are installing locally, don't forget to install this package:
pip install django-environ
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this or the rerun function.
🔹 The q= search federation timer has been set more aggressively; if you are redirected to a results page and see the message "Results Not Ready Yet", wait a second or two and reload the page or hit the GET button and it should appear.
🔹 The Django admin form for managing Result objects throws a 500 error. P2.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
![]()
SWIRL SEARCH 1.2
This version incorporates tons of feedback around developer usability!
Changes
🔹 New Object Oriented Connectors & Mixers
The Connectors: RequestsGet (SOLR etc), Elastic, Sqlite3
The Mixers: RelevancyMixer, DateMixer, Stack1Mixer, Stack2Mixer, Stack3Mixer, StackNMixer
Here's the new DateMixer - everything but the imports - a 92% reduction in code from 1.1:

The only change required to use these connectors is to change the "Connector" setting in the SearchProvider. All of the included providers have been updated.
For more information consult the Developers Guide Connectors and Mixers sections
🔹 The new Mixers sort the Received messages for easy display:
"messages": [
"##S#W#I#R#L##1#.#2##############################################################",
"Retrieved 10 of 4740000000 results from: Strategy Consulting (web/Google PSE)",
"Retrieved 10 of 249000 results from: Enterprise Search (web/Google PSE)",
"Retrieved 10 of 1332 results from: IT News (web/NLResearch.com)",
"Retrieved 10 of 382 results from: Mergers & Acquisitions (web/Google PSE)",
"Retrieved 8 of 8 results from: Company Funding Records (local/sqlite3)",
"Retrieved 6 of 6 results from: ENRON Email (local/elastic)",
"Retrieved 1 of 1 results from: techproducts (local/solr)",
"Post processing of results by cosine_relevancy_processor updated 55 results",
"DateMixer hid 31 results with date_published='unknown'",
"Results ordered by: DateMixer"
]
Thanks to natsort, which is now required by SWIRL for this amazing capability! To install natsort:
pip install natsort
🔹 No longer boosting single term queries

Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this or the rerun function.
🔹 The q= search federation timer has been set more aggressively; if you are redirected to a results page and see the message "Results Not Ready Yet", wait a second or two and reload the page or hit the GET button and it should appear.
🔹 The Django admin form for managing Result objects throws a 500 error. P2.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
![]()
SWIRL SEARCH 1.2
Changes
🔹 New Object Oriented Connectors!
The Connectors have been renamed for clarity:
- Elastic
- RequestsGet
- Sqlite3
The only change required to use these connectors is to change the "Connector" setting in the SearchProvider. All of the included providers have been updated.
For more information consult the Developers Guide, Connectors sections
🔹 New Object Oriented Mixers!
The Mixers have been renamed for clarity:
- RelevancyMixer
- DateMixer
- Stack1Mixer aka RoundRobinMixer
- Stack2Mixer
- Stack3Mixer
- StackNMixer
The only change required to use these connectors is to specify the name correctly in the Search object.
For more information consult the Developers Guide, Mixers section
🔹 The new Mixers sort the Received messages for easy display:
"messages": [
"##S#W#I#R#L##1#.#2##############################################################",
"Retrieved 10 of 4740000000 results from: Strategy Consulting (web/Google PSE)",
"Retrieved 10 of 249000 results from: Enterprise Search (web/Google PSE)",
"Retrieved 10 of 1332 results from: IT News (web/NLResearch.com)",
"Retrieved 10 of 382 results from: Mergers & Acquisitions (web/Google PSE)",
"Retrieved 8 of 8 results from: Company Funding Records (local/sqlite3)",
"Retrieved 6 of 6 results from: ENRON Email (local/elastic)",
"Retrieved 1 of 1 results from: techproducts (local/solr)",
"Post processing of results by cosine_relevancy_processor updated 55 results",
"DateMixer hid 31 results with date_published='unknown'",
"Results ordered by: DateMixer"
]
Thanks to natsort, which is now required by SWIRL for this amazing capability! To install natsort:
pip install natsort
🔹 No longer boosting single term queries
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This is because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this or the rerun function.
🔹 The q= search federation timer has been set more aggressively; if you are redirected to a results page and see the message "Results Not Ready Yet", wait a second or two and reload the page or hit the GET button and it should appear.
🔹 The Django admin form for managing Result objects throws a 500 error. P2.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein about 2 years ago
SWIRL SEARCH 1.1.1 Now Available
This release resolves issues found in version 1.1.
Changes
🔹 Added missing date_mixer to search model choice, so it can now be specified
This change requires a change to the model database, so migration is required after updating to the latest version of the repo, and prior to starting SWIRL:
cd swirl-search
git pull
python swirl.py migrate
python swirl.py start
🔹 Reverted recent changes to processor/relevancy.py that reduced term and phrase_boost; they made results worse
Known Issues
🔹 Creating searches from a browser with q= can sometimes create two Search objects.
This appears to be because of browser prefetch. Turn off Chrome prefetch. Turn off Safari prefetch
Please report any issues with this or the rerun function.
🔹 The Django admin form for managing Result objects throws a 500 error. P2.
🔹 Watch out for log files in logs/*.log. They'll need periodic purging. Rollover is planned for a future release.
Documentation
Support
🔹 Create an Issue if something doesn't work, isn't clear, or should be documented - we'd love to hear from you!
🔹 Paid support and consulting are available... contact SWIRL for more information.
Published by sidprobstein over 2 years ago
SWIRL SEARCH 1.1 Now available
Summary of Changes
🔹 New SearchProvider for Apache Solr - tested against 8.1
🔹 New SearchProvider for Northern Light's NLResearch.com service - subscription required
🔹 New Date Sort Mixer omits documents with unknown date_published
🔹 New SearchProvider for newsdata.io service - subscription required
🔹 Revised requests_get connector now supports most any json response by configuration
🔹 Google PSE SearchProvider revised to use requests_get
🔹 Former Google opensearch connector retired
🔹 There are new query mappings DATE_SORT, RELEVANCY_SORT and PAGE, and new result mappings FOUND, RETRIEVED, RESULTS and RESULT now available for the requests_get connetor
🔹 Updated Round Robin and Stack mixers now use relevancy as primary sort
🔹 All mixed results now include swirl_rank, swirl_score, retrieved_total and links to rescore/re-run searches
Full Announcement
Published by sidprobstein over 2 years ago
This new release of SWIRL:
- Adds support for apache solr
- Adds support for Northern Light's NLResearch.com service
- Removes the former opensearch connector
- Includes a new version of the requests_get connector that supports configuration of key mappings
- Adds a start_sleep command to swirl.py for use in docker and other container schemes
Review the release notes
This update is recommended for all users.
Published by sidprobstein over 2 years ago
This update release of SWIRL:
- Check for 'static' folder in root directory when running python swirl.py setup
- Updated logo
This update is recommended for all users.
Published by sidprobstein over 2 years ago
This update release resolves issues, including:
It is recommended for all users.
Full Changelog: https://github.com/sidprobstein/swirl-search/compare/v1.0...v1.0.1
Published by sidprobstein over 2 years ago
- Asynchronous search federation via REST APIs
- Data landed in Sqlite for later consumption
- Pre-built searchprovider definitions for http_get, google PSE, elasticsearch and Sqlite
- Sample data sources for use with Sqlite
- Sort results by provider date or relevancy, page through all results requested
- Result mixers operate on landed results and order results by relevancy, date, stack or round-robin
- Cosine similarity relevancy using Spacy vectors with field boosts and explanation
- Optional spell correction using TextBlob
- Optional search/result expiration service to limit storage use
For more information: