
ppspider
web spider built by puppeteer, support task-queue and task-scheduling by decorators,support nedb / mongodb, support data visualization; 基于puppeteer的web爬虫框架,提供灵活的任务队列管理调度方案,提供便捷的数据保存方案(nedb/mongodb),提供数据可视化和用户交互的实现方案
MIT License
- Quick Start
- Deploy with docker
- Examples
-
ppspider System Introduction
- Decorator
-
PuppeteerUtil
- PuppeteerUtil.defaultViewPort
- PuppeteerUtil.addJquery
- PuppeteerUtil.jsonp
- PuppeteerUtil.setImgLoad
- PuppeteerUtil.onResponse
- PuppeteerUtil.onceResponse
- PuppeteerUtil.downloadImg
- PuppeteerUtil.links
- PuppeteerUtil.count
- PuppeteerUtil.specifyIdByJquery
- PuppeteerUtil.scrollToBottom
- PuppeteerUtil.parseCookies
- PuppeteerUtil.useProxy
- PuppeteerUtil example
- NetworkTracing
- Database
- logger
- Debug
- Related Information
- WebUI
- Question
- Update Note
Quick Start
Install NodeJs
Install TypeScript
npm install -g typescript
Prepare the development environment
Recommended IDEA(Ultimate version)

Nodejs And Javascript Configuration in IDEA

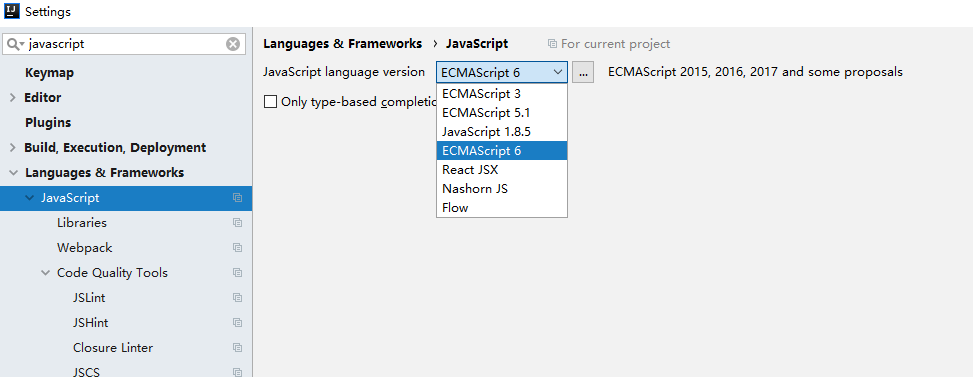
Download And Run ppspider_example
ppspider_example github address https://github.com/xiyuan-fengyu/ppspider_example
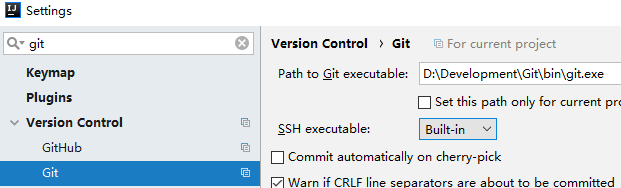
Clone ppspider_example with IDEA
Warning: git is required and the executable file path of git should be set in IDEA
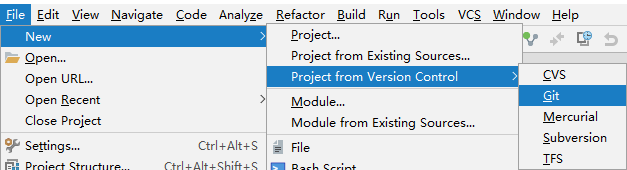

Install npm dependencies
Click "Terminal" on the bottom side of IDEA to open a terminal and run the following command
npm install
Run tsc
Run 'tsc' in terminal Or ContextMenu on package.json -> Show npm Scripts -> Double click 'auto build' tsc is a TypeScript compiler which can auto compile the ts file to js file after any ts file change
Startup ppspider App
Run lib/quickstart/App.js Open http://localhost:9000 in the browser to check the ppspider's status
Deploy with docker
https://github.com/xiyuan-fengyu/ppspider_docker_deploy/blob/master/README.en.md
Examples
- Monitor website access speed, visualize real-time statistics, and view the details of all requests in the process of opening a web page ppspider-webMonitor
- Dynamically set task parallel via cron expressions DynamicParallelApp
- If you wants some queues to not be executed immediately after the application is started, look this QueueWaitToRunApp
- Web page screenshot, super long page is supported ScreenshotApp
- Get video's infos and comments from https://www.bilibili.com BilibiliApp
- Set proxy for a page Page Proxy
- QQ music info and comments QQ Music
- request + cheerio, crawling static web pages CheerioApp
- Twitter get topic comments and user info TwitterApp
- Depth-First-Search,DFS (By default, DefaultQueue is breadth-first search) DepthFirstSearchApp
- request + cheerio, crawling static web pages QuotesToScrapeApp
-
Music 163 download Music163App
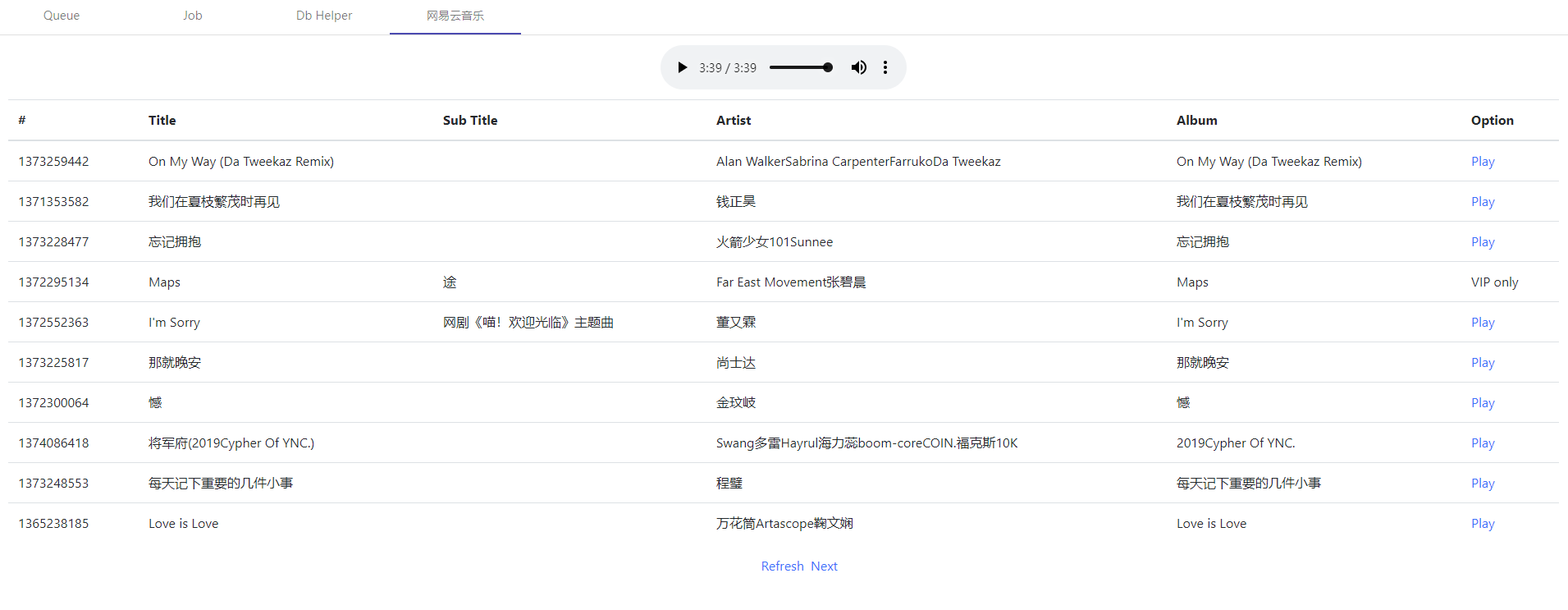
- ProxyPool
- Bandcamp Music download
- Set max try num of job SetMaxTryApp
- Page.evaluate with async function PuppeteerEvalAsyncApp
- Set AddToQueue/FromQueue name with a regexp string to create a series of queues dynamically AddToRegexQueue
- Drag to complete the puzzle PuppeteerUtil.dragJigsaw
- Solve the problem that some requests work abnormally HandlBadRequestOnHeadlessApp
ppspider System Introduction
Decorator
Declare like
export function TheDecoratorName(args) { ... }
Usage
@TheDecoratorName(args)
Decorator is similar of look with java Annotation, but Decorator is stronger. Decorator can provide meta data by parameters and modify the target or descriptor to change behavior of class or method In ppspider, many abilities are provided by Decorator
@Launcher
export function Launcher(theAppInfo: AppInfo) { ... }
Launcher of a ppspider app Params type
export type AppConfig = {
// all cache files and the db file will be saved to the workplace folder. You can save the data files to this folder too.
workplace: string;
// file path to save the running status,default is workplace + "/queueCache.json"
queueCache?: string;
// database url, nedb or mongodb is supported. When the app will generate a little amount of data, use nedb, the url format: nedb://nedbDirPath; Otherwise, mongodb is recommended, the url format: mongodb://username:password@host:port/dbName. The default value is "nedb://" + appInfo.workplace + "/nedb"
dbUrl?: string;
// import all task class
tasks: any[];
// import all DataUi class
dataUis?: any[];
// all workerFactory instances, only PuppeteerWorkerFactory, NoneWorkerFactory is provided at present
workerFactorys: WorkerFactory<any>[];
// the port for web ui,default 9000
webUiPort?: number | 9000;
// logger setting
logger?: LoggerSetting;
}
@OnStart
export function OnStart(config: OnStartConfig)
A job executed once after app start, but you can execute it again by pressing the button in webUI. The button will be found after the queue name in webUI's Queue panel.
Params type
export type OnStartConfig = {
// urls to crawl
urls: string | string[];
// if set true, this queue will not run after startup
running?: boolean;
// config of max paralle num, can be a number or a object with cron key and number value
parallel?: ParallelConfig;
// the execute interval between jobs, all paralle jobs share the same exeInterval
exeInterval?: number;
// make a random delta to exeInterval
exeIntervalJitter?: number;
// Task timeout, in milliseconds, default: 300000, negative number means never timeout
timeout?: number;
maxTry?: number;
// description of this sub task type
description?: string;
// default BloonFilter,the job won't execute again after save and restart. If you want to re-execute, use NoFilter
filterType?: Class_Filter;
// default content of job.datas
defaultDatas?: any;
}
@OnTime
export function OnTime(config: OnTimeConfig) { ... }
A job executed at special times resolved by cron expression Params type
export type OnTimeConfig = {
urls: string | string[];
cron: string; // cron expression
running?: boolean;
parallel?: ParallelConfig;
exeInterval?: number;
exeIntervalJitter?: number;
timeout?: number;
maxTry?: number;
description?: string;
defaultDatas?: any;
}
@AddToQueue @FromQueue
Those two should be used together, @AddToQueue will add the function's result to job queue, @FromQueue will fetch jobs from queue to execute
@AddToQueue
export function AddToQueue(queueConfigs: AddToQueueConfig | AddToQueueConfig[]) { ... }
@AddToQueue accepts one or multi configs Config type:
export type AddToQueueConfig = {
// queue name
name: string;
// queue provided: DefaultQueue(FIFO), DefaultPriorityQueue
queueType?: QueueClass;
// filter provided: NoFilter(no check), BloonFilter(check by job's key)
filterType?: FilterClass;
}
You can use @AddToQueue to add jobs to a same queue at multi places, the queue type is fixed at the first place, but you can use different filterType at each place.
The method Decorated by @AddToQueue shuold return a AddToQueueData like.
export type CanCastToJob = string | string[] | Job | Job[];
export type AddToQueueData = Promise<CanCastToJob | {
[queueName: string]: CanCastToJob
}>
If @AddToQueue has multi configs, the return data must like
Promise<{
[queueName: string]: CanCastToJob
}>
PuppeteerUtil.links is a convenient method to get all expected urls, and the return data is just AddToQueueData like.
@FromQueue
export function FromQueue(config: FromQueueConfig) { ... }
export type FromQueueConfig = {
// queue name
name: string;
running?: boolean;
parallel?: ParallelConfig;
exeInterval?: number;
exeIntervalJitter?: number;
// Task timeout, in milliseconds, default: 300000, negative number means never timeout
timeout?: number;
maxTry?: number;
description?: string;
defaultDatas?: any;
}
@AddToQueue @FromQueue example
@JobOverride
export function JobOverride(queueName: string) { ... }
Modify job info before inserted into the queue. You can set a JobOverride just once for a queue.
A usage scenario is: when some urls with special suffix or parameters navigate to the same page, you can modify the job key to some special and unique id taken from the url with a JobOverride. After that, jobs with duplicate keys will be filtered out.
Actually, sub task type OnStart/OnTime is also managed by queue whose name just likes OnStart_ClassName_MethodName or OnTime_ClassName_MethodName, so you can set a JobOverride to it. JobOverride example
@Serializable @Transient
export function Serializable(config?: SerializableConfig) { ... }
export function Transient() { ... }
@Serializable is used to mark a class, then the class info will keep during serializing and deserializing. Otherwise, the class info will lose when serializing.
@Transient is used to mark a field which will be ignored when serializing and deserializing. Warn: static field will not be serialized. These two are mainly used to save running status. You can use @Transient to ignore fields which are not related with running status, then the output file will be smaller in size. example
@RequestMapping
export function RequestMapping(url: string, method: "" | "GET" | "POST" = "") {}
@RequestMapping is used to declare the HTTP rest interface, providing the ability to dynamically add tasks remotely. Returning the crawl results requires self-implementation (such as asynchronous url callbacks). RequestMapping example
@Bean @Autowired
仿造 java spring @Bean @Autowired 的实现,提供实例依赖注入的功能 example
@DataUi @DataUiRequest
You can define you own tab page in UI(http://localhost:webPort) by this which can extend support for data visualization and user interaction You should import the DataUiClass in @Launcher appConfig.dataUis
There is a built-in DataUi DbHelperUi which can support db search
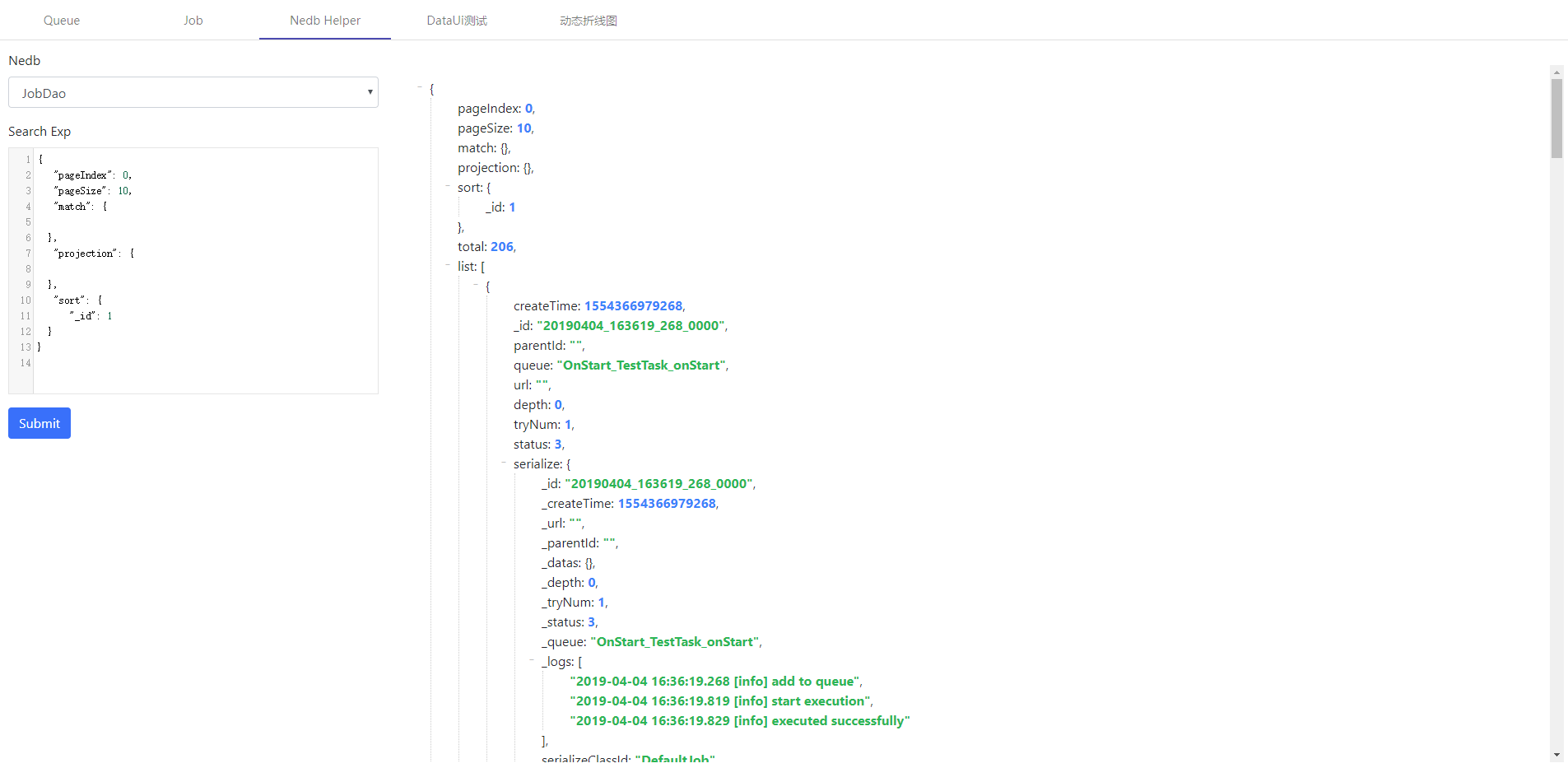
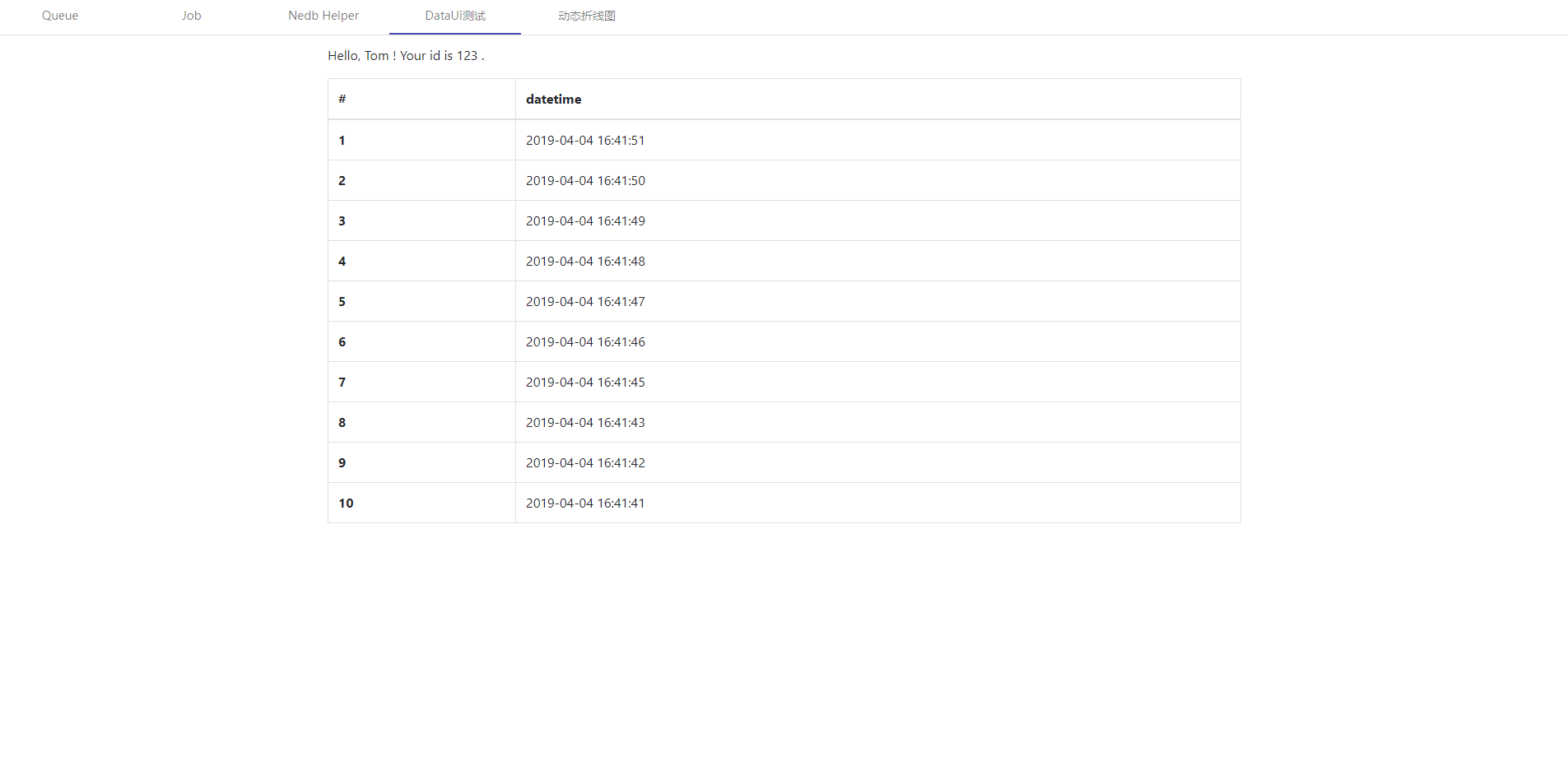
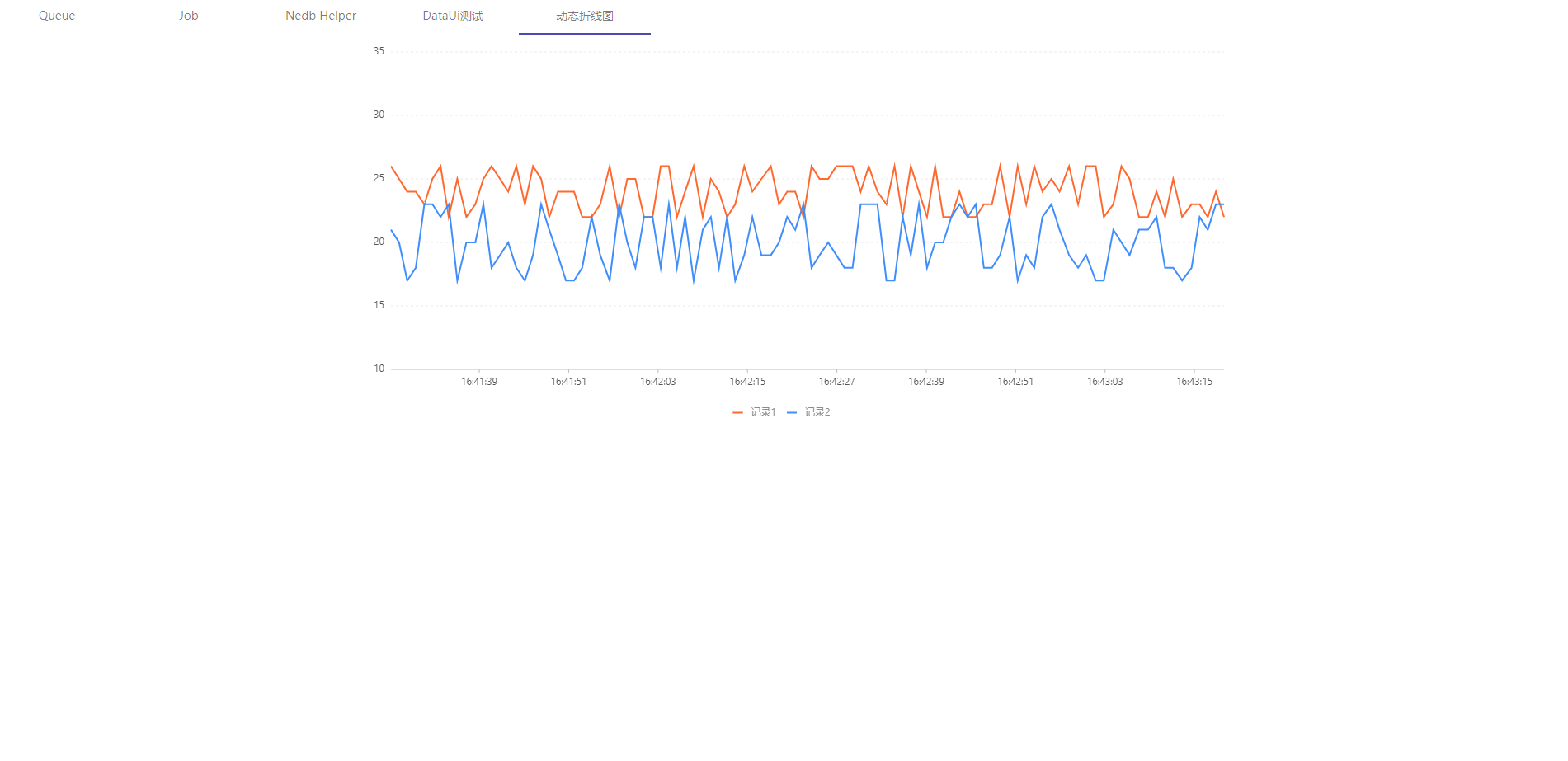
example 2 Add Dynamic Job On UI
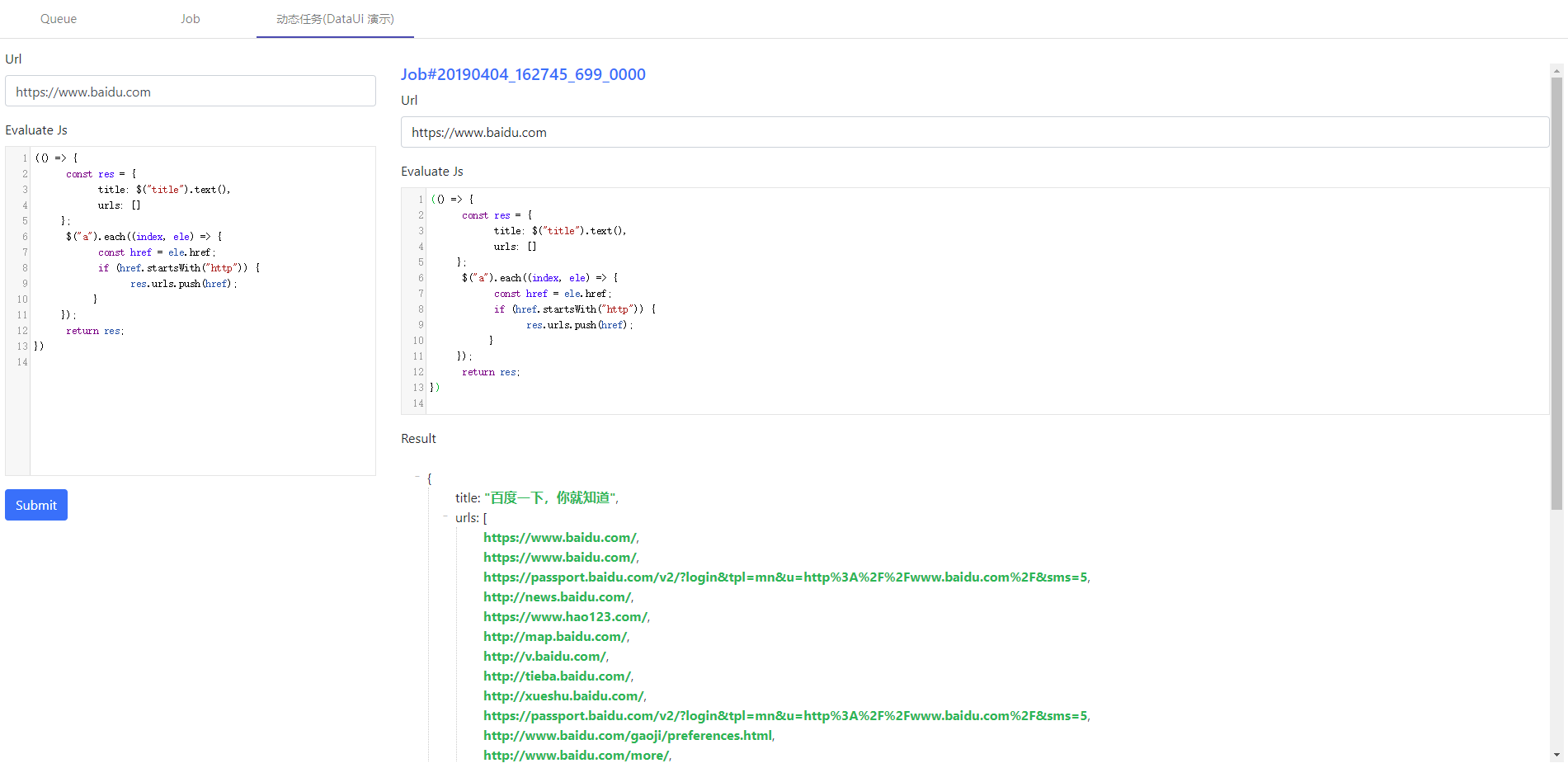
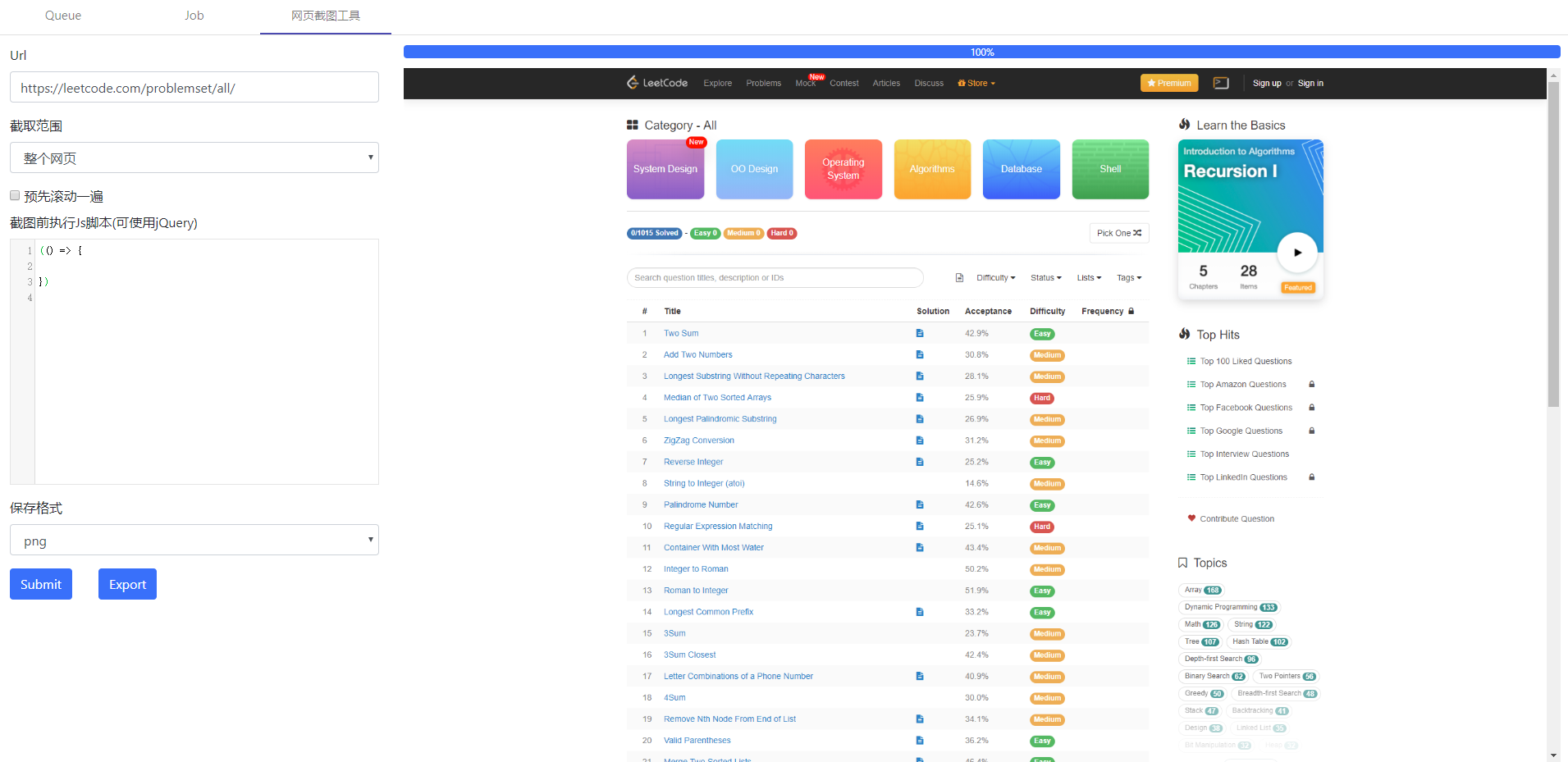
example 3 Web Page Screenshot
Long web page screenshot is also supported
PuppeteerUtil
PuppeteerUtil.defaultViewPort
set page's view port to 1920 * 1080
PuppeteerUtil.addJquery
inject jquery to page, jquery will be invalid after page refresh or navigate, so you should call it after page load.
PuppeteerUtil.jsonp
parse json in jsonp string
PuppeteerUtil.setImgLoad
enable/disable image load
PuppeteerUtil.onResponse
listen response with special url, max listen num is supported
PuppeteerUtil.onceResponse
listen response with special url just once
PuppeteerUtil.downloadImg
download image with special css selector
PuppeteerUtil.links
get all expected urls
PuppeteerUtil.count
count doms with special css selector
PuppeteerUtil.specifyIdByJquery
Find dom nodes by jQuery(selector) and specify random id if not existed, finally return the id array. A usage scenario is: In puppeteer, all methods of Page to find doms by css selector finally call document.querySelector / document.querySelectorAll which not support some special css selectors, howerver jQuery supports. Such as: "#someId a:eq(0)", "#someId a:contains('next')". So we can call specifyIdByJquery to specify id to the dom node and keep the special id returned, then call Page's method with the special id.
PuppeteerUtil.scrollToBottom
scroll to bottom
PuppeteerUtil.parseCookies
Parse cookie string to SetCookie Array,than set coookie through page.setCookie(...cookieArr) How to get cookie string? open interested url in chrome-> press F12 to open devtools -> Application panel -> Storage:Cookies: -> cookie detail in the left panel -> choose all by mouse,press Ctrl+c to copy all You will get something similar to the following
PHPSESSID ifmn12345678 sm.ms / N/A 35
cid sasdasdada .sm.ms / 2037-12-31T23:55:55.900Z 27
PuppeteerUtil.useProxy
Set dynamic proxy for a single page
PuppeteerUtil example
PuppeteerUtil example Single Page Proxy
NetworkTracing
Recode all requests during page opening NetworkTracing example
Database
Nedb is supported by NedbDao. Mongodb is supported by MongodbDao. You can set the "dbUrl" in @Launcher parameters, then use appInfo.db to visist db. All metheds defined in src/common/db/DbDao. Nedb is a server-less database, no need to install the server end, the data will be persisted to the local file. Url format: nedb://nedbDirectoryPath. When the amount of data is large, the data query speed is slow, and it will take a lot of time to load data each time you restart the application, so use it only if the data is small. Mongodb needs to install the mongo server. The url format: mongodb://username:password@host:port/dbName. It is recommended to save a large amount of data.
After the application is started, a job collection is automatically created to save the job info during execution.
logger
Use logger.debug, logger.info, logger.warn or logger.error to print log. Those functions are defined in src/common/util/logger.ts. The output logs contain extra info: timestamp, log level, source file position.
logger.debugValid && logger.debug("test debug");
logger.info("test info");
logger.warn("test warn");
logger.error("test error");
Debug
simple typescript/js code can be debugged in IDEA
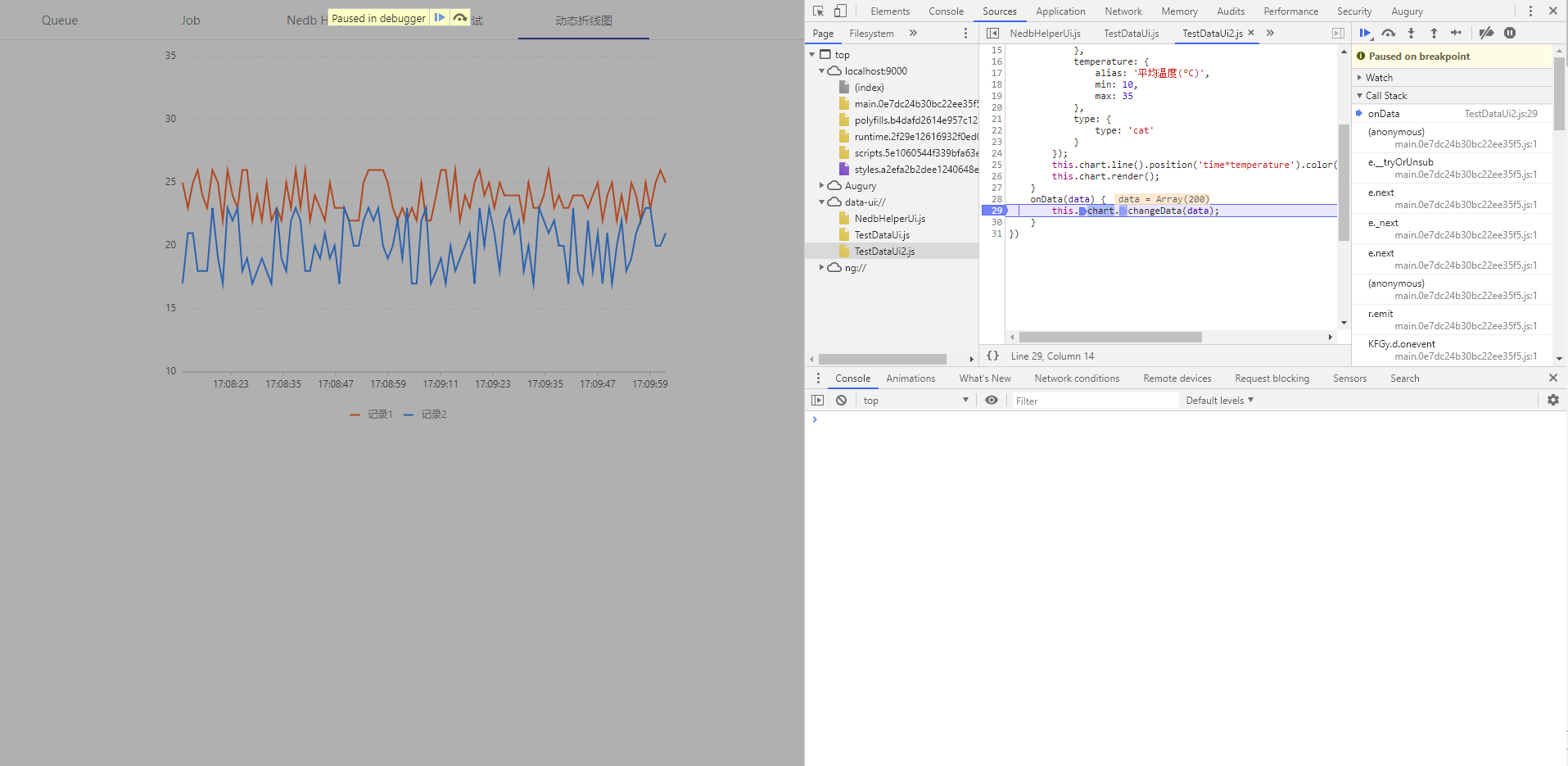
The inject js code can be debugged in Chromium. When building the PuppeteerWorkerFactory instance, set headless = false, devtools = true to open Chromium devtools panel. Inject js debug example
import {Launcher, PuppeteerWorkerFactory} from "ppspider";
import {TestTask} from "./tasks/TestTask";
@Launcher({
workplace: __dirname + "/workplace",
tasks: [
TestTask
],
workerFactorys: [
new PuppeteerWorkerFactory({
headless: false,
devtools: true
})
]
})
class App {
}
import {Job, OnStart, PuppeteerWorkerFactory} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
await page.goto(job.url());
const title = await page.evaluate(() => {
debugger;
const title = document.title;
console.log(title);
return title;
});
console.log(title);
}
}
In addition, when developing DataUi, you can debug it in browser
Related Information
jQuery
http://www.runoob.com/jquery/jquery-syntax.html
puppeteer
https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
nedb
https://github.com/louischatriot/nedb
mongodb
https://docs.mongodb.com/manual/reference/method/js-collection/
Angular
G2
https://antv.alipay.com/zh-cn/g2/3.x/demo/index.html G2 integrated in web ui for data visualization in DataUi
bootstrap
https://v3.bootcss.com/css/ The web ui integrates bootstrap and jquery which make it easy to use the bootstrap and jquery to write the ui interface directly in DataUi.
WebUI
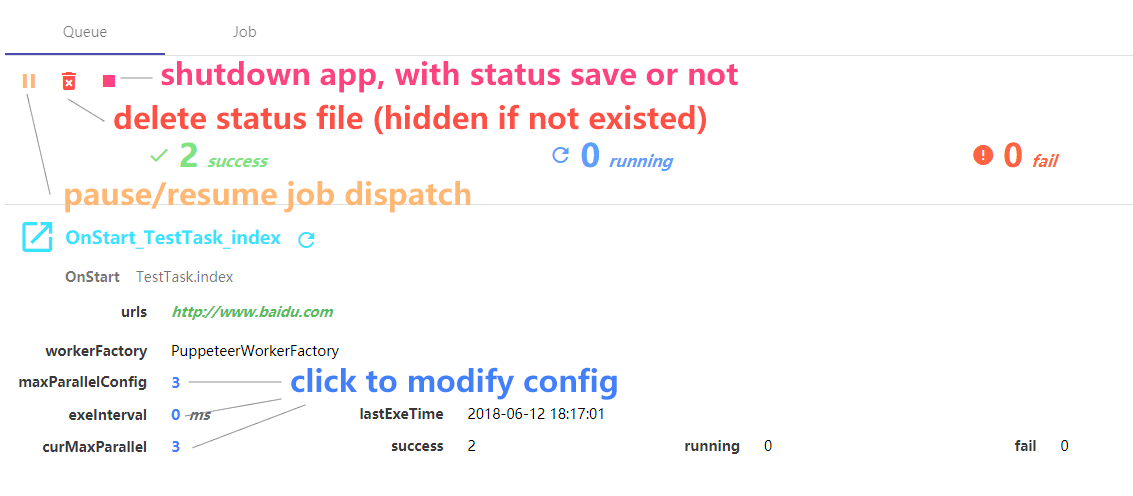
open http://localhost:9000 in browser
Queue panel: view and control app status
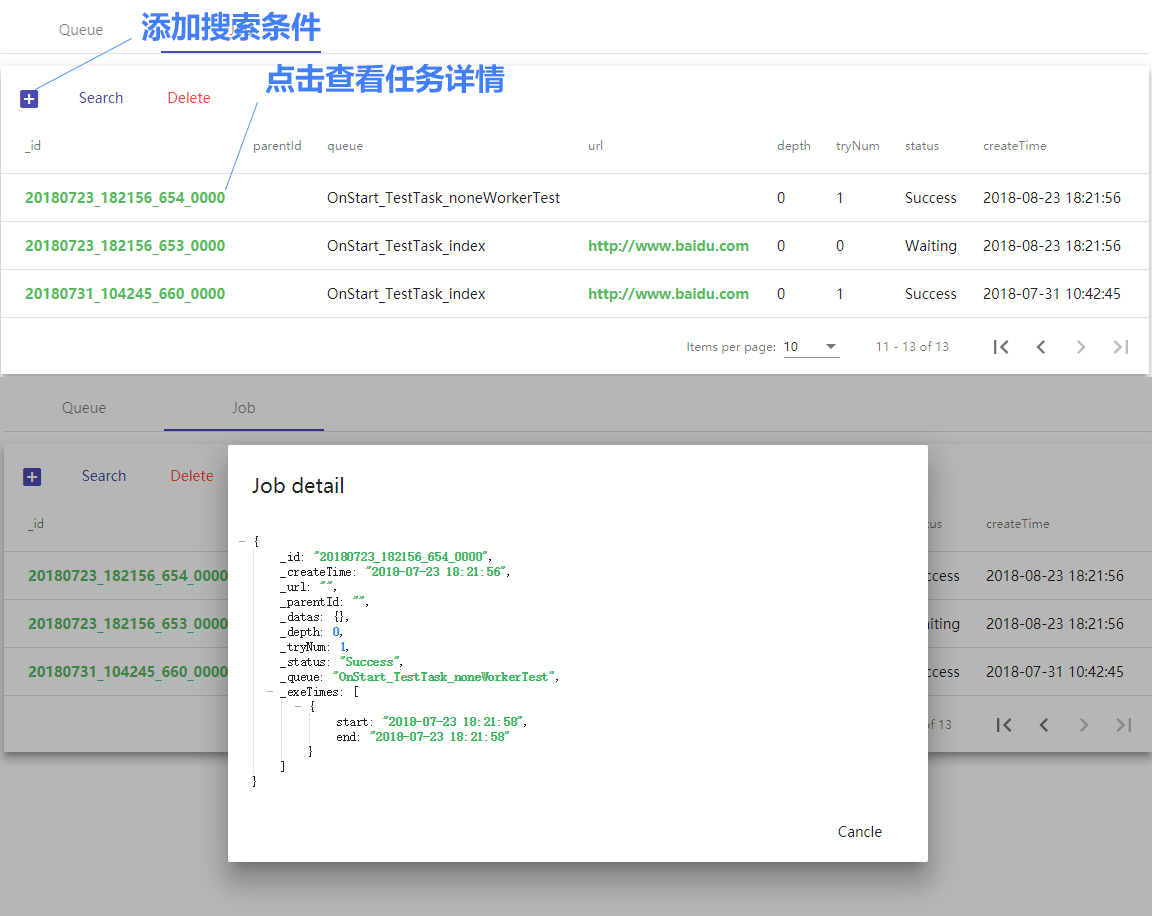
Job panel: search jobs and view details
Question
-
When running an app in idea under debug mode after a long time, the application may get stucked on a code line just like a breakpoint stop. It is due to low memory, just add a node paramter "--max-old-space-size=8192" to solve it. This situation has often appeared in previous versions, mainly due to nedb write/read process or serialization/deserialization process of QueueManager. In the new version (v2.1.2), it has been optimized.
-
When using the v2.2.0+ version, the workerFactory property is removed from @OnStart, @OnTime, @FromQueue. If you want to use the puppeteer page to crawl the website, You can import the Page class via
import {Page} from "ppspider";and then declare a page: Page parameter in the parameter list of the callback function. If use Import {Page} from "puppeteer" to import Page, the imported Page is just an interface, which cannot be determined at runtime by reflect-metadata, and the page instance will not be injected successfully. This error is checked during startup.
Update Note
2020-12-07 v2.2.4-preview.1607350101966
- Modify puppeteer's default userDataDir to prevent generating excessive temporary folders when puppeteer crashes unexpectedly
- Add worker info in QueueManager_JobExecuted event
- rewrite EventBus to await EventBus.emit
2020-04-07 v2.2.3
- fix bug: in case of cross-domain, page.frames may not find some iframes.
- optimize PuppeteerUtil.dragJigsaw implementation to improve accuracy.
2019-09-04 v2.2.3-preview.1578363288631
- fix bug in job interruption
2019-09-04 v2.2.3-preview.1577332807380
- fix bug: job is no longer retried after being interrupted on UI interface
- add maxTry parameter for task and queue configuration, support always try when maxTry is less than 0
- add defaultDatas parameter for task and queue configuration as the default value for job.datas
- add the operation of switching the running state of the queue on UI interface
- add the operation to edit timeout/maxTry/defaultDatas paramters on UI interface
2019-09-04 v2.2.3-preview.1574909694087
- OnStart can be configured to use BloonFilter(default, will not re-run after saving status and restart) or NoFilter(will re-run after saving status and restart)
- fix a bug in db search by page
- add a new decorator called OnEvent, used to watch system event, there is only one use presently OnEvent Example
2019-09-04 v2.2.3-preview.1569208986875
- fix bug: null pointer error in src/common/db/MongodbDao.ts#remove
- add a new parameter to transfer the parent job info for JobOverride callback method
- ignore classes which are not marked with @Serializable during the serialization process
- fix bug: match with RegExp.toString
- Add SocksProxyAgent support in RequestUtil
2019-07-31 v2.2.2-preview
- @Bean @Autowired bug fixed, support type identification for @Autowired
- Add new method RequestUtil.linesToHeaders to parse header-lines; add headerLines property to the parameter named options of
RequestUtil.simple, add an optional parameter handler to watch the response - Add cookies automatically when using PuppeteerUtil.useProxy to proxy requests
- Add async function support for Page.evaluate, evaluateOnNewDocument, evaluateHandle, $eval, $$eval
- Page import fixed
- Add UserAgents util to get random user-agent
- Add regexp support for AddToQueue/FromQueue name(example)
- Set Page default viewport as 1920 * 1080, set navigator.webdriver=false
- Add a new function PuppeteerUtil.drag to drag bar
- Add a new PuppeteerUtil.triggerAndWaitRequest to trigger and watch a request
- Add a new PuppeteerUtil.triggerAndWaitResponse to trigger a request and watch the response
- Provides solutions for slider verification
Drag from left to right PuppeteerUtil.dragBar
Drag to the right place to complete the puzzle PuppeteerUtil.dragJigsaw
2019-06-22 v2.2.1
-
Rewrite the way to inject the worker instance through the reflection mechanism provided by typescript and reflect-metadata during calling method decorated by @OnStart, @OnTime, @FromQueue. The workerFactory property of @OnStart, @OnTime, @FromQueue is removed. The freamwork check the parameter types of the decorated method to determine whether the job parameter needs to be passed, whether the worker instance needs to be passed (if true, which worker type is the correct one). The order and number of parameters are no longer fixed.
But there are also restrictions, in the parameters, at most one with the Job type, and at most one with the worker type which has the corresponding WorkerFactory definition (only Page is currently provided). Be careful that the class Page is provided in the ppspider package, not the interface Page defined in @types/puppeteer.
Because of this change, some code needs to be upgraded. You need to remove the workerFactory property in @OnStart, @OnTime, @FromQueue. If you want to use page: Page in the method decorated by @OnStart, @OnTime, @FromQueue, you need to import {Page} from "ppspider" instead of "puppeteer", other parameters except job: Job should be removed. The order and name of the parameters can be defined freely. If the job: Job is not used in the method, you can also remove this parameter.
-
Fixed a bug: @AddToQueue does not work without @OnStart / @OnTime / @FromQueue.
-
Add deployment scheme based on docker
2019-06-13 v2.1.11
- fix the once listener bug in PuppeteerWorkerFactory.overrideMultiRequestListenersLogic
- add Buffer type to the parameter content in FileUtil.write
- in process of QueueManager.loadFromCache, fix the lastExeTime of queue
- change the dependencies of ui: bootstrap(3.4.1), g2(@antv/g2, @antv/data-set)
- define window.__awaiter in ui, to support async and await in DataUi
- define window.loadScript in ui, make it easy to load third-party script in DataUi
- JobOverride supports async callback methods; change the timing that JobOverride calls callback method.
2019-06-06 v2.1.10
- Override Add/Remove/Query request listener of Page to ensure that a page has only one request listener(theOnlyRequestListener).
The user-added request listener will be called via theOnlyRequestListener.
Whether to call request.continue is no longer confusing. - Override the process of AddToQueue to add the method result to queues, so that Filter supports asynchronous check.
- Rewrite the proxy process of PuppeteerUtil.useProxy by request.
- The description of fail / failed is added to the UI interface. The number of failed in the queue shows two numbers:
the number of failed tries, and the number of tasks that still fail after the maximum number of tries.
2019-06-03 v2.1.9
- Fix bug: app stoped if exception occurred during request proxy in PuppeteerUtil.useProxy
2019-06-02 v2.1.8
- Add new method: PuppeteerUtil.useProxy, to support single page proxy
- update puppeteer version to 1.17.0
2019-05-28 v2.1.6
- Fix a wrong ref of URL model in MongodbDao
- Fix a bug to parse date in PuppeteerUtil.parseCookie
2019-05-24 v2.1.3
- On Job panel of ui interface, change "createTime" to text input, accurate to milliseconds
- Fix bug during deleting job.
- Rewrite the method to set parallel by cron expressions, then the parallel will be setted immediately after the application launch.
2019-05-21 v2.1.2
- Rewrite the serialization and deserialization process to solve the problem of large object serialization failure.
- Delete DefaultJob, change interface Job to class Job, and the methods are changed to corresponding fields. This change causes historical QueueCache data to be incompatible.
- Override the process of loading and saving Nedb to support reading and writing large amounts of data.
- Rewrite NedbDao, provide new mongodb support: MongodbDao. They two are compatible with reading and writing data. Users can directly use @Launcher dbUrl to configure the database, and operate the database through appInfo.db.
2019-05-09 v2.0.5
- Change cron lib: later -> cron
- Update the logic to calculate the next execution time of OnTime Job
2019-05-08 v2.0.4
- Upgrade puppeteer: v1.15.0
- Rewrite the serialization and deserialization process to solve the problem of large object serialization failure
Due to this change, if you need to use the old queueCache.json which saved the running state, you can upgrade this file as following:
Import UpgradeQueueCacheTask at "@Launcher tasks",
Rename the old queueCache.json to queueCache_old.json and put it in the workplace directory,
Start the app and the queueCache.txt will be generated in the workplace directory,
Remove UpgradeQueueCacheTask at "@Launcher tasks".
2019-04-29 v2.0.3
- When the ui interface switches tab pages, the previous tab page will not be destroyed.
- fix bug: PuppeteerUtil.links can't find urls when passing Regex parameter.
- fix bug: Nedb uses string concatenation to build new data content during the process of compressing data.
Memory overflow occurs when the amount of data is large.
2019-04-29 v2.0.2
- Output colorful logs using ansi-colors
2019-04-22 v2.0.1
- add RequestUtil, Encapsulate request as a promise style call
- Modify the declaration of NedbHelperUi.defaultSearchExp to avoid error reporting during ts compilation
2019-04-04 v2.0.0
- Multiple task threads of the same queue in the QueueManager no longer share a single wait interval
- The QueueManager can forcibly interrupt the execution of a running job (the UI Job panel provides an interactive button)
By codeappInfo.eventBus.emit(Events.QueueManager_InterruptJob, JOB_ID, "your interrupt reason"); - Status can be saved when ppspider is running
- Added @Bean @Autowired decorator to provide dependency injection programming
- Added @DataUi @DataUiRequest decorator to provide custom UI tab page, user can customize data visualization page, interactive tool
2019-01-28 v0.1.22
- Automatically clear jobs marked as filtered.
- Add job (status: Fail | Success) to queue by clicking button on the Job UI .
2018-12-24 v0.1.21
- Add timeout to task configuration, default 300000ms
- Add logs to job during task execution to analysis execution time and failure reasons
2018-12-10 v0.1.20
- Fix a bug: duplicate instances of the same user defined Task are created
2018-11-19 v0.1.19
- Fix a bug: the logger always print error as '{}'.
- You can select multiple items when the condition has a list of options on the UI interface.
- Update puppeteer version to 0.10.0.
2018-09-19 v0.1.18
- Change the reference address of the exported class in index.ts to the original path,
so that the user can locate the source code location in the editor quickly. - Print job detail when an error occurred.
- The number of job failures increases after all attempts fail.
- The parameter list of several methods declared in the logger to print log is changed to an indefinite parameter list.
The format parameter is no longer accepted. The indefinite parameter list is used as the message list, and the messages are automatically divided by '\n';
The logger automatically converts obj to string using JSON.stringify(obj, null, 4). - Add a new property named "exeIntervalJitter" to OnStart, OnTime, FromQueue, it makes a random jitter in a range to the execution interval(exeInterval).
default: exeIntervalJitter = exeInterval * 0.25 - Add a new property named "running" to OnStart, OnTime, FromQueue to control the queue running status, default is true.
Change the running status like following:mainMessager.emit(MainMessagerEvent.QueueManager_QueueToggle_queueName_running, queueNameRegex: string, running: boolean) - The nedb related code in JobManager is rewritten with NedbDao
- Add a decorator @RequestMapping to declare the HTTP rest interface, providing the ability to dynamically add jobs remotely.
Returning the crawl results requires self-implementation (such as asynchronous url callbacks).
2018-08-24 v0.1.17
- In job detail modal, add support to recursively load the parent job detail,
add target="_blank" to all 'a' elements to open a new tab when clicked - The push mode of spider system info is changed from periodic to event driven and delayed
- Update puppeteer version to 1.7.0
- Add NoneWorkerFactory whose init action is not required, it is used when puppeteer is not required
- Complement the SSS of logger datetime with 0
- The job with empty url is accepted now
2018-07-31 v0.1.16
- Fix bug: no effect after setting maxParallelConfig=0
- Update puppeteer version to 1.6.1-next.1533003082302 to solve the bug which causes loss of response in version 1.6.1 of puppeteer
2018-07-30 v0.1.15
- Change the implement of PuppeteerUtil.addJquery
Change the inject way of jQuery because Page.addScriptTag is not supported
by some website - Fix bug: PuppeteerWorkerFactory.exPage compute a wrong position of js executing error
- Fix bug: The CronUtil.next may generate a next execute time which equals to the last job
2018-07-27 v0.1.14
- Add support to logger level check
Add support to change logger config
Logger config can be set in @launcher - Change the parameter of DefaultJob.datas to optional
- Enhance the page created by PuppeteerWorkerFactory, methods such as
$eval, $$eval, evaluate, evaluateOnNewDocument, evaluateHandle are improved,
when the inject js executes with error, it will print the detail and position
of error - Change the implement of serialize
- Add comments to source code
- Update puppeteer version
2018-07-24 v0.1.13
- Import source-map-support, add logger to print log with source code position
2018-07-23 v0.1.12
- Add @Transient Decorator to ignore field when serialization
2018-07-19 v0.1.11
- Set the max wait time to 60 secondes when spider system shutdown,
those jobs which are not complete will become fail once and add to queue
to try again - Fix bug: img url match is incorrect
2018-07-16 v0.1.8
- Implement a serialization util to solve the circular reference question