
netdata
The open-source observability platform everyone needs!
GPL-3.0 License
Bot releases are hidden (Show)
Published by Ferroin over 2 years ago
Table of contents
- Release highlights
- Acknowledgments
- Contributions
- Deprecation notice
- Netdata Agent release meetup
- Support options
❗ We're keeping our codebase healthy by removing features that are end of life. Read the deprecation notice to check if you are affected.
Netdata open-source Agent statistics
- 7.6M+ troubleshooters monitor with Netdata
- 1.3M+ unique nodes currently live
- 3.3k+ new nodes per day
- Over 556M Docker pulls all-time total
Release highlights
Anomaly Advisor & on-device Machine Learning
We are excited to launch one of our flagship machine learning (ML) assisted troubleshooting features in Netdata: the Anomaly Advisor.
Netdata now comes with on-device ML! Unsupervised ML models are trained for every metric, at the edge (on your devices), enabling real time anomaly detection across your infrastructure.

This feature is part of a broader philosophy we have at Netdata when it comes to how we can leverage ML-based solutions to help augment and assist traditional troubleshooting workflows, without having to centralize all your data.
The new Anomalies tab quickly lets you find periods of time with elevated anomaly rates across all of your nodes. Once you highlight a period of interest, Netdata will generate a ranked list of the most anomalous metrics across all nodes in the highlighted timeframe. The goal is to quickly let you find periods of abnormal activity in your infrastructure and bring to your attention the metrics that were most anomalous during that time.
In our latest release, we improved the usability of Anomaly Advisor and also ensured that the anomalous metrics are always relevant to the time period you are investigating.
A great deal of care has gone into ensuring that ML running on your device is as light weight in terms of resource consumption as possible. For instance, metrics that do not have sufficient data for training and metrics that are consistently constant during training periods are considered to be "normal" until their behavior changes significantly to require re-training of the ML models.
To use this feature, please enable ML on your agent and then navigate to the "Anomalies" tab in Netdata cloud. Update netdata.conf with the following information to enable ML on your agent:
[ml]
enabled = yes
Read more about Anomaly Advisor at our blog.
Metrics Correlation on Agent
Metric Correlations allow you to quickly find metrics and charts related to a particular window of interest that you want to explore further. Metric correlations compare two adjacent windows to find how they relate to each other, and then score all metrics based on this rating, providing a list of metrics that may have influence or have been influenced by the highlighted one.
Metric Correlation was already available in Netdata Cloud, but now we are releasing a version implemented at the Netdata Agent, which drastically reduces the time required for to run. This means the metric correlation can now run almost instantly (more than 10x faster than before)!
To enable the new metric correlation at the Netdata Agent, set the following in your netdata.conf file:
[global]
enable metric correlations = yes
Kubernetes monitoring
On very busy Kubernetes clusters where hundreds of containers spawn and are destroyed all the time, Netdata was consuming a lot of resources and was slow to detect changes and under certain conditions it missed certain containers.
Now, Netdata:
- Detects "pause" containers and skips them greatly improving the performance during discovery
- Detects containers that are initializing and postpones discovery for them until they are properly initialized
- Utilizes less resources more efficiently during container discovery
Netdata is also capable of detecting the network interfaces that have been allocated to containers, by spawning a process that switches network namespace and identifies virtual interfaces that belong to each container. This process is improved drastically, now requiring 1/3 of the CPU resources it needed before.
Additionally, Netdata cgroups.plugin now collects CPU shares for Kubernetes containers, allowing the visualization of the Kubernetes CPU Requests (Kubernetes writes in cgroup CPU Shares the CPU Requests that have been configured for the containers).
A new option has been added in netdata.conf [plugin:cgroup] section, to allow filtering containers by (resolved) name. It matches the name of the cgroup (as you see it on the dashboard).
We have also released a blog post and a video about CPU Throttling in Kubernetes. You will be amazed by our findings. Read the blog and watch the video about Kubernetes CPU throttling.
Visualization improvements
Netdata Cloud dashboards are now a lot faster in aggregating data from multiple agents, as the protocol between agents and the Cloud is approaching its final shape.
New look for Netdata charts
Netdata Cloud has a new look and feel for charts, which resembles the look and feel for coding IDEs:

New home for war rooms
The new home tab for war rooms allows you to quickly inspect the most important metrics for every war room, like number of nodes, metrics, retention, replication, alerts, users, custom dashboards, etc.

Time units
Time units now in charts auto-scale from microseconds to days, automatically based on the value of time to be shown.
Cloud queries timeout
The agent now sets a timeout on every query it sends to the agents, and the agents now respect this timeout. Previously, the cloud was timing out because of a slow query, but the agents remained busy executing that query, which had a waterfall effect on the agent load.
Custom dashboards
Custom dashboards on Netdata Cloud can now be renamed.
Alerts management
All configured alerts on the Cloud
We have added a new Alert Configs sub tab which lists all the alerts configured on all the nodes belonging to the war room. You have now a possibility of listing the alerts configured in the - war room, nodes and alert instances respectively.
Stale alerts
There have been a number of corner cases under which alerts could remain raised on Netdata cloud. We identified all such cases, and now Netdata Cloud is always in sync with Netdata agents about their alerts.
Nodes management
Cloud provider metadata
Netdata now identifies the Cloud provider node type it runs on. It works for GCP and AWS, and exposes this information at the Nodes tab, the single node dashboard, and the node inspector.

Virtualization detection fixes
We improved the virtualization detection in cases where systemd is not available. Now Netdata can properly detect virtualization even in these cases.
Global nodes filter on all tabs of a space
The new Netdata Cloud now supports a global filter on nodes of war rooms. The new filter is applied on every tab for each room, allowing users to quickly switch between tabs while retaining the nodes filtered.
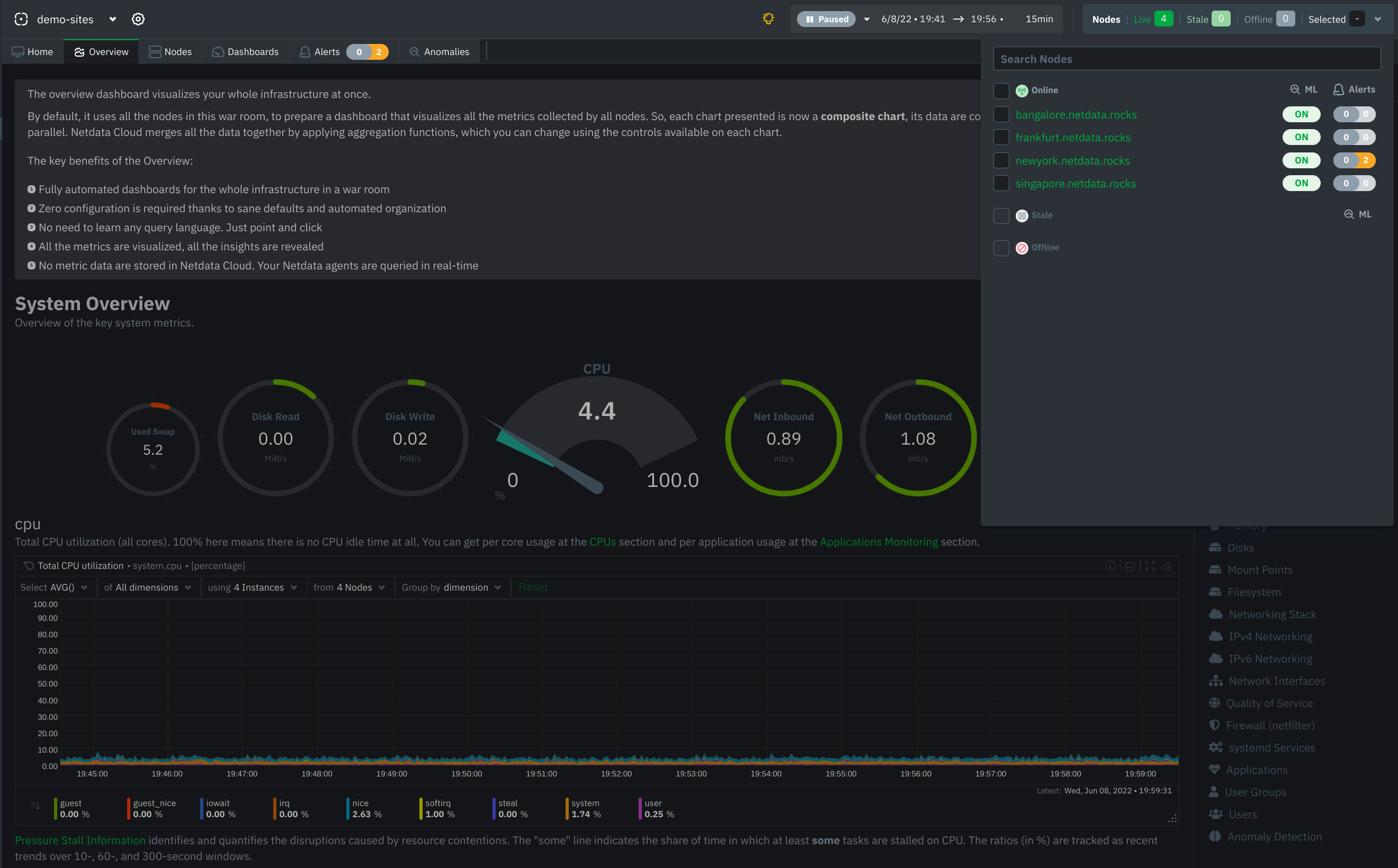
Obsoletion of nodes
Netdata admin users now have the ability to remove obsolete nodes from a space. Many users have been eagerly waiting for this feature, and we thank you for your patience. We hope you will be happy to use the feature and have cleaner spaces and war rooms. A few notes to be considered:
- Only admin users have the ability to obsolete nodes
- Only offline nodes can be marked obsolete (Live nodes and stale nodes cannot be obsoleted)
- Node obsoletion works across the entire space, so the obsoleted node will be removed from all rooms belonging to the space
- If the obsoleted nodes eventually become live or online once more, they will be automatically re-added to the space
StatsD improvements
Every Netdata Agent is a StatsD server, listening on localhost port 8125, both TCP and UDP. You can use the Netdata StatsD server to quickly visualize metrics from scripts, Cron Job, and local applications.
In this release, the Netdata StatsD server has been improved to use Judy arrays for indexing the collected metrics, drastically improving its performance.
At the same time we extended the StatsD protocol to support dictionaries . Dictionaries are similar to sets, but instead of reporting only the number of unique entries in the set, dictionaries create a counter for each of the values and report the number of occurrences for each unique event. So, to quickly get a break down of events, you can push them to StatsD like myapp.metric:EVENT|d. StatsD will create a chart for myapp.metric and for each unique EVENT it will create a dimension with the number of times this events was encountered.
We also added the ability to change the units of the chart and the family of the chart, using StatsD tags, like this: myapp.metric:EVENT|d|#units=events/s.
Finally, StatsD now automatically creates a dashboard section for every StatsD application name. Following StatsD best practices, these application names are considered to be the first keyword of collected metrics. For example, by pushing the metric myapp.metric:1|c, StatsD will create the dashboard section "StatsD myapp".
Read more at the Netdata StatsD documentation. A real-life example of using Netdata StatsD from a shell script pushing in realtime metric to a local Netdata Agent, is available at this stress-with-curl.sh gist.
3x faster agent queries
Netdata dashboards refresh all visible charts in parallel, utilizing all the resources the web browsers provide to quickly present the required charts. Since Netdata only stores metric data at the agents, all these queries are executed in parallel at the agents.
This parallelism of queries is even more intense when metrics replication/streaming is configured. In these cases, parent Netdata agents centralize metric data from many agents, and, since Netdata Cloud prefers the more distant parents for queries, they receive quite a few queries in parallel for all their children.
We also reworked many parts of the query engine of Netdata agents to achieve top performance in parallel queries. Now, Netdata agents are able to perform queries at a rate of more than 30 million points per second, per core on modern hardware. On a parent Netdata agent with a 24-core CPU we observed a sustained rate of 1.3 billion points per second! This is 3 times faster compared to the previous release.
To achieve this performance improvements we worked in these areas:
Query memory management
When querying metric data, a lot of memory allocations need to happen. Although Netdata agents automatically adapt their memory requirements for data collection avoiding memory operations while iterating to collect data, unfortunately at the query engine site, this is not feasible.
To make the agent more efficient for queries, the number of system calls allocating memory had to be drastically decreased. So, we developed a One Way Allocator (OWA), a system that works like a scratchpad for memory allocations. When the query starts, we now predict the amount of memory needed to execute the query. The query engine still does all the individual allocations, but all these are now made against the scratchpad, not against the system. OWA is smart enough to increase the size of the scratchpad if needed during querying. And it frees all memory at once without the need for individual memory releases.
For huge data queries, the benefit is astonishing. For certain heavy data queries, 45000 memory allocations before are down to 20 with this release! This doubled the performance of the query engine.
Number unpacking
To optimize its memory footprint for metric data, Netdata agents store collected metric data into a fixed step database (after interpolation) with a custom floating point number format we developed (we call it storage_number), requiring just 4 bytes per data collection point, including the timestamp. When on disk, mainly due to compression, Netdata's dbengine needs just 0.34 bytes per point (including all metadata), which is probably the best among all monitoring solutions available today, allowing Netdata to massively store and manage metric data at a very high rate.
This means however, that in order to actually use a point in a query, we have to unpack it. This unpacking happens point-by-point even for data cached in memory. 1 billion points in a data query, 1 billion numbers unpacked.
In this release we analyzed the CPU cache efficiency of the number unpacking and we refactored it to make the best use of available CPU caches to finally increase its performance by 30%.
Streaming
This release includes a better algorithm to pick the available parent to stream metrics to. The previous version was always reconnecting to the first available parent. Now it rotates them, one by one and then restarts.
An issue was fixed regarding parents with stale alerts from disconnected children. Now, the parent validates all alerts on every child re-connection.
Netdata parents now have a timeout to cleanup dead/abandoned children connections automatically.
We also worked to eliminate most of the bottlenecks when multiple children connect to the same parent. But this is still under testing, so it will make it in the next release.
More optimizations
Workers optimizations
Netdata uses many workers to execute several of its features. There are web workers, aclk workers, dbengine
workers, health monitoring workers, libuv workers, and many more.
We manage to identify a lot of deadlocks happening that slowed down the whole operation. We also
increased the amount of workers to deliver more capacity on busy parents.
There is a new section for monitoring Netdata workers at the "Netdata Monitoring" section of the dashboard. Using this
work we are still working to make them even more efficient.
Deadlocks
The last release was hindered by rare deadlocks on very busy parents. These deadlocks are now gone, improving the agents ability to centralize data from many children.
Dictionaries are now using Judy arrays
Judy arrays are probably the fastest and most CPU cache-friendly indexes available. Netdata already uses them for
dbengine and its page cache. Now all Netdata dictionaries are using them too, giving a performance boost to all
dictionary operations, including StatsD.
/proc collectors are now a lot faster >
Initialization of /proc collectors was suboptimal, because they had to go over a slow process or adapting their read
buffers. We added a forward-looking algorithm to optimize this initialization, which now happens in 1/10th of the
time.
/proc/netdev collector is now isolated
Some users have experiences gaps in /proc plugin charts. We identified that these gaps were triggered by the netdev module, which were cause the whole plugin to slow down and miss data collection iterations.
Now the netdev module of /proc plugin runs on its own thread to avoid this influencing the rest of the /proc
modules.
Internal Web Server optimizations
The internal web server of Netdata now spreads the work among its worker threads more evenly, utilizing as much of the
parallelism that is available to it.
Options in netdata.conf re-organized
We re-organized the [global] section of the netdata.conf, so that it is more meaningful for new users. The new
configurations are backward compatible. So, after you restart netdata with your old netdata.conf, grab the new one
from http://localhost:19999/netdata.conf to have the new format.
New MQTT Client - Tech Preview
We now have our own MQTT implementation within our ACLK protocol that will eventually replace the current MQTT-C client
for several reasons, including the following:
- With the new MQTT implementation we now support MQTTv5 as our older implementation only supported MQTTv3
- Reduce memory usage - no need for large fixed size buffers to be allocated all the time
- Reduce memory copying - no need to copy message contents multiple times
- Remove max message size limit
- Remove issues where big messages are starving other messages
Currently, it’s provided as a tech preview, and it’s disabled by default. Feel free to have some fun with the new
implementation. This is how to enable it in netdata.conf:
[cloud]
mqtt5 = yes
Acknowledgments
- @JaphethLim for adding priority to Gotify notifications.
-
@MarianSavchuk for adding Alma and Rocky distros as CentOS compatibility distro in
netdata-updater. - @aberaud for working on configurable storage engine.
- @atriwidada for improving package dependency.
- @coffeegrind123 for adding Gotify notification method.
- @eltociear for fixing "GitHub" spelling in docs.
-
@fqx for adding
tailscaledto apps_groups.conf. -
@k0ste for updating
net,aws, andhagroups in apps_groups.conf. - @kklionz for fixing a compilation warning.
- @olivluca for fixing appending logs to the old log file after logrotate on Debian.
- @petecooper for improving the usage message in netdata-installer.
-
@simon300000 for adding
caddyto apps_groups.conf.
Contributions
Collectors
New
- Add "UPS Load Usage" in Watts chart (charts.d/apcupsd) (#12965, @ilyam8)
- Add Pressure Stall Information stall time charts (proc.plugin, cgroups.plugin) (#12869, @ilyam8)
- Add "CPU Time Relative Share" chart when running inside a K8s cluster (cgroups.plugin) (#12741, @ilyam8)
- Add a collector that parses the log files of the OpenVPN server (go.d/openvpn_status_log) (#675, @surajnpn)
Improvements
⚙️ Enhancing our collectors to collect all the data you need.
- Add Tailscale apps_groups.conf (apps.plugin) (#13033, @fqx)
- Skip collecting network interface speed and duplex if carrier is down (proc.plugin) (#13019, @vlvkobal)
- Run the /net/dev module in a separate thread (proc.plugin) (#12996, @vlvkobal)
- Add dictionary support to statsd (#12980, @ktsaou)
- Add an option to filter the alarms (python.d/alarms) (#12972, @andrewm4894)
- Update net, aws, and ha groups in apps_groups.conf (apps.plugin) (#12921, @k0ste)
- Add k8s_cluster_name label to cgroup charts in K8s on GKE (cgroups.plugin) (#12858, @ilyam8)
- Exclude Proxmox bridge interfaces (proc.plugin) (#12789, @ilyam8)
- Add filtering by cgroups name and improve renaming in K8s (cgroups.plugin) (#12778, @ilyam8)
- Execute the renaming script only for containers in K8s (cgroups.plugin) (#12747, @ilyam8)
- Add k8s_qos_class label to cgroup charts in K8s (cgroups.plugin) (#12737, @ilyam8)
- Reduce the CPU time required for cgroup-network-helper.sh (cgroups.plugin) (#12711, @ilyam8)
- Add Proxmox VE processes to apps_groups.conf (apps.plugin) (#12704, @ilyam8)
- Add Caddy to apps_groups.conf (apps.plugin) (#12678, @simon300000)
Bug fixes
🐞 Improving our collectors one bug fix at a time.
- Fix adding wrong labels to cgroup charts (cgroups.plugin) (#13062, @ilyam8)
- Fix cpu_guest chart context (apps.plugin) (#12983, @ilyam8)
- Fix counting unique values in Sets (statsd.plugin) (#12963, @ktsaou)
- Fix collecting data from uninitialized containers in K8s (cgroups.plugin) (#12912, @ilyam8)
- Fix CPU-specific data in the "C-state residency time" chart dimensions (proc.plugin) (#12898, @vlvkobal)
- Fix memory usage calculation by considering ZFS ARC as cache on FreeBSD (freebsd.plugin)(#12879, @vlvkobal)
- Fix disabling K8s pod/container cgroups when fail to rename them (cgroups.plugin) (#12865, @ilyam8)
- Fix memory usage calculation by considering ZFS ARC as cache on Linux (proc.plugin) (#12847, @ilyam8)
- Fix adding network interfaces when the cgroup proc is in the host network namespace (cgroups.plugin) (#12788, @ilyam8)
- Fix not setting chart units (go.d/snmp) (#682, @ilyam8)
- Fix not collecting Integer type values (go.d/snmp) (#680, @surajnpn)
eBPF
- Add CO-RE algorithms to all threads related to memory (#12684, @thiagoftsm)
- Fix wrong chart type for ip charts (#12698, @thiagoftsm)
- Fix disabled apps (ebpf.plugin) (#13044, @thiagoftsm)
- Fix "libbpf: failed to load" warnings (#12831, @thiagoftsm)
- Re-enable socket module by default (#12702, @ilyam8)
Health
- Fix not respecting host labels when creating alerts for children instances (#13053, @MrZammler)
- Expose anomaly-bit option to health (#12835, @vkalintiris)
- Add priority to Gotify notifications to trigger sound & vibration on the Gotify phone app (#12753, @JaphethLim)
- Add Gotify notification method (#12639, @coffeegrind123)
Streaming
- Improve failover logic when the Agent is configured to stream to multiple destinations (#12866, @MrZammler)
- Increase the default "buffer size bytes" to 10MB (#12913, @ilyam8)
Exporting
- Add the URL query parameter that filters charts from the /allmetrics API query (#12820, @vlvkobal)
- Make the "send charts matching" option behave the same as the "filter" URL query parameter for prometheus format (#12832, @ilyam8)
Documentation
📄 Keeping our documentation healthy together with our awesome community.
- Add note about Anomaly Advisor (#13042, @andrewm4894)
- Add a note on possibly alternate location of the cloud.d directory (#12987, @cakrit)
- Improve instructions on how to reconnect a node to Cloud (#12891, @cakrit)
- Fix unresolved file references (#12872, @ilyam8)
- Update ML defaults in docs (#12782, @andrewm4894)
- Add parent-child configuration examples to ML docs (#12734, @andrewm4894)
- Add a note about serial numbers in chart names in the plugins.d API documentation (#12733, @vlvkobal)
- Fix a typo in macOS documentation (#12724, @MrZammler)
- Add a description of interactive/non-interactive modes to the "Uninstall Netdata" doc (#12687, @odynik)
- Fix "GitHub" spelling (#12682, @eltociear)
- Add new dashboard/web server reference file (#11161, @joelhans)
Packaging / Installation
📦 "Handle with care" - Just like handling physical packages, we put in a lot of care and effort to publish beautiful
software packages.
- Add Alma Linux 9 and RHEL 9 support to CI and packaging (#13058, @Ferroin)
- Fix handling of temp directory in kickstart when uninstalling (#13056, @Ferroin)
- Only try to update repo metadata in updater script if needed (#13009, @Ferroin)
- Use printf instead of echo for printing collected warnings in kickstart (#13002, @Ferroin)
- Don't kill Netdata PIDs if successfully stopped Netdata in installer/uninstaller (#12982, @ilyam8)
- Properly handle the case when 'tput colors' does not return a number in kickstart (#12979, @ilyam8)
- Update libbpf version to v0.8.0 (#12945, @thiagoftsm)
- Update default fping version to 5.1 (#12930, @ilyam8)
- Update go.d.plugin version to v0.32.3 (#12862, @ilyam8)
- Autodetect channel for specific version in kickstart (#12856, @maneamarius)
- Fix "Bad file descriptor" error in netdata-uninstaller (#12828, @maneamarius)
- Add support for installing static builds on systems without usable internet connections (#12809, @Ferroin)
- Add --repositories-only option to kickstart (#12806, @maneamarius)
- Rename --install option for kickstart.sh (#12798, @maneamarius)
- Fix to avoid recompiling protobuf all the time (#12790, @ktsaou)
- Fix non-interpreted new lines when printing deferred errors in netdata-installer (#12786, @ilyam8)
- Fix a typo in the warning() function in netdata-installer (#12781, @ilyam8)
- Fix checking of environment file in netdata-updater (#12768, @Ferroin)
- Add a missing function and Alma and Rocky distros as CentOS compatibility distro to netdata-updater (#12757, @MarianSavchuk)
- Improve the usage message in netdata-installer (#12755, @petecooper)
- Make atomics a hard-dependency (#12730, @vkalintiris)
- Add --install-version flag for installing specific Netdata version to kickstart (#12729, @maneamarius)
- Correctly propagate errors and warnings up to the kickstart script from scripts it calls (#12686, @Ferroin)
- Fix not-respecting of NETDATA_LISTENER_PORT in docker healthcheck (#12676, @ilyam8)
- Add options to kickstart for explicitly passing options to installer code (#12658, @Ferroin)
- Improve handling of release channel selection in kickstart (#12635, @Ferroin)
- Treat auto-updates as a tristate internally in the kickstart script (#12634, @Ferroin)
- Include proper package dependency (#12518, @atriwidada)
- Fix appending logs to the old log file after logrotate on Debian (#9377, @olivluca)
Other Notable Changes
Improvements
⚙️ Greasing the gears to smoothen your experience with Netdata.
- Add hostname to mirrored hosts int the /api/v1/info endpoint (#13030, @ktsaou)
- Optimize query engine queries (#12988, @ktsaou)
- Optimize query engine and cleanup (#12978, @ktsaou)
- Improve the web server work distribution across worker threads (#12975, @ktsaou)
- Check link local address before querying cloud instance metadata (#12973, @ilyam8)
- Speed up query engine by refactoring rrdeng_load_metric_next() (#12966, @ktsaou)
- Optimize the dimensions option store to the metadata database (#12952, @stelfrag)
- Add detailed dbengine stats (#12948, @ktsaou)
- Stream Metric Correlation version to parent and advertise Metric Correlation status to the Cloud (#12940, @MrZammler)
- Move directories, logs, and environment variables configuration options to separate sections (#12935, @ilyam8)
- Adjust the dimension liveness status check (#12933, @stelfrag)
- Make sqlite PRAGMAs user configurable (#12917, @ktsaou)
- Add worker jobs for cgroup-rename, cgroup-network and cgroup-first-time (#12910, @ktsaou)
- Return stable or nightly based on version if the file check fails (#12894, @stelfrag)
- Take into account the in queue wait time when executing a data query (#12885, @stelfrag)
- Add fixes and improvements to workers library (#12863, @ktsaou)
- Pause alert pushes to the cloud (#12852, @MrZammler)
- Allow to use the new MQTT 5 implementation (#12838, @underhood)
- Set a page wait timeout and retry count (#12836, @stelfrag)
- Allow external plugins to create chart labels (#12834, @ilyam8)
- Reduce the number of messages written in the error log due to out of bound timestamps (#12829, @stelfrag)
- Cleanup the node instance table on startup (#12825, @stelfrag)
- Accept a data query timeout parameter from the cloud (#12823, @stelfrag)
- Write the entire request with parameters in the access.log file (#12815, @stelfrag)
- Add a parameter for how many worker threads the libuv library needs to pre-initialize (#12814, @stelfrag)
- Optimize linking of foreach alarms to dimensions (#12813, @vkalintiris)
- Add a hyphen to the list of available characters for chart names (#12812, @ilyam8)
- Speed up queries by providing optimization in the main loop (#12811, @ktsaou)
- Add workers utilization charts for Netdata components (#12807, @ktsaou)
- Fill missing removed events after a crash (#12803 , @MrZammler)
- Speed up buffer increases (minimize reallocs) (#12792, @ktsaou)
- Speed up reading big proc files (#12791, @ktsaou)
- Make dbengine page cache undumpable and dedupuble (#12765, @ilyam8)
- Speed up execution of external programs (#12759, @ktsaou)
- Remove per chart configuration (#12728, @vkalintiris)
- Check for chart obsoletion on children re-connections (#12707, @MrZammler)
- Add a 2 minute timeout to stream receiver socket (#12673, @MrZammler)
- Improve Agent cloud chart synchronization (#12655, @stelfrag)
- Add the ability to perform a data query using an offline node id (#12650, @stelfrag)
- Implement ks_2samp test for Metric Correlations (#12582, @MrZammler)
- Reduce alert events sent to the cloud (#12544, @MrZammler)
- Store alert log entries even if alert it is repeating (#12226, @MrZammler)
- Improve storage number unpacking by using a lookup table (#11048, @vkalintiris)
Bug fixes
🐞 Increasing Netdata's reliability one bug fix at a time.
- Fix locking access to chart labels (#13064, @stelfrag)
- Fix coverity 378625 (#13055, @MrZammler)
- Fix dictionary crash walkthrough empty (#13051, @ktsaou)
- Fix the retry count and netdata_exit check when running a sqlite3_step command (#13040, @stelfrag)
- Fix sending first time seen dimensions with zero timestamp to the Cloud (#13035, @stelfrag)
- Fix gap filling on dbengine gaps (#13027, @ktsaou)
- Fix coverity issue 378598 (#13022, @MrZammler)
- Fix coverity issue 378617,378615 (#13021, @stelfrag)
- Fix a dimension 100% anomaly rate despite no change in the metric value (#13005, @vkalintiris)
- Fix compilation warnings (#12993, @vlvkobal)
- Fix crash because of corrupted label message from streaming (#12992, @MrZammler)
- Fix nanosleep on platforms other than Linux (#12991, @vlvkobal)
- Fix disabling a streaming destination because of denied access (#12971, @MrZammler)
- Fix "unused variable" compilation warning (#12969, @kklionz)
- Fix virtualization detection on FreeBSD (#12964, @ilyam8)
- Fix buffer overflow when logging "command_to_be_logged" in analytics (#12947, @MrZammler)
- Fix "global statistics" section in netdata.conf (#12916, @ilyam8)
- Fix virtualization detection when systemd-detect-virt is not available (#12911, @ilyam8)
- Fix the log entry for incoming cloud start streaming commands (#12908, @stelfrag)
- Fix release channel in the node info message (#12905, @stelfrag)
- Fix alarms count in /api/v1/alarm_count (#12896, @MrZammler)
- Fix compilation warnings in FreeBSD (#12887, @vlvkobal)
- Fix multihost queries alignment (#12870, @stelfrag)
- Fix negative worker jobs busy time (#12867, @ktsaou)
- Fix reported by coverity issues related to memory and structure dereference (#12846, @stelfrag)
- Fix memory leaks and mismatches of the use of the z functions for allocations (#12841, @ktsaou)
- Fix using obsolete charts/dims in prediction thread (#12833, @vkalintiris)
- Fix not skipping ACLK dimension update when dimension is freed (#12777, @stelfrag)
- Fix coverity warning about not checking return value in receiver setsockopt (#12772, @MrZammler)
- Fix disk size calculation on macOS (#12764, @ilyam8)
- Fix "implicit declaration of function" compilation warning (#12756, @ilyam8)
- Fix Valgrind errors (#12619, @vlvkobal)
- Fix redirecting alert emails for a child to the parent (#12609, @MrZammler)
Code organization
🏋️ Changes to keep our code base in good shape.
- Update default value for "host anomaly rate threshold" (#13075, @shyamvalsan)
- Initialize chart label key parameter correctly (#13061, @stelfrag)
- Add the ability to merge dictionary items (#13054, @ktsaou)
- Dictionary improvements (#13052, @ktsaou)
- Coverity fixes about statsd; removal of strsame (#13049, @ktsaou)
- Replace
historywith relevantdbengineparams (#13041, @andrewm4894) - Schedule retention message calculation to a worker thread (#13039, @stelfrag)
- Check return value and log an error on failure (#13037, @stelfrag)
- Add additional metadata to the data response (#13036, @stelfrag)
- Dictionary with JudyHS and double linked list (#13032, @ktsaou)
- Initialize a pointer and add a check for it (#13023, @vlvkobal)
- Autodetect coverity install path to increase robustness (#12995, @maneamarius)
- Don't expose the chart definition to streaming if there is no metadata change (#12990, @stelfrag)
- Make heartbeat a static chart (#12986, @MrZammler)
- Return rc->last_update from alarms_values api (#12968, @MrZammler)
- Suppress warning when freeing a NULL pointer in onewayalloc_freez (#12955, @stelfrag)
- Trigger queue removed alerts on health log exchange with cloud (#12954, @MrZammler)
- Defer the dimension payload check to the ACLK sync thread (#12951, @stelfrag)
- Reduce timeout to 1 second for getting cloud instance info (#12941, @MrZammler)
- Add links to SQLite init options in the src code (#12920, @ilyam8)
- Remove "enable new cgroups detected at run time" config option (#12906, @ilyam8)
- Log an error when re-registering an already registered job (#12903, @ilyam8)
- Use correct identifier when registering the main thread "chart" worker job (#12902, @ilyam8)
- Change duplicate health template message logging level to 'info' (#12873, @ilyam8)
- Initialize the metadata database when performing dbengine stress test (#12861, @stelfrag)
- Add a SQLite database checkpoint command (#12859, @stelfrag)
- Broadcast completion before unlocking condition variable's mutex (#12822, @vkalintiris)
- Switch to mallocz() in onewayallocator (#12810, @ktsaou)
- Configurable storage engine for Netdata Agents: step 2 (#12808, @aberaud)
- Move kickstart argument parsing code to a function. (#12805, @Ferroin)
- Remove python.d/* announced in v1.34.0 deprecation notice (#12796, @ilyam8)
- Don't use MADV_DONTDUMP on non-linux builds (#12795, @vkalintiris)
- One way allocator to double the speed of parallel context queries (#12787, @ktsaou)
- Trace rwlocks of netdata (#12785, @ktsaou)
- Configurable storage engine for Netdata Agents: step 1 (#12776, @aberaud)
- Some config updates for ML (#12771, @andrewm4894)
- Remove node.d.plugin and relevant files (#12769, @surajnpn)
- Use aclk_parse_otp_error on /env error (#12767, @underhood)
- Remove "search for cgroups under PATH" conf option to fix memory leak (#12752, @ilyam8)
- Remove "enable cgroup X" config option on cgroup deletion (#12746, @ilyam8)
- Remove undocumented feature reading cgroups-names.sh when renaming cgroups (#12745, @ilyam8)
- Reduce logging in rrdset (#12739, @ilyam8)
- Avoid clearing already unset flags. (#12727, @vkalintiris)
- Remove commented code (#12726, @vkalintiris)
- Remove unused
--auto-updateoption when using static/build install method (#12725, @ilyam8) - Allocate buffer memory for uv_write and release in the callback function (#12688, @stelfrag)
- Implements new capability fields in aclk_schemas (#12602, @underhood)
- Cleanup Challenge Response Code (#11730, @underhood)
Deprecation notice
The following items will be removed in our next minor release (v1.36.0):
Patch releases (if any) will not be affected.
| Component | Type | Will be replaced by |
|---|---|---|
| python.d/chrony | collector | go.d/chrony |
| python.d/ovpn_status_log | collector | go.d/openvpn_status_log |
All the deprecated components will be moved to the netdata/community repository.
Deprecated in this release
In accordance with our previous deprecation notice, the following items have been removed in this release:
| Component | Type | Replaced by |
|---|---|---|
| node.d | plugin | - |
| node.d/snmp | collector | go.d/snmp |
| python.d/apache | collector | go.d/apache |
| python.d/couchdb | collector | go.d/couchdb |
| python.d/dns_query_time | collector | go.d/dnsquery |
| python.d/dnsdist | collector | go.d/dnsdist |
| python.d/elasticsearch | collector | go.d/elasticsearch |
| python.d/energid | collector | go.d/energid |
| python.d/freeradius | collector | go.d/freeradius |
| python.d/httpcheck | collector | go.d/httpcheck |
| python.d/isc_dhcpd | collector | go.d/isc_dhcpd |
| python.d/mysql | collector | go.d/mysql |
| python.d/nginx | collector | go.d/nginx |
| python.d/phpfpm | collector | go.d/phpfpm |
| python.d/portcheck | collector | go.d/portcheck |
| python.d/powerdns | collector | go.d/powerdns |
| python.d/redis | collector | go.d/redis |
| python.d/web_log | collector | go.d/weblog |
Platform Support Changes
This release adds official support for the following platforms:
- RHEL 9.x, Alma Linux 9.x, and other compatible RHEL 9.x derived platforms
- Alpine Linux 3.16
This release removes official support for the following platforms:
- Fedora 34 (support ended due to upstream EOL).
- Alpine Linux 3.12 (support ended due to upstream EOL).
This release includes the following additional platform support changes.
- We’ve switched from Alpine 3.15 to Alpine 3.16 as the base for our Docker images and static builds. This should not
require any action on the part of users, and simply represents a version bump to the tooling included in our Docker
images and static builds. - We’ve switched from Rocky Linux to Alma Linux as our build and test platform for RHEL compatible systems. This will
enable us to provide better long-term support for such platforms, as well as opening the possibility of better support
for non-x86 systems.
Netdata Agent Release Meetup
Join the Netdata team on the 9th of June at 5pm UTC for the Netdata Agent Release Meetup, which will be held on
the Netdata Discord.
Together we’ll cover:
- Release Highlights
- Acknowledgements
- Q&A with the community
RSVP now - we look forward to
meeting you.
Support options
As we grow, we stay committed to providing the best support ever seen from an open-source solution. Should you encounter
an issue with any of the changes made in this release or any feature in the Netdata Agent, feel free to contact us
through one of the following channels:
-
Netdata Learn: Find documentation, guides, and reference material for monitoring and
troubleshooting your systems with Netdata. -
GitHub Issues: Make use of the Netdata repository to report bugs or open
a new feature request. -
GitHub Discussions: Join the conversation around the Netdata
development process and be a part of it. -
Community Forums: Visit the Community Forums and contribute to the collaborative
knowledge base. -
Discord: Jump into the Netdata Discord and hangout with like-minded sysadmins,
DevOps, SREs and other troubleshooters. More than 1100 engineers are already using it!
Published by Ferroin almost 3 years ago
Release v1.32.0
The newest version of Netdata, v.1.32.0, propels us toward the end of the year, and the Netdata community is positioned to grow stronger than ever in 2022. Before we get into specifics of the new release, it's worth reflecting on that growth.
Netdata open-source Agent growth
The open-source Netdata Agent, the best OSS node monitoring and troubleshooting ever, currently has:
- 1,000,000 unique Netdata nodes live!
- 330,000 engineers using the agent per month!
- Our open-source community growing at an amazing rate, with 3,000 new nodes and 8,000 users per day!
- 250,000 Docker pulls per day with 360 million total, according to DockerHub!
Netdata Cloud growth
The Netdata Cloud, our infrastructure-level, distributed, real-time monitoring and troubleshooting orchestrator, is also showing similar growth, with:
- 35,000 live Netdata nodes!
- 90,000 engineers signed up with 200 new sign-ups every day!
- 180 new spaces created every day!
We are not just pleased with this amazing adoption rate, we are inspired by it. It is you users who give us the energy and confidence to move forward into a new era of high-fidelity, real-time monitoring and troubleshooting, made accessible to everyone!
Thank you for the inspiration! You rock!
Community News
As many of you know, even though we are not endorsed by CNCF, Netdata is the fourth most starred project in the CNCF landscape. We want to thank you for this expression of your appreciation. If you love Netdata and haven't yet, consider giving us a Github star.
Additionally, we invite you to join us on our new Discord server to continue our growth and trajectory, but also to join in on fun and informative live conversations with our wonderful community.
v1.32.0 at a glance
The following offers a high-level overview of some of the key changes made in this release, with more detailed description available in subsequent sections.
New Cloud backend and Agent communication protocol
This Agent release supports our new Cloud backend. From here, we will be offering much faster and simpler communication, reliable alerts and exchange of metadata, and first-time support for the parent-child relationship of Netdata agents. This is the first Agent release that allows Netdata Cloud to use the Netdata Agent as a distributed time-series database that supports replication and query routing, for every metric!
eBPF latency monitoring, container monitoring, and more
We use eBPF to monitor all running processes, without the cooperation of the processes and without sniffing data traffic. This new release includes 13 new eBPF monitoring features, including I/O latency, BTRFS, EXT4, NFS, XFS and ZFS latencies, IRQs latencies, extended swap monitoring, and more.
Machine learning (ML) powered anomaly detection
This release links Netdata Agent with dlib, the popular C++ machine learning algorithms library, which we use to automatically detect anomalies out-of-the-box, at the edge! Once enabled, Netdata trains an ML model for every metric, which is then used to detect outliers in real-time. The resulting "anomaly bit" (where 0=normal, 1=anomalous) associated with each database entry is stored alongside the raw metric value with zero additional storage overhead! This feature is still in development, so it is disabled by default. If you would like to test it and provide feedback, you can enable the feature using the instructions provided in the Detailed release highlights section.
New timezone selector and time controls in the user interface
We implemented a new timezone picker and time controls to enhance administrative abilities in the dashboard.
Docker image POWER8+ support
Netdata Docker images now support recent IBM Power Systems, Raptor Talos II, and more.
And more...
Four new collectors, 112 total improvements, 95 bug fixes, 49 documentation updates, and 57 packaging and installation changes!
Detailed release highlights
New Cloud backend and Agent communication protocol
It's no secret that the best of Netdata Cloud is yet to come. After several months of developing, testing, and benchmarking a new architectural system, we have steadied ourselves for that growth. These changes should offer notable and immediate improvements in reliability and stability, but more importantly, they allow us to quickly and efficiently develop new features and enhanced functionality. Here's what you can look for on the short-term horizon, thanks to our new architecture:
- Greater capacity: The new architecture will change the communication protocol between the Agent and the Cloud to be incremental, improving our agent-handling capacity by ensuring that the Cloud uses measurably less bandwidth.
- Parent/child relationships: The new architecture will allow, for the first time, the recognition of parent child relationships in the Cloud. These changes will enable you to change storage configuration on parents, limit sent metrics, and reduce data frequency to achieve a longer data retention for your nodes. Atop of this, we will continue to develop the ability for you to have complex setups to scale your monitoring with parents as proxies. Ultimately, this will enable Netdata to operate as a headless connector with the lowest footprint possible on your production nodes.
- Alerts: The new architecture will host a multitude of improvements on our alerts presentation over the coming months, allowing for enhanced reliability, alert management, alert logs to be collected in the Cloud, and more.
If you would like to be among the first to test this new architecture and provide feedback, first make sure that you have installed the latest Netdata version following our guide. Then, follow our instructions for enabling the new architecture.
eBPF container monitoring
We did a lot of work to enhance our eBPF container monitoring this release. First, we start with the development of full eBPF support for cgroups. As a refresher on just how important this update is: cgroups together with Namespaces are the building blocks for containers, which is the dominant way of distributing monitoring applications. We use cgroups to control how much of a given key resource (CPU, memory, network, and disk I/O) can be accessed or used by a process or set of processes. Our eBPF collector now creates charts for each cgroup, which enables us to understand how a specific cgroup interacts with the Linux kernel! 🤓
This enhances our already extensive monitoring by including cgroups for mem, process, network, file access, and more.
eBPF latency monitoring
By enabling eBPF monitoring on all systems that support it, Netdata has already been established as a world-leading distributor of eBPF! We use eBPF to monitor all running processes, without the cooperation of the processes, by tracking any way the application interfaces with the system. And in this release, we continue our commitment to further improve eBPF by tracking latencies by disks, IRQs, etc.
Our new eBPF latency features include:
- A new set of Disk I/O latency charts, which monitor the time that it takes for an I/O request to complete. As many of you may know, this is the most important metric for storage performance!
- Latency IRQs monitoring to help anyone with time spent servicing interrupts (hard or soft).
- A new Filesystem submenu that adds latency monitoring for different filesystems: BTRFS, Ext4, NFS, XFS and ZFS. The latency monitoring was brought for the most common functions, like latency for each open request and latency for each sync request.
eBPF is a very strong addition to our monitoring tools, and we are committed to provide the best experience with monitoring with eBPF from a distance without disrupting the data flow!
Other eBPF enhancements
But we didn't stop there with eBPF in v1.32.0. We also provided the following updates:
- We moved VFS to a Filesystem menu to simplify the visualization of events realized by filesystems. This allows you to monitor actions of filesystems and their latency.
- Until now, Netdata had metrics that demonstrated the amount of swap usage. eBPF.plugin now extends the swap monitoring to show how a specific application group/cgroup is performing action on SWAP.
- We have improved process management monitoring by adding monitoring to shared memory and using tracepoints to monitor process creation and exit with more accuracy.
- Netdata also brings monitoring for OOM Kill events for each apps groups defined on host.
If you share our interest in eBPF monitoring, or have questions or requests, feel free to drop by our Community forum to start a discussion with us.
Machine learning (ML) powered anomaly detection
Machine learning (ML) is undeniably a wave of the future in monitoring and troubleshooting. The Netdata community is riding that wave forward together, ahead of everyone else. Netdata v.1.32.0 introduces some foundational capabilities for ML-driven anomaly detection in the agent. We have integrated the popular dlib c++ ml library to power unsupervised anomaly detection out-of-the-box.
While this functionality is still under development and subject to change, we want to develop this with you, as a team. The functionality is disabled by default while we dogfood the feature internally and build additional ML-leveraging features into Netdata Cloud. But you can go to the new [ml] section in netdata.conf and set enabled=yes to turn on anomaly detection. After restarting Netdata, you should see the Anomaly Detection menu with charts highlighting the overall number and percent of anomalous metrics on your node. This can be a very useful single number summary of the state of your node.
Share your feedback by emailing us at [email protected] or just come hang out in the 🤖-ml-powered-monitoring channel of our discord, where we discuss all things ML and more!
And then, be on the lookout for some bigger announcements and launches relating to ML over the next couple of months.
New timezone selector and time controls in the user interface
Collaborating in a remote world across regions can be difficult, so we wanted to make it easier for you to sync with your administrative teams and your system information. Our new timezone selector allows you to select a timezone to accommodate collaboration needs within your teams and infrastructure. Additionally, we have added the following time controls to allow you to distinguish if the content you are looking at is live or historical and to refresh the content of the page when the tabs are in the background:
- Play: When this option is selected, the content of the page will be automatically refreshed while this is in the foreground.
- Pause: When this option is selected, the content of the page will not refresh due to a manual request to pause it or, for example, when you are investigating data on a chart (cursor is on top of a chart)
- Force Play: When this option is selected, the content of the page will be automatically refreshed even if this is in the background.
Docker image POWER8+ support
And on top of all of that, we have added 64-bit little-endian POWER8+ support to our official Docker images, allowing the use of Netdata Docker images on recent IBM Power Systems, Raptor Talos II, and similar POWER based hardware, extending the list of what is currently supported for our Docker images, which includes:
- 32 and 64 bit x86
- ARMv7
- AArch64
Acknowledgments
- @nabijaczleweli for fixing writing updater log under root.
- @MikaelUrankar for fixing calculation of sysctl mib size in freebsd plugin.
- @filip-plata for adding additional metrics to python.d/postgres collector.
- @eltociear for fixing typos.
- @gotjoshua for adding a link to python.d/httpcheck.conf.
- @wangpei-nice for fixing ebpf.plugin segfault when ebpf_load_program returns null pointer.
- @zanechua for adding Microsoft Teams to supported notification endpoints.
- @diizzyy for adding support for Intel 2.5G and Synopsys DesignWare nic driver in freebsd plugin.
- @Saruspete for fixing handling of adding slabs after discovery in slabinfo plugin.
- @mjtice for adding autovacuum and tx wraparound charts to python.d/postgres.
- @charoleizer for adding PostgreSQL version to requirements section.
- @danmichaelo for fixing a typo in exporting docs.
- @oldgiova for adding capsh check before issuing setcap cap_perfmon.
- @oldgiova for adding Travis ctrl file for checking if changes happened.
- @0x3333 for fixing an inconsistent status check in charts.d/apcupsd.
- @etienne-napoleone for adding terra related binaries to blockchains apps plugin group.
- @anayrat for fixing postgres replication_slot chart on standby.
- @vpiserchia for fixing handling of null values returned by _cat/indices API in python.d/elasticsearch.
- @elelayan for fixing zpool state parsing in proc/zfs.
- @steffenweber for adding missing privilege to fix MySQL slave reporting.
- @unhandled-exception for adding sorting of the list of databases in alphabetical order in python.d/postgres.
- @78Star for updating Netdata and its dependencies versions for pfSense.
- @unhandled-exception for fixing crashing of the wal query if wal-file was removed concurrently in python.d/postgres.
- @rupokify for updating jQuery dependency.
- @caleno for fixing a typo in streaming docs.
- @rex4539 for fixing typos.
Dashboard
- Add various updates to dashboard info (#11639, @ilyam8)
- Add timex plugin chart descriptions (#11635, @ilyam8)
- Add proc plugin zfs chart descriptions (#11630, @ilyam8)
- Add proc plugin infiniband chart descriptions (#11628, @ilyam8)
- Add proc plugin pagetypeinfo chart descriptions (#11627, @ilyam8)
- Add proc plugin net_wireless chart descriptions (#11626, @ilyam8)
- Add proc plugin net_rpc_nfs and net_rpc_nfsd chart descriptions (#11625, @ilyam8)
- Add proc plugin power_supply chart descriptions (#11619, @ilyam8)
- Add cgroups plugin systemd services chart descriptions (#11618, @ilyam8)
- Add cgroups plugin chart descriptions (#11607, @ilyam8)
- Add apps plugin chart descriptions (#11601, @ilyam8)
- Add proc plugin vmstat chart descriptions (#11597, @ilyam8)
- Add proc plugin ksm chart descriptions (#11595, @ilyam8)
- Add proc plugin edac chart descriptions (#11589, @ilyam8)
- Add proc plugin stat chart descriptions (#11586, @ilyam8)
- Add proc plugin net_stat_synproxy chart descriptions (#11581, @ilyam8)
- Add proc plugin softirqs chart descriptions (#11577, @ilyam8)
- Add proc plugin net_stat_conntrack chart descriptions (#11576, @ilyam8)
- Add proc plugin uptime chart descriptions (#11569, @ilyam8)
- Add proc plugin net_sockstat and net_sockstat6 chart descriptions (#11567, @ilyam8)
- Add proc plugin net_snmp6 chart descriptions (#11565, @ilyam8)
- Add proc plugin net_sctp_snmp chart descriptions (#11564, @ilyam8)
- Add proc plugin net_snmp chart descriptions (#11557, @ilyam8)
- Add proc plugin net_netstat chart descriptions (#11554, @ilyam8)
- Add proc plugin net_ip_vs_stats chart descriptions (#11546, @ilyam8)
- Add proc plugin net_dev chart descriptions (#11543, @ilyam8)
- Add proc plugin meminfo chart descriptions (#11541, @ilyam8)
- Add proc plugin mdstat chart descriptions (#11537, @ilyam8)
- Add proc plugin interrupts chart descriptions (#11532, @ilyam8)
- Add proc plugin diskstats chart descriptions (#11528, @ilyam8)
- Add proc plugin ipc semaphores chart descriptions (#11523, @ilyam8)
- Remove 'vernemq.queue_messages_in_queues' from dashboard info (#11403, @ilyam8)
- Move MD arrays charts under Disks (#11119, @thiagoftsm)
Collectors
New
- Add Traefik collector (go.d/traefik) (#605, @ilyam8)
- Add HAProxy collector (go.d/haproxy) (#599, @ilyam8)
- Add Mongodb collector (go.d/mongodb) (#598, @georgeok)
- Add Ethereum Node collector (go.d/geth) (#585, @odyslam)
Improvements
- Add AWS to apps_groups.conf (#11826, @ilyam8)
- Show stats for systemd protected mount points (diskspace plugin) (#11767, @vlvkobal)
- Add support for v1.7.0+ (go.d/coredns) (#619, @georgeok)
- Add "/basic_status" job nginx.conf (go.d/nginx) (#612, @ilyam8)
- Add sharding metrics (go.d/mongodb) (#609, @georgeok)
- Add thread operations metrics (go.d/mysql) (#607, @ilyam8)
- Add replica sets metrics (go.d/mongodb) (#604, @georgeok)
- Add databases metrics (go.d/mongodb) (#602, @georgeok)
- Add more OS(OperatingSystem) charts (go.d/wmi) (#593, @ilyam8)
- Add caddy job to prometheus.conf (go.d/prometheus) (#581, @odyslam)
- Add AOF file size metrics (go.d/redis) (#578, @ilyam8)
- Add openethereum/geth jobs to prometheus.con (go.d/prometheus) (#578, @odyslam)
- Update whois/whois-parser packages and add timeout configuration option (go.d/whoisquery) (#576, @ilyam8)
- Disable reporting min/avg/max group uptime by default (apps plugin) (#11609, @ilyam8)
- Add sorting of the list of databases in alphabetical order (python.d/postgres) (#11580, @unhandled-exception)
- Add terra related binaries to blockchains group (apps plugin) (#11437, @etienne-napoleone)
- Add instruction per cycle charts (perf plugin) (#11392, @thiagoftsm)
- Add autovacuum and tx wraparound charts (python.d/postgres) (#11267, @mjtice)
- Add support for Intel 2.5G and Synopsys DesignWare nic driver (freebsd plugin) (#11251, @diizzyy)
- Add web3 and blockchains groups (apps plugin) (#11220, @odyslam)
- Implement merging user/stock configuration files (python.d plugin) (#11217, @ilyam8)
- Rename default job from 'local' to 'anomalies' (python.d/anomalies) (#11178, @andrewm4894)
- Add standby lag and blocking transactions charts (python.d/postgres) (#11169, @filip-plata)
Bug fixes
- Fix renaming for cgroups with dots in the path (cgroups plugin) (#11775, @vlvkobal)
- Fix exiting on SIGPIPE (go.d plugin) (#630, @ilyam8)
- Fix domain syntax validation (go.d/whoisquery) (#629, @ilyam8)
- Fix missing NONE in valid request methods (go.d/squidlog) (#621, @ilyam8)
- Remove wrong "queue_messages_in_queues" chart (go.d/vernemq) (#601, @ilyam8)
- Fix HTTP/socket client initialization order (go.d/phpfpm) (#591, @ilyam8)
- Fix scraping metrics when resources are not discovered (go.d/vsphere) (#589, @ilyam8)
- Fix LTSV log format parsing (go.d/weblog) (#584, @ilyam8)
- Fix expiration date parsing (go.d/whoisquery) (#575, @ilyam8)
- Fix containers name resolution for crio/containerd runtime (cgroups plugin) (#11756, @ilyam8)
- Add sensors to charts.d.conf and add a note on how to enable it (charts.d plugin) (#11715, @ilyam8)
- Fix crashing of the wal query if wal-file was removed concurrently (python.d/postgres) (#11697, @unhandled-exception)
- Fix "lsns: unknown column" logging (cgroups plugin) (#11687, @ilyam8)
- Fix nfsd RPC metrics and remove unused nfsd charts and metrics (proc/nfsd) (#11632, @vlvkobal)
- Fix "proc4ops" chart family (proc/nfsd) (#11623, @ilyam8)
- Fix swap size calculation (cgroups plugin) (#11617, @vlvkobal)
- Fix RSS memory counter for systemd services (cgroups plugin) (#11616, @vlvkobal)
- Fix VBE parsing (python.d/varnish) (#11596, @ilyam8)
- Remove unused synproxy chart (proc/synproxy) (#11582, @vlvkobal)
- Fix zpool state parsing (proc/zfs) (#11545, @elelayan)
- Fix null values returned by '_cat/indices' API (python.d/elasticsearch) (#11501, @vpiserchia)
- Fix replication_slot chart on standby (python.d/postgres) (#11455, @anayrat)
- Fix an inconsistent status check (charts.d/apcupsd) (#11435, @0x3333)
- Fix plugin name (stats.d plugin) (#11400, @vlvkobal)
- Fix plugin names (freebsd and macos plugins) (#11398, @vlvkobal)
- Fix lack of "module" in chart definition (all chart.d modules) (#11390, @ilyam8)
- Fix various python modules charts contexts (python.d/smartd_log, mysql, zscores) (#11310, @ilyam8)
- Fix current operation charts title and context (proc/mdstat) (#11289, @ilyam8)
- Fix handling of adding slabs after discovery (slabinfo plugin) (#11257, @Saruspete)
- Fix calculation of sysctl mib size (freebsd plugin) (#11159, @MikaelUrankar)
eBPF
New
- Add MD flush calls tracking (#11681, @UmanShahzad)
- Add shared memory system calls tracking (#11560, @UmanShahzad)
- Add OOM kills tracking (#11470, @UmanShahzad)
- Add soft IRQ latency tracking (#11445, @UmanShahzad)
- Add hard IRQ latency tracking (#11410, @UmanShahzad)
- Add mount/umount calls tracking (#11358, @thiagoftsm)
- Add btrfs latency monitoring (#11348, @thiagoftsm)
- Add ZFS latency monitoring (#11330, @thiagoftsm)
- Add NFS latency monitoring (#11313, @thiagoftsm)
- Add disk latency monitoring (#11276, @thiagoftsm)
- Add XFS latency monitoring (#11238, @thiagoftsm)
- Add ext4 latency monitoring (#11224, @thiagoftsm)
- Add extended swap monitoring (#11090, @thiagoftsm)
Improvements
- Add (eBPF) to submenu (#11721, @thiagoftsm)
- Process monitoring cleanup and improvements (#11643, @thiagoftsm)
- Add integration with cgroups plugin (socket, shared memory, cachestat) (#11642, @thiagoftsm)
- Add integration with cgroups plugin (process, file descriptor, VFS, directory cache and OOMkill) (#11611, @thiagoftsm)
- Add initial integration with cgroups plugin (swap) (#11573, @thiagoftsm)
- Add integration with cgroups plugin (create shared memory with cgroups) (#11559, @thiagoftsm)
- Update charts descriptions (#11547, @thiagoftsm)
- Convert eBPF submenus to lowercase (#11511, @thiagoftsm)
- Socket monitoring code improvements and update charts descriptions (#11441, @thiagoftsm)
- Move file operation monitoring to a separate thread (#11401, @thiagoftsm)
- Add module names for threads (#11387, @thiagoftsm)
- Move repeating part of latency chart descriptions to the family level (#11363, @thiagoftsm)
- Reduce plugin's memory usage (#11256, @thiagoftsm)
- Assorted improvements and fixes (#11230, @thiagoftsm)
- Move VFS monitoring to a separate threads and add new charts (#11187, @thiagoftsm)
Bug fixes
- Fix command line arguments (#11670, @thiagoftsm)
- Fix hardirq/softirq value init logic (#11471, @UmanShahzad)
- Fix VFS index reference (#11356, @thiagoftsm)
- Fix a case when multiple eBPF plugins are running (#11287, @thiagoftsm)
- Fix applying configuration options (#11253, @thiagoftsm)
- Fix a segfault when ebpf_load_program returns null pointer (#11203, @wangpei-nice)
- Fix a wrong pointer to a function and move parser to main thread (#11152, @thiagoftsm)
Health
Improvements
- Remove pihole_blocked_queries alert (#11829, @Ancairon)
- Improve check for supported -F parameter in sendmail (#11506, @MrZammler)
- Add custom e-mail headers (#11454, @MrZammler)
- Add 'cockroachdb_underreplicated_ranges' alarm (#11360, @ilyam8)
- Disable 'oom_kill' alarm on k8s nodes (#11359, @ilyam8)
- Add geth stock alarms (#11341, @odyslam)
- Remove pythond modules specific last_collected alarms (#11307, @ilyam8)
- Remove CockroachDB deprecated alarms (#11235, @ilyam8)
- Add new email notification template (#11219, @MrZammler)
- Add system clock synchronization state alarm (#11177, @ilyam8)
- Add python.d/go.d jobs last_collected_secs alarms (#11168, @ilyam8)
- Make stocks alarms less sensitive (#11153, @ilyam8)
Bug fixes
- Fix swap_used alarm calculation (#11672, @ilyam8)
- Fix ram level alarms (#11452, @ilyam8)
- Fix 'gearman_workers_queued' alarm (#11361, @ilyam8)
- Fix sending MS Teams notifications to multiple channels (#11355, @ilyam8)
- Fix sendmail 'unrecognized option: F' issue (#11283, @MrZammler)
- Update old logo to new one (#11263, @odyslam)
- Swap class and type attributes in stock alarm configurations (#11240, @MrZammler)
- Fix alarm line 'charts' matching (#11204, @ilyam8)
Documentation
- Updating ansible steps for clarity (#11823, @kickoke)
- Add a note about pkg-config file location for freeipmi (#11831, @vlvkobal)
- Fix broken link in charts.mdx (#11808, @DShreve2)
- Fix typos (#11782, @rex4539)
- Add nightly release version to readme (#11780, @andrewm4894)
- Fix link to new charts (#11773, @DShreve2)
- Fix typos in netdata-security.md (#11772, @jlbriston)
- Update eBPF documentation (Filesystem and HardIRQ) (#11752, @UmanShahzad)
- Add command for new health entity file (#11733, @DShreve2)
- Remove dated contact suggestion (#11732, @DShreve2)
- Add documentation about Filesystem and HardIRQ (#11752, @UmanShahzad)
- Fix a typo in streaming docs (#11747, @caleno)
- Update eBPF documentation (#11741, @thiagoftsm)
- Fix broken link - Charts 2.0 (#11729, @DShreve2)
- Fix broken link - eBPF plugin (#11728, @DShreve2)
- Add Cloud sign-up link (#11714, @DShreve2)
- Update claiming instructions for Docker (#11713, @DShreve2)
- Fix broken links in kickstart.md (#11708, @DShreve2)
- Add missing collectors to the eBPF plugin readme (#11703, @thiagoftsm)
- Fix broken link - Charts 2.0 (#11701, @hugovalente-pm)
- Update Netdata and dependencies versions for pfSense (#11674, @78Star)
- Add a note about new release of charts on the Cloud (#11637, @hugovalente-pm)
- Update optional parameters for upcoming installer (#11604, @DShreve2)
- Add missing privilege to fix MySQL slave reporting (#11574, @steffenweber)
- Fix broken links (#11540, @ilyam8)
- Update london demo to point at london3 (#11533, @andrewm4894)
- Add a note about handling backslashes in health configuration files (#11527, @ilyam8)
- Improve streaming documentation wording (#11510, @siamaktavakoli)
- Fix a typo in claiming docs (#11492, @car12o)
- Remove broken link (#11482, @andrewm4894)
- Add a note on how to find web files directory for custom dashboards (#11461, @ilyam8)
- Update "Install Netdata on Synology" guide (#11449, @ilyam8)
- Update installation documentation (#11442, @hugovalente-pm)
- Update eBPF documentation (#11440, @thiagoftsm)
- Add time controls and timezone selector description (#11433, @hugovalente-pm)
- Fix broken links - Custom dashboards (#11413, @hugovalente-pm)
- Fix broken links - Custom dashboards (#11405, @hugovalente-pm)
- Rename claiming action to connect (#11378, @hugovalente-pm)
- Fix a typo in exporting docs (#11376, @danmichaelo)
- Add PostgreSQL version to requirements section (#11328, @charoleizer)
- Minor fixes (#11320, @UmanShahzad)
- Fix prometheus node CPU alert rule (#11309, @ilyam8)
- Updated get-started.mdx (#11303, @jlbriston)
- Add Legacy/NG ACLK documentation (#11243, @underhood)
- Add links to data privacy page (#11226, @joelhans)
- Add Microsoft Teams to supported notification endpoints (#11205, @zanechua)
- Add a link to python.d/httpcheck.conf (#11182, @gotjoshua)
- Fix broken links (#11175, @joelhans)
- Update news about the latest release (#11165, @joelhans)
Packaging / Installation
- Use pip3 when installing git-semver package (#11817, @maneamarius)
- Add POWER8+ static builds (#11802, @Ferroin)
- Update libbpf to v0.5.1 (#11800, @thiagoftsm)
- Verify checksums of makeself deps (#11791, @vkalintiris)
- Update go.d.plugin version to v0.31.0 (#11789, @ilyam8)
- Add Oracle Linux 8 to CI and package builds (#11776, @Ferroin)
- Fix a typo in installation script (#11766, @ShimonOhayon)
- Update dashboard to v2.20.11 (#11743)
- Minor improvement to CPU number function regarding macOS. (#11746, @iigorkarpov)
- Add log grouping in installer and static build code when running under GitHub Actions. (#11720, @Ferroin)
- Add basic telemetry to the new kickstart script. (#11718, @Ferroin)
- Add eBPF plugin to static binaries (#11709, @thiagoftsm)
- Fix libbpf handling in RPM package builds. (#11702, @Ferroin)
- Don't use api.github.com when checking for latest stable version (#11700, @ilyam8)
- Fix handling of disabling telemetry in static installs. (#11689, @Ferroin)
- Mark g++ for freebsd as NOTREQUIRED (#11678, @MrZammler)
- Optimize static build and update various dependencies. (#11660, @Ferroin)
- Improve installation on systems with limited RAM. (#11658, @Ferroin)
- Add support for local builds to the new kickstart script. (#11654, @Ferroin)
- Explicitly opt out of LTO in RPM builds. (#11644, @Ferroin)
- Add flag to mark containers as created from official images in analytics. (#11606, @Ferroin)
- Add POWER8+ support to our official Docker images. (#11592, @Ferroin)
- Disable eBPF compilation in different platforms (#11566, @thiagoftsm)
- Fix installer flag --use-system-protobuf (#11539, @underhood)
- Re-add EPEL on CentOS 7. (#11525, @Ferroin)
- Use the correct exit status for the updater with static updates. (#11520, @Ferroin)
- Remove
reset_netdata_trace.shfrom netdata.service (#11517, @ilyam8) - Install basic netdata deps by default. (#11508, @Ferroin)
- Fix handling of claiming in kickstart script when running as non-root. (#11507, @Ferroin)
- Use system copy of protobuf in Docker images and static builds. (#11496, @Ferroin)
- Add initial implementation of new kickstart script. (#11493, @Ferroin)
- Add static builds for ARMv7l and ARMv8a (#11490, @Ferroin)
- Add the ability to allow arbitrary options to be passed to make from netdata-installer.sh. (#11479, @Ferroin)
- Embed build architecture in static build archive names. (#11463, @Ferroin)
- Fix edge repository configuration DEB packages. (#11458, @Ferroin)
- Add check for failed protobuf configure or make (#11450, @MrZammler)
- Don’t bail early if we fail to build cloud deps with required cloud. (#11446, @Ferroin)
- Change default to not using LTO for builds. (#11432, @Ferroin)
- Use DebHelper compat level 9 in repoconfig packages to support Ubuntu 16.04 (#11426, @Ferroin)
- Add capsh check before issuing setcap cap_perfmon (#11386, @oldgiova)
- Update handling of builds of bundled dependencies. (#11375, @Ferroin)
- Add support for bundling protobuf as part of the install. (#11374, @Ferroin)
- Properly handle eBPF plugin in RPM packages. (#11362, @Ferroin)
- Add support for claiming existing installs via kickstarter scripts. (#11350, @Ferroin)
- Assorted kickstart install fixes. (#11342, @Ferroin)
- Add aclk-schemas to dist_noinst_DATA (#11338, @underhood)
- Auto-detect PGID in Dockerfile's ENTRYPOINT script (#11274, @odyslam)
- Add code for repository configuration packages. (#11273, @Ferroin)
- Explicitly update libarchive on CentOS 8 when installing dependencies. (#11264, @Ferroin)
- Fix kickstart-static64.sh install script fail when trying to access
.install-typebefore it is created (#11262, @ilyam8) - Add openSUSE 15.3 package builds. (#11259, @Ferroin)
- Fix libjudy installation on CentOS 8. (#11248, @Ferroin)
- Fix
install_typedetection during update (#11199, @ilyam8) - Store info about the installation type for later retrieval. (#11157, @Ferroin)
- Compile/Link with absolute paths for bundled/vendored deps. (#11129, @vkalintiris)
- Fix writing updater log under root (#10901, @nabijaczleweli)
- Add ARM binary package builds to CI. (#10769, @Ferroin)
Other Notable Changes
Improvements
- Clean compilation warnings (#11810, @stelfrag)
- Fix coverity issues (#11809, @stelfrag)
- Add commands to check and fix database corruption (#11828, @stelfrag)
- Use two digits after the decimal point for the anomaly rate. (#11804, @vkalintiris)
- Always queue alerts to aclk_alert (#11806, @MrZammler)
- Add some logging for cloud new architecture to access.log (#11788, @MrZammler)
- Delete from aclk alerts table if ack'ed from cloud one day ago (#11779, @MrZammler)
- Remove feature flag for ACLK new cloud architecture (#11774, @stelfrag)
- Insert alert into aclk_alert directly instead of queuing it (#11769, @MrZammler)
- Store and submit dimension delete messages for new cloud architecture (#11765, @stelfrag)
- Implement cloud initiated disconnect command (#11723, @underhood)
- Announce proto capability and enable if cloud supports (#11476, @underhood)
- Add exit points between env and OTP (#11751, @underhood)
- Improve the ACLK sync process for the new cloud architecture (#11744, @stelfrag)
- Disable C++ warnings from dlib library. (#11738, @vkalintiris)
- Add queue removed alerts to cloud for new architecture (#11704, @MrZammler)
- Add support to stream chart labels on a parent - child setup (#11675, @MrZammler)
- Add snapshot message for cloud new architecture (#11664, @MrZammler)
- Add protobuf to
-W buildinfooutput. (#11634, @Ferroin) - Add new alarm status protocol messages (#11612, @underhood)
- Add local webserver API/v1 call "aclk" (#11588, @underhood)
- Make New Cloud architecture optional for ACLK-NG (#11587, @underhood)
- Enable additional functionality for the new cloud architecture (#11579, @stelfrag)
- Add alert message support for ACLK new architecture (#11552, @MrZammler)
- Add support for Anomaly Detection MVP (#11548, @vkalintiris)
- Add New Cloud Protocol files to CMake (#11536, @underhood)
- Add archive uploads for dist, package build, and static build checks. (#11534, @Ferroin)
- Add node message support for ACLK new architecture (#11514, @stelfrag)
- Clean netdata naming (#11484, @andrewm4894)
- Add aclk/cloud state command to netdatacli (#11462, @underhood)
- Add chart message support for ACLK new architecture (#11447, @stelfrag)
- Add Alert Related API for new protocol (#11424, @underhood)
- Update SQLite version from v3.33.0 to 3.36.0 (#11423, @stelfrag)
- Add SQLite unit tests (#11422, @stelfrag)
- Add NodeInstanceInfo API (#11419, @underhood)
- Use SQLite to store the health log and alert configurations. (#11399, @MrZammler)
- Add ACLK synchronization event loop (#11396, @stelfrag)
- Add HTTP basic authentication to Prometheus remote write and HTTP versions of Graphite, JSON, OpenTSDB (#11394, @vlvkobal)
- Add new Cloud chart related parsers and generators (#11393, @underhood)
- Remove warning when GCC 8.x is used (#11389, @thiagoftsm)
- Add support to allow ACLK-NG to grow MQTT buffer (#11340, @underhood)
- Add support for bundled protobuf (#11335, @underhood)
- Add ACLK-NG cloud request type charts (#11326, @UmanShahzad)
- Add HTTP access log messages for ACLK-NG (#11318, @UmanShahzad)
- Add a log message when the page cache manager sleeps for more than 1 second. (#11314, @vkalintiris)
- Add hop count for children (#11311, @stelfrag)
- Remove access check for install-type file (#11288, @MrZammler)
- Support TLS SNI in ACLK-NG (#11285, @underhood)
- Make ACLK-NG the default if available (#11272, @underhood)
- Add extra posthog attributes (#11237, @MrZammler)
- Add support to ACLK-NG for new Cloud NodeInstance related msgs (#11234, @underhood)
- Add support so ACLK NG and Legacy can coexist (#11225, @underhood)
- Move cleanup of obsolete charts to a separate thread (#11222, @vlvkobal)
- Add check to only report the exit code when anonymous statistics script fails (#11215, @MrZammler)
- Reduce memory needed per dimension (#11212, @stelfrag)
- Improve dbengine intialization to ignore journal files that can not be read (#11210, @stelfrag)
- Use memory mode RAM if memory mode dbengine is specified but not available (#11207, @stelfrag)
- Improve return status check for the execution of anonymous statistics script (#11188, @MrZammler)
- Reuse the SN_EXISTS bit to track anomaly status. (#11154, @vkalintiris)
- Remove deprecated command line options (#11149, @vkalintiris)
- Remove unecessary relative paths when including headers. (#11124, @vkalintiris)
- Add field to provide UTC offset in seconds and edit health config command (#11051, @MrZammler)
Bug fixes
- Set NETDATA_CONTAINER_OS_DETECTION properly (#11827, @MrZammler)
- Fix agent crash when ACLK sync thread is not initialized (#11820, @MrZammler)
- Simple fix for the data API query (#11787, @vlvkobal)
- Use the proper format specifier when logging configuration options. (#11795, @vkalintiris)
- Use correct hop count if host is already in memory (#11785, @stelfrag)
- Fix proc/interrupts parser (#11783, @maximethebault)
- Skip sending hidden dimensions via ACLK (#11770, @stelfrag)
- Fix host hop count reported to the cloud (#11768, @stelfrag)
- Fix log if D_ACLK is used (#11763, @underhood)
- Fix retention message duration when no local metrics are found (#11762, @stelfrag)
- Fix an issue with incomplete payload served when https is enabled (#11754, @MrZammler)
- Fix a type in the popocorn information message (#11745, @underhood)
- Fix /api/v1/info if ml-info is missing (#11739, @MrZammler)
- Fix typo in aclk_query.c (#11737, @eltociear)
- Fix online chart in NG not updated properly (#11734, @underhood)
- Fix coverity CID #373610 (#11719, @MrZammler)
- Fix loading old and custom dashboards (#11710, @rupokify)
- Fix coverity issues 373612 & 373611 (#11684, @MrZammler)
- Fix warnings from -Wformat-truncation=2 (#11676, @MrZammler)
- Fix interval usage and reduce I/O (#11662, @thiagoftsm)
- Fix build issue related to legacy aclk and new arch code (#11655, @MrZammler)
- Fix typo in URL when calling env (#11651, @underhood)
- Fix false poll timeout (#11650, @underhood)
- Fix chart config overflow (#11645, @stelfrag)
- Fix an overflow when unsigned integer subtracted (#11638, @vlvkobal)
- Fix coverity issues 373400-373402 (#11631, @stelfrag)
- Fix proper initialization struct with zeroes (#11621, @MrZammler)
- Fix https client (#11608, @underhood)
- Fix CID 339027 and reverse arguments (#11578, @thiagoftsm)
- Fix resource leak when analytics thread stops (#11575, @MrZammler)
- Fix coverity report issues CID_373247-373251 (#11549, @stelfrag)
- Fix coverity issues for health config (#11535, @MrZammler)
- Fix issue with log messages appearing in the terminal instead of the error.log on startup (#11524, @stelfrag)
- Fix issues in Alarm API (#11491, @underhood)
- Fix list corruption in ACLK sync code and remove fatal (#11444, @stelfrag)
- Fix coverity reported issues 372243 - 372248 (#11429, @stelfrag)
- Fix CID 372233 to CID 372236 (#11411, @underhood)
- Fix bundled protobuf linkage on systems needing -latomic (#11406, @underhood)
- Fix coverity issue 372222 (#11404, @stelfrag)
- Fix typo in analytics.c (#11329, @eltociear)
- Fix coverity errors in ACLK (#11322, @underhood)
- Fix confusing error in ACLK Legacy (#11278, @underhood)
- Fix an issue to send correct aclk implementation used by agent to posthog. (#11247, @MrZammler)
- Fix error on --disable-cloud (#11244, @underhood)
- Fix mqtt_websockets submodule version (#11196, @underhood)
- Fix claiming script exit code when daemon not running and the claim was successful (#11195, @ilyam8)
- Fix loading of class, component and type from health log when sufficient fields are detected. (#11193, @MrZammler)
- Fix issue with mqtt_websockets on FreeBSD (#11172, @underhood)
- Fix typo in aclk.c (#11170, @eltociear)
- Fix mqtt_websockets on MacOS (#11145, @underhood)
Deprecation notice
An upcoming stable release of the Netdata agent will include a maintainability update to our base Docker image.
A small percentage of users will find that all self-compiled packages must be manually rebuilt after the update, even if relocation/SONAME errors are not encountered. --security-opt=seccomp=unconfined can be passed with no default.json, but this introduces security vulnerabilities between the host and malicious code in the container.
Alternatively, users can prepare for the update by upgrading to one of the following:
- runc v1.0.0-rc93
- Docker 19.03.9 or greater AND libseccomp 2.4.2 or greater
While Netdata previously avoided making this update to minimize inconvenience to our users, we are now facing a third-party end-of-life date, and we believe the minimal number of affected users substantiates the need for the change.
Additionally, in a future stable release, we will be removing our legacy agent-to-cloud connection. Most users should see no change in this upgrade, but we will lose SOCKS 5 proxy support for the Netdata Cloud functionality, which will affect a small number of users.
Support options
As we grow, we stay committed to providing the best support ever seen from an open-source solution. Should you encounter an issue with any of the changes made in this release or any feature in the Netdata agent, feel free to contact us by one of the following channels:
- Github: You can use our Github repo to report bugs and submit feature requests
- Community forum: You can visit our community forum for questions and training.
- NEW: Discord: You can jump into our Discord for interactive, synchronous help and discussion. More than 700 engineers are already using it! Join us!
Published by firehol-automation over 6 years ago
New to netdata? Check its demo: https://my-netdata.io
Posted on twitter, facebook, reddit r/linux,
Hi all,
Another great netdata release: netdata v1.10.0 !
This is a birthday release: netdata is now 2 years old !
Many thanks to all the contributors that help building, enhancing and improving a project useful and helpful for thousands of admins, devops and developers around the world! You rock!
- @ktsaou
At a glance
netdata now has a new web server (called static) with a fixed number of threads, providing a lot better performance and finer control of the resources allocated to it.
All dashboard elements (javascript) have been updated to their latest versions - this allows a smoother experience when embedding netdata charts on third party web sites and apps.
IMPORTANT: all users using older netdata are advised to update to this version. This version offers improved stability, security and a huge number of bug fixes, compared to any prior version of netdata.
new plugins
- BTRFS - monitor the allocations of BTRFS filesystems (yes, netdata can now properly detect when btrfs is going out of space)
- BCACHE - monitor the caching block layer that allows building hybrid disks using normal HDDs and SSDs
- Ceph - monitor ceph distributed storage
- nginx plus - monitor the nginx+ web servers
- libreswan - monitor IPSEC tunnels
- Traefik - monitor traefik reverse proxies
- icecast - monitor icecast streaming servers
- ntpd - monitor NTP servers
- httpcheck - monitor any remote web server
- portcheck - monitor any remote TCP port
- spring-boot - monitor java spring boot applications
- dnsdist - monitor dnsdist name servers
- hugepages - monitor the allocation of Linux hugepages
enhanced / improved plugins
- statsd
- web_log
- containers monitoring
- system memory
- diskspace
- network interfaces
- postgres
- rabbitmq
- apps.plugin
- haproxy
- uptime
- ksm
- mdstat
- elasticsearch
- apcupsd
- isc-dhcpd
- fronius
- stiebeleltron
new alarm notifications methods
- alerta
- IRC
And as always, hundreds more enhancements, improvements and bugfixes.
BTRFS monitoring
BTRFS space usage monitoring and related alarms.
netdata is able to detect if any of the space-related components (physical disk allocation, data, metdata and system) of BTRFS is about the become exhausted!
#3150 - thanks to @Ferroin for explaining everything about btrfs...

bcache monitoring
netdata now monitors bcache metrics - they are automatically added to any disk that is found to be a bcache disk.
ceph monitoring
New plugin to monitor ceph, the unified, distributed storage system designed for excellent performance, reliability and scalability (#3166 @lets00).
containers and VMs monitoring
- netdata now monitors
systemd-nspawncontainers. - netdata now renames charts of kubernetes containers.
-
virshis now called with-rto avoid prompting for password #3144 -
cgroup-networkis now a lot more strict, preventing unauthorized privilege escalation #3269 -
cgroup-networknow searches for container processes in sub-cgroups too - this improves the mapping of network interfaces to containers -
cgroup-networknow works even when there are novethinterfaces in the system
monitor ntpd
netdata can now monitor isc-ntpd. @rda0 did a marvelous job decoding NTP Control Message Protocol, collecting ntpd metrics in the most efficient way #3421, #3454 @rda0

btw, netdata also monitors
chronybut the chrony module of netdata is disabled by default, because certain CentOS versions ship a version of chrony that consumes 100% cpu when queried for statistics.
nginx plus web servers monitoring
Added python plugin to monitor the operation of nginx plus servers. The plugin monitors everything about nginx+, except streaming #3312 @l2isbad
libreswan IPSEC tunnels monitoring
netdata now monitors libreswan tunnels - #3204

remote HTTP/HTTPS server monitoring
netdata now has an httpcheck plugin (module of python.d.plugin), that can query remote http/https servers, track the response timings and check that the response body contains certain text #3448 @ccremer .

remote TCP port monitoring
netdata now has portcheck plugin (module of python.d.plugin), that can check any remote TCP port is open #3447 @ccremer

icecast streaming server monitoring
netdata now monitors icecast servers #3511 @l2isbad.
traefik reverse proxy monitoring
netdata now monitors traefik reverse proxies - #3557.
spring-boot monitoring
netdata can now monitor java spring-boot applications @Wing924


dnsdist
netdata now monitors dnsdist name servers - @nobody-nobody #3009
statsd
- statsd dimensions now support the options the external plugin dimensions support (currently the only usable option is
hiddento add the dimension, but make it hidden on the dashboard - a hidden dimension can participate in various calculations, including alarms). - statsd now reports the CPU usage of its threads at the netdata section.
- statsd metrics are logged to access.log the first time they are encountered.
- statsd metrics now accept the special value
zinitto allow them get initialized without altering their values (this is useful if you have rare metrics that you need to initialize when netdata starts). - statsd over TCP is now a lot faster - netdata can process up to 3.5mil statsd metrics / second using just one core. Added options to control the timeouts of TCP statsd connections.
- fixed the title and context of statsd private charts
- statsd private charts can now be hidden from the dashboard #3467
postgres
Several new charts have been added to monitor (#3400 by @anayrat):
- checkpointer charts
- bgwriter charts
- autovacuum charts
- replication delta charts
- WAL archive charts
- WAL charts
- temporary files charts
Also, the postgres plugin now also works when postgres is in recovery mode.
rabbitmq
- added Erlang run queue chart. This is useful in conjunction with the existing Erlang processes chart to get a better overall idea of what's going on in the Erlang VM. @arch273
- added rabbitmq information on the dashboard to complement the charts.
apps.plugin
netdata prior to this version was detecting the user and group of processes by examining the ownership of /proc/PID/stat. Unfortunately it seems that the owneship of files in /proc do not change when the process switches user. So, netdata could not detect the user and group of processes that started as root and then switched to another user.
Now netdata reads /proc/PID/status:
- process ownship information is now accurate
- eliminated the need to read
/proc/PID/statm(all the information of/proc/PID/statmis available in/proc/PID/status) - allowed netdata to read
VmSwap, so a new chart has been added to monitor the swap memory usage per process, user and group.
- fixed issue with unreasonable spikes on processes cpu on FreeBSD (there was a typo) #3245
- fixed issue with errors reported on FreeBSD about pid 0 #3099
The new plugin is 20% more expensive in terms of CPU. We tried hard to optimize it, but this is as good as it can get. Read about it at #3434 and #3436
haproxy
Added charts:
- hrsp_1xx, hrsp_2xx, hrsp_3xx, hrsp_4xx, hrsp_5xx, hrsp_other, hrsp_total for backands and frontends
- qtime, ctime, rtime, ttime metrics for backend servers
- backend servers In UP state
@ktarasz
uptime
netdata now uses /proc/uptime when CLOCK_BOOTTIME does not report the same uptime. In containers CLOCK_BOOTTIME reports the uptime of the host, while /proc/uptime reports the uptime of the container, so now netdata correctly reports the uptime of the container.
mdstat
various fixes to better monitor rebuild time and rate @l2isbad
KSM
- removed
to_scandimension - the savings % reported by netdata was less than the actual - fixed it.
elasticsearch
Added several charts for translog / indices segments statistics and JVM buffer pool utilization, which are often helpful when evaluating an elasticsearch node health #3544 @NeonSludge
memory monitoring
- treat slab memory as cached #3288 @amichelic
- added a new chart for monitoring the memory available for use, before hitting swap

- netdata now monitors Linux hugepages and transparent hugepages

- added hugepages monitoring #3462

diskspace monitoring
- support huge amounts of mountpoints #3258 - netdata was crashing with stack overflow due to recursion - now it is loop, so any number of mount points is supported
network monitoring
- moved tcp passive and active opens to a separate chart, to allow the TCP issues dimensions scale better by default #3238
- updated the information presented on TCP charts to match the latest v4.15 kernel source #3239
APC UPS
netdata now supports monitoring multiple APC UPSes.
ISC DHCPd
netdata now also supports monitoring IPv6 leases - @l2isbad
fronius
- added a new dimension
solar_consumption@ccremer - added alarms @ccremer
stiebeleltron
- added alarms @ccremer
web_log
Added web server response timings histogram #3558 @Wing924 .

python.d.plugin
- python.d.plugin can now start even if
/etc/netdata/python.d.confis missing @l2isbad - python.d.plugin now has an internal run counter @l2isbad
- the unicode decoding of the plugin has been fixed (#3406) @l2isbad
- the plugin now does not validate self-signed certificates @l2isbad
- the plugin can not revive obsolete charts @l2isbad
charts.d.plugin
charts.d.plugin BASH modules can now have custom number of retries in case of data collection failures #3524.
web server
- netdata now has a new internal web server that supports a fixed number of threads - we call it
static web server. This web server allows netdata to work around memory fragmentation (since the treads are fixed, the underlying memory allocators reuse the same memory arenas) and cpu utilization (we can control the number of threads that will be used by netdata). This is the default now. #3248 - now the static threads web server reports the CPU usage of each of its threads.
- the HTTP response headers now include the netdata version
dashboard
-
the print button now respects the URL path netdata is hosted.
-
dygraphs updated to the latest version - this fixes an issue that prevented netdata charts from being interactive under certain conditions
-
added dygraph theme
logscale#3283 -
fontawesome updated to version 5
-
d3 updated to the latest version (this broke c3 charts that require an older version)
-
added d3pie charts
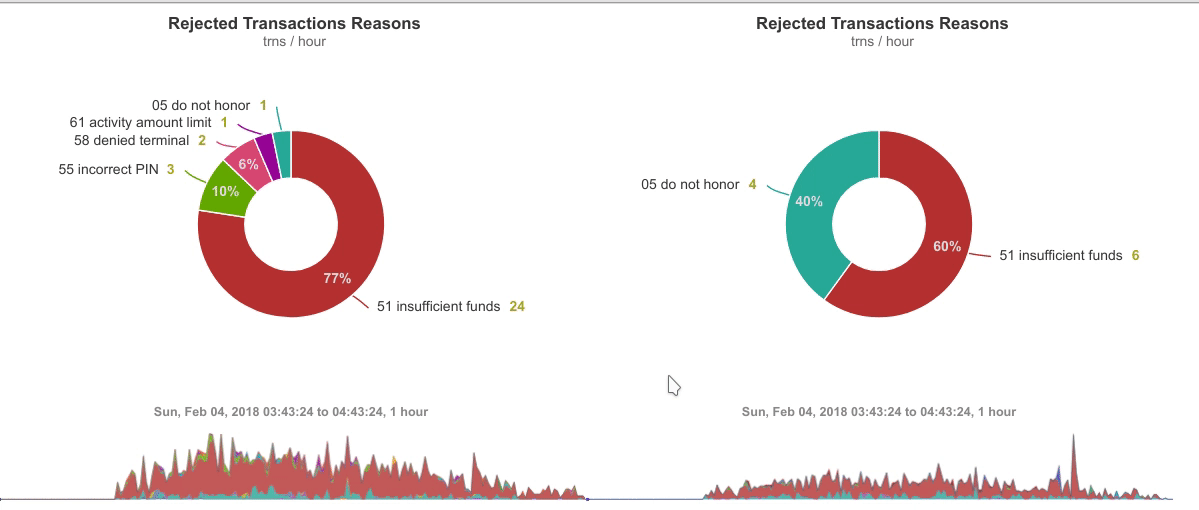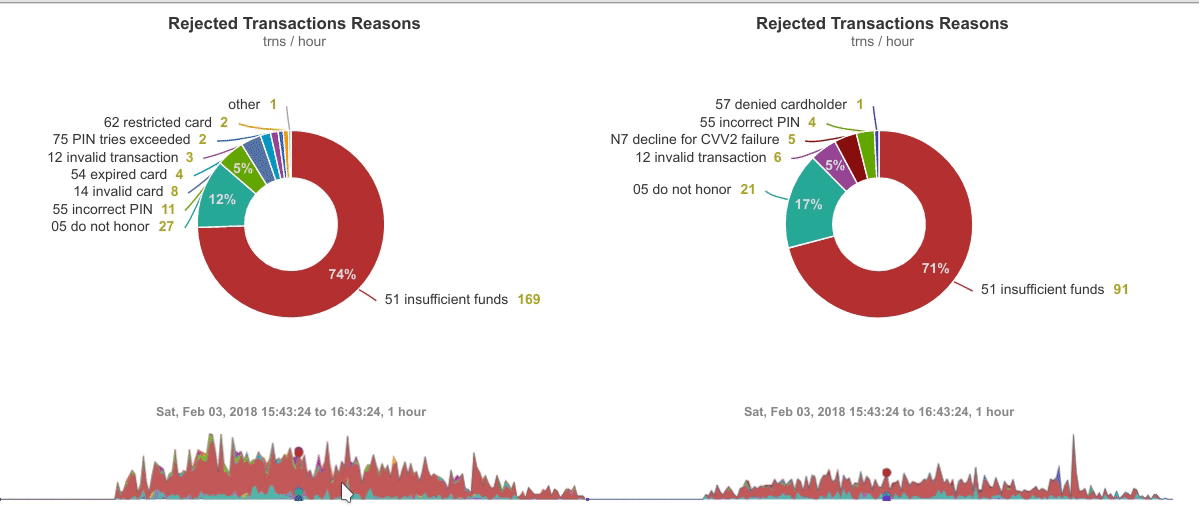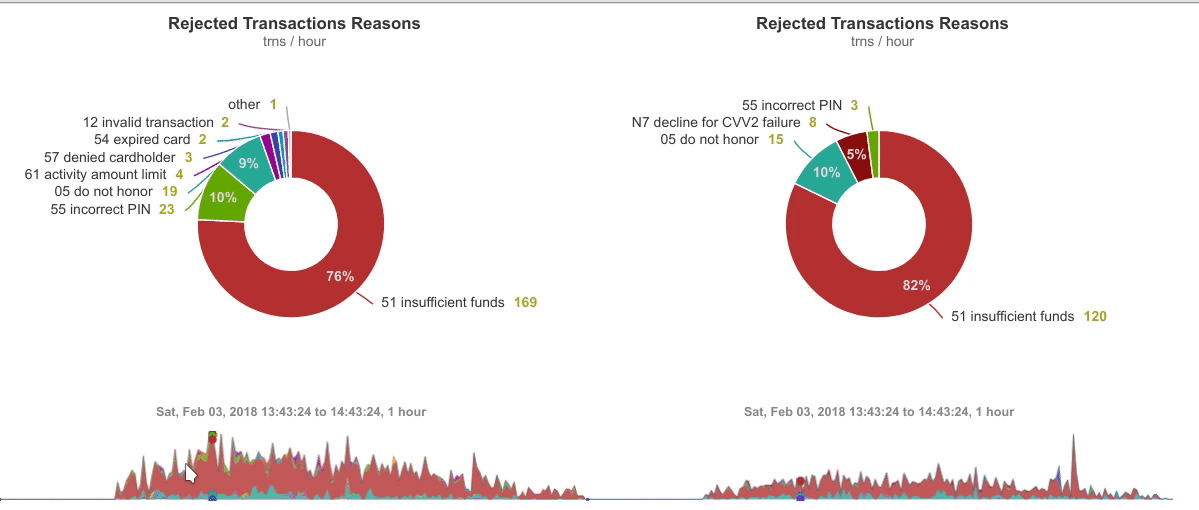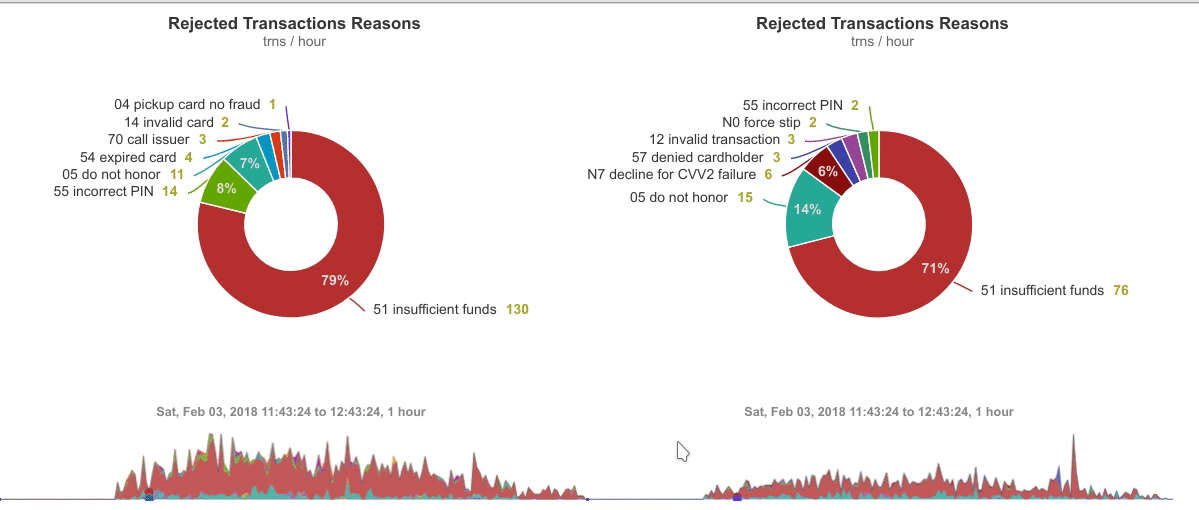
-
custom dashboards can now have alarms for specific roles (all, none, one or more).
-
allow stacked charts to zoom vertically when dimensions are selected

-
netdata now has a global XSS protection #3363
-
netdata now uses intersectionObserver when available #3280 - this improves the scrolling performance of the dashboard.
-
prevent date, time and units from wrapping at the charts legends #3286
-
various units scaling improvements #3285
-
added
data-common-colors="NAME"chart option for custom dashboards #3282. -
added wiki page for creating custom dashboards on Atlassian's Confluence.
-
prevented a double click on the charts' toolbox to select the text of the buttons.
-
fixed the alignment of dashboard icons #3224 @xPaw
-
added a simple js, called refresh-badges.js, to update badges on a custom web page
badges
netdata badges can now be scaled #3474



API
- added
gtimeparameter, for group time. This is used to request from netdata to return values in a different rate (i.e.gtime=60on aX/secdimension, will returnX/min). - fixed a rounding bug in JSON generation #3309
- the
dimensions=parameter now supports simple patterns #3170 and added option valuesmatch-idsandmatch-namesto control which matches are executed for dimensions.
alarms
-
system.swapalarms now send notifications with a 30 seconds delay, to work-around a kernel bug that incorrectly reports all swap as instantly used under containers #3380. -
added alarm to predict the time a mount point will run out of inodes #3566.
-
all system alarms are now ported to FreeBSD too #3337 @arch273
-
added alerta.io notifications @kattunga

-
added available memory alarm
-
removed unsupported html tags from hipchat notifications.
-
pagerduty notifications have been modified to avoid incident duplication #3549.
-
alarm definitions can now use both chart IDs and chart names (prior to this version only chart IDs were allowed).
-
curloptions (eg for disabling SSL certificates verification) foralarm-notify.shcan now be defined inhealth_alarm_notify.conf. -
netdata can now send notifications to IRC channels #3458 @manosf
IRCCloud web client:
Irssi terminal client:
backends
- on netdata masters, allow filtering the hosts that will be sent to backends with
send hosts matching = *pattern. - improved connection error handling and added retries to allow netdata connect to certain backends that failed with
EALREADYorEINPROGRESS. - json backends now receive
host tags(the tags have to be formatted in a json friendly way) #3556. - re-worked the alarm that triggers when backend data are lost, to avoid flip-flops.
prometheus backends
- added URL option
timestamps=yes|noto/api/v1/allmetricsto support prometheus Pushgateway #3533 - added
netdata_infovariable with the version of netdata - renamed
netdata_host_tagstonetdata_host_tags_info(the old exists but is deprecated and will be removed eventually) - when prometheus uses
averagemetrics, netdata remembers the last access time the prometheus collected metrics, on a per host basis.
metrics streaming between netdata
- netdata masters and proxies now expose the version of the netdata collecting the metrics, not their own. So, now a netdata master shows on the dashboard and sends to backends the version of the netdata collecting the metrics #3538.
- added
stream.confoptionmultiple connections = accept | denyto allow or deny multiple connection for the same netdata host. The default remainsaccept, but it is likely to be changed tonoon future versions.
packaging
- added docker hub builds for aarch64/arm64 @justin8
- updated debian containers to use stretch @justin8
- added FreeBSD init file
- various installers fixes and improvements (make sure netdata is started, do not give information about features not supported on each operating system, allow non-root installations without errors, etc.)
- various installer fixes for FreeBSD and MacOS
-
netdata-updaterwas growing thePATHvariable on each of its runs - fixed it. - added
--acceptand--dont-start-itcommand line options tokickstart-static64.sh - netdata can be compiled with
long doublesupport (useful in embedded devices that don't support long double numbers) #3354 - fixed
netdata.specto allow building netdata on older and newer rpm based distros. Also added a script to build a netdata rpm - static netdata installer now tries to find the location of the SSL ca-certificates on a system and properly configured the static
curlprovided with this path. - the netdata updater starts netdata only if it was running
- added alpine dockerfile
other
- added global option
gap when lost iterationsto control the number of iterations that should be lost to show a gap on the charts. - various fixes/improvements related to netdata logs - the main change is that now netdata logs the thread name that logged the message, providing helpful insights about the thread that complained.
- re-worked the exit procedure of netdata to allow it cleanup properly - sometimes netdata was deadlocked during exit, waiting forever - now netdata always exits promptly #3184
- fixed compilation on ancient gcc versions
- netdata was always setting itself to the
idleprocess scheduling priority, even when it was configured to do otherwise. Fixed it #3523
New to netdata? Check its demo: https://my-netdata.io
Overview of netdata v1.9
-
snapshots
We can now save and load dashboard snapshots for any timeframe in any resolution. snapshots allow us to save artifacts, evidence, documentation of incidents, or just the raw data for postmortem analysis. -
highlighted time-frame
We can now highlight a selected time-frame on all dashboard charts. So, to quickly compare charts press ALT or CONTROL and select an area on one chart. The same area will be highlighted on all charts. -
export to PDF
We can now export netdata dashboards to PDF, for any timeframe with any detail. -
access lists (IP filtering)
We can now setup IP filtering atnetdata.conffor all functions of netdata (dashboard access, streaming, registry, badges, etc - no more iptables rules for protecting netdata). -
TCP overflows and connection drops
netdata can now detect TCP listening sockets overflows and connection drops, for any server running on the host (even the ones netdata is not aware of). -
libvirt VMs
netdata now detects libvirt network interfaces and moves them to VM section of the dashboard (it also supports.libvirt-qemunaming of cgroups). -
Units auto-scaling
netdata dashboards can now scale units (KB->MB->GB->TB, etc), on the fly. -
Units conversions
netdata dashboards can now convert units (eg. Celsius to Fahrenheit, seconds to HH:MM:DD, etc), on the fly. -
Multiple Timezones
netdata dashboards can now change timezone on the fly (yes, we can now compare charts with server logs). -
python.d.plugin rewritten
@l2isbad rewrote the whole of it, to add flexibility and support the latest netdata features! The new plugin supports the old python modules. -
better / faster dashboard scrolling
netdata now uses passive event listeners to detect page scrolling. This improved significantly the responsiveness of the dashboard (check your dashboard settings:syncscrolling is the fastest,asyncis closer to the older behavior). -
netdata now monitors couchdb, powerdns, beanstalkd and dnsdist !
-
netdata now detects redis background save failures
-
netdata can now send flock.com and kavenegar.com alarm notifications
and as always... dozens more improvements, enhancements, new features and bug fixes!
netdata dashboard snapshots !
Netdata can now export and import dashboard snapshots.
Snapshots are JSON files containing everything the dashboard needs to be rendered: charts and chart data.
They are exported as JSON files, to your computer. The saved snapshots can be loaded back on any netdata dashboard (even of different host). When importing, not network traffic is generated. The web browser loads the local file and renders an interactive dashboard to examine it.
The current visible timeframe of the dashboard is respected, so first align the dashboard to the timeframe required and the click "Export". The pop-up allows selecting the resolution of the export (its detail).
highlighted time-frame !
Press the ALT or CONTROL key and select a time-frame at a chart. An overlay will appear with the selected time-frame and all the charts will highlight the same region.
The highlighted time-frame:
- Is added to the URL hash, so that reloading the page keeps it
- Is propagated to other netdata servers, via the
my-netdatamenu - Is save in dashboard snapshots (and of course restored when they are loaded back)

Also, netdata charts can now be zoomed vertically (use the SHIFT key, like in zoom, but select the chart vertically):

netdata dashboards to PDF !
netdata dashboards can now be printed to PDF. Just click the 🖨️ icon on the dashboard.
The current visible timeframe of the dashboard is respected, so first align the dashboard to the timeframe required and the click "Print".

netdata now supports API access lists (IP filtering)
netdata can now check the client IPs connecting to it and deny/allow access based on your settings. No more iptables rules to control access to netdata.
All these settings are netdata simple patterns that are checked against the client IP (string matching - not subnet matching). localhost clients (IPv4, IPv6 and unix domain sockets) can be matched with localhost:
Global access control
-
[web].allow connections fromto match the clients' IPs allowed to connect to netdata. This has the same effect with iptables (but implemented at the application level - so clients will get connected, and disconnected immediately if they are not allowed access, without any response from netdata).
Dashboard access control
-
netdata.conf:[web].allow dashboard fromto match the clients' IPs that are allowed to access the dashboard (ie fetch static files and query netdata API). -
netdata.conf:[web].allow badges fromto match the clients' IPs that are allowed to access badges (the dashboard clients are allowed to access badges too, so this setting allows badges to clients that do not have access to the dashboard).
Streaming access control
-
netdata.conf:[web].allow streaming fromto match the the clients' IPs that are allowed to stream to stream metrics. -
stream.conf:[API_KEY].allow fromto match the clients' IPs allowed to push metrics for the given API KEY. -
stream.conf:[MACHINE_GUID].allow fromto match the clients' IPs allowed to push metrics for the specific machine.
netdata will also check the API keys supplied by slaves and proxies connected.
Other access lists
-
netdata.conf:[web].allow netdata.conf fromto limit the clients that can getnetdata.conf- by default netdata allows only private IPs. -
netdata.conf:[registry].allow fromto limit the clients allowed to access the registry (only when this netdata acts as a registry).
netdata detects TCP listening sockets overflowing or dropping connections
Added a new chart: ipv4.tcplistenissues with dimensions ListenOverflows and ListenDrops.
This chart detects if any listening TCP socket on the host, is overflown, or it drops connections. This is system-wide: any listening TCP socket, of any application.
The chart will not be shown if these kernel counters are zero. It will be enabled automatically if it is found non-zero at any point (it is collected via /proc/net/netstat every second). If you need to enable it even if it is zero, edit netdata.conf and set:
[plugin:proc:/proc/net/netstat]
TCP listen issues = yes
Two alarms have been added, one for ListenOverflows and one for ListenDrops that detect if there is any overflow or drop in the last minute (they run every 10 seconds).
slack alarm for overflows:

slack alarm for drops:

and the alarms configuration:
The alarms will automatically be attached when the chart is active.
The overflows dimension and alarm is supported on FreeBSD too.
/proc/net/sockstat and /proc/net/sockstat6
These files provide sockets statistics for all protocols.

netdata also adds 3 new alarms:
- too many tcp orphan sockets
- tcp memory that detects that the tcp stack is under memory pressure or close to giving memory errors
- too many tcp connections (for kernels that do not support dynamic allocation of connections)
Streaming
-
netdata proxies with more than 100 slaves, had a timing issue that caused them to crash randomly on slave reconnects. Parts of the code have been rewritten to get rid of the timing issue.
-
netdata slaves and proxies, now have a protection that ensures they will never use 100% CPU, even if the master is misbehaving.
-
expired orphaned hosts are now removed from the
my-netdatamenu of the dashboard. -
streaming functions can now be monitored via
access.log -
streaming now support IP filtering. So the entire streaming functionality, API keys and MACHINE GUIDs can be associated with one or more IPs or IP patterns.
-
streaming now transfers alarm variables too
python.d.plugin rewritten
@l2isbad did a marvelous job rewriting python.d.plugin. The new plugin:
-
supports option
autodetection_retry: SECONDS. When set to non-zero, the plugin will re-check the module every that many seconds. This solves the problem that netdata did not persist on collecting metrics from applications, if the application is not found running when netdata starts. By default is zero for all modules, so you need to enable it for all the applications you need it. -
got a rewrite of several functions, like logging, module configuration, chart and dimensions management.
-
the new URL service disables by default certificates checks, to allow self-signed certificates to work without configuration.
The new plugin is compatible with custom python modules developed for the previous version.
web_log plugin
-
custom regex now supports parsing hostnames and IPs @l2isbad
-
web_log now parses lines with error 408 (request timeout - these are a special case, since the request has not received by the web server, so the log line is incomplete) @l2isbad
-
now properly parses
resp_lengthwith value-@racciari
couchdb monitoring
CouchDB maintainer @wohali, submitted a couchdb plugin for netdata. The plugin monitors:
- database activity
- http response codes
- server operations
- per DB statistics


redis monitoring
2 charts have been added to monitor background save health status, bundled with 2 alarms that detect if background save has failed, or background save is slow (warn > 10 mins, crit > 20min). @l2isbad

Other new and enhanced plugins
-
netdata now monitors PowerDNS, @l2isbad
-
netdata now monitors beanstalkd, @l2isbad
-
netdata now monitors dnsdist, @nobody-nobody
-
disks under Linux are renamed using
/dev/disk/by-label. An option has been added at netdata.conf to also allow renaming based on/dev/disk/by-id. -
chronyis now disabled by default, because there have been reports thatchronycenters an infinite loop in CentOS and RHEL. -
tomcatimprovements to support flavors of the tomcat server @Wing924 -
zfson FreeBSD now monitors ZFS TRIM statistics -
disks monitoring charts on FreeBSD got a lot more FreeBSD related dimensions.
-
added CPU frequency charts on FreeBSD (Linux already had them).
-
chart
system.io(the total system Disk I/O) is now calculated by aggregating the reads and writes of all physical disks. The previoussystem.iochart (that is based onpgpginandpgpgoutfrom/proc/vmstat) is now namedsystem.pgpgio. The key difference is that the newsystem.ionow sees ZFS I/O, and it also correctly and accurately sums the real disk bandwidth of RAID arrays. -
chart
system.net(the total system network bandwidth) is now calculated by aggregating the bandwidth of all physical network interfaces and is common for both IPv4 and IPv6. -
tc(QoS) charts now sort the dimensions on the legends, the same waytcreports them. -
postgresversions <= 10 the WAL directory was namedpg_xlog'and from 10 upwards has been renamed topg_wal@facetoe -
mysql(and mariadb) got new charts for galera replication @spinitron -
openvpn_logimprovements @l2isbad -
smartdimprovements @l2isbad -
varnishmodule has been rewritten @l2isbad -
mdstatregex fix @l2isbad -
smartd_logimprovements @l2isbad -
dns_query_timeimprovements @wungad -
isc_dhcpdimprovements @wungad -
freeipmi.plugingot a command line option (can be given at netdata.conf) to ignore certain sensor IDs that are faulty. -
freeradiusimprovements @wungad -
node.d.pluginbugfixes
Plugins protocol enhancements
- netdata now supports multiple plugin directories. The setting is the same in
netdata.conf,plugins directory = "DIRECTORY1" "DIRECTORY2" ..., up to 20 directories. By default netdata sets:
[global]
plugins directory = "/usr/libexec/netdata/plugins.d" "/etc/netdata/custom-plugins.d"
-
netdata now supports alarms variables.
Each plugin can now define host global and chart local variables with static values, that can be used in alarms' expressions. So, hosts and charts can now have any number of static values associated with them (eg. an application server may expose its max connections limit), and these static values can be used to trigger alarms (eg. the current connections, is compared to the max connections variable). The whole setup allows alarm templates to use this feature (eg each netdata can maintain different such variables for each server it monitors).
Alarm variables are propagated to upstream netdata servers.
O/S - distro support
-
added init file for SLC 6.9 and CloudLinux Server release 6.9
-
packages installer was incorrectly detecting all python versions as version 2.
-
a
makeselfbug that prevented the static netdata binaries from being installed onbusyboxsystems, has been fixed. -
openrc startup script (gentoo, alpine) had hardcoded the path to netdata. This affected all static-64bit builds when installed on these distros. Fixed.
-
the static 64bit installer now downloads netdata.conf, much like the git installer does.
-
openrc / gentoo init improvements @candrews
-
enabled support for macOS versions 10.5+ (10.11 was working already) @vlvkobal
-
enabled support for FreeBSD 12 @vlvkobal
-
fixed a crash on macOS hosts with empty disk names.
-
added
Dockerfile.armv7hffor running netdata under docker on ARM v7 machines @justin8
Dashboard improvements
-
hover selection of charts is now faster on all browsers. Perfect on Chrome, Firefox and Opera. Quite usable on Edge.
-
the dashboard is now fixed when a modal is open, preventing scrolling the page.
-
the dashboard now uses fontawesome 5.0.1 for icons.
-
the chart names can now be searched with browser control-F (find in page). netdata lazy loads all charts for it was impossible to search of a chart. Now the charts are searchable. This is important on dashboards with several hundreds of statsd charts, because all these charts appear under the same section.
-
netdata now detects libvirt VM network interfaces and moves them to the VM section of the dashboard. The same functionality already exists for containers.

-
Show the context of each chart. The
contextis used in alarm templates. (hover on the date of the chart)
-
Show the resolution of the chart. (hover on the time of the chart)

-
The dashboard now adds a tooltip at the date of the charts, to show the plugin and its module that collects each chart.
-
The dashboard should now put a lot less CPU pressure on the browser when the page does not have focus.
automatic units scaling
The dashboard does dynamic units scaling, on the fly ! It converts:
- network bandwidth (
kilobits/stomegabits/sorgigabits/s) - input/output bandwidth (
kilobytes/stomegabytes/sorgigabytes/s, similarly forKB/s) - memory sizes (
MBtoKB,GBorTB) - disk sizes (
GBtoMBorTB)
Chart units dynamically adapt based on the value of the selected dimension too:

Custom dashboards can give data-desired-units="UNITS" and netdata will automatically convert the presented values to the desired units. UNITS can be any of the supported one, or auto for auto-scaling based on the values, or original to show the original units maintained by the netdata server.
units conversions
The dashboard now supports units conversions. Currently it converts:
temperatures from Celsius to Fahrenheit

seconds to human readable duration DDd:HH:MM:SS
timezone conversions
netdata can now convert all dates presented to any timezone. Traditionally netdata presented all charts at the timezone of the viewer. This allowed homogeneous central administration of systems that are installed all over the world. However, this was inefficient when we needed to compare the information presented on the dashboard, with the log files of the servers.
So, now netdata can present the charts on any timezone. The netdata server auto-detects the timezone of the server and new dashboard settings have been added to allow this conversion.
If autodetection of the servers timezone fails, the configuration option [global].timezone has been added in netdata.conf to set it. Also, the dashboard itself allows the viewers to configure the timezone (it is saved at browser local storage, so this has to be set just once per viewer).
new dashboard options
To support all the above, the dashboard settings got a new tab, with all the required options:

statsd improvements
-
statsd metrics can now be added to statsd synthetic charts using patterns. No need to add a
dimensionline for each statsd metric to be added. netdata will also extract the wildcarded part of the metric name and use that one for the dimension name. -
dimensions added to statsd synthetic charts, can automatically be renamed using a dictionary. Each synthetic charts application has its own dictionary of name - value pairs, which is used to automatically rename statsd metrics when they are added to synthetic charts.
-
statsd timers and histograms now report zeros when nothing is collected
Badges improvements
-
fixed a bug in netdata badges that was incorrectly matching zero values with the
nullcolor condition. -
added API option
display_absoluteto allow badges use the signed value for color evaluation, but present the absolute value.
Other Alarm and Alarm Notifications Improvements
-
warning emails sent by netdata, are now a little bit more orange (they were a bit green'sh).
-
added flock.com notifications @tvarsis
-
added kavenegar.com support for SMS notifications @vahit
-
fixed a bug in email notifications that was triggering a corrupted MIME match by anti-spam solutions.
-
pushbullet notifications now track the devices, so that per device filtering at pushbullet is possible. Also improved the formatting a bit. @user501254
-
pushover notifications fixes (the priority of warnings was set incorrectly)
-
alarms can now use variables like this
${variable with spaces or +, -, *, / in it}. So, alarms can now use dimension names with any character in them.
Other Improvements
-
access.loghas been refactored to support monitoring all netdata operations -
inodes monitoring is now by default disabled for mount points based on filesystems that do not have a maximum inode threshold (such as
cephfs). -
rabbitmqhas been added toapps_groups.confso thatapps.pluginnow monitors (cpu, memory, disk I/O, sockets, etc) for rabbitmq instances. -
several email and log management apps have been added to
emailandlogstargets ofapps_groups.conf, @Flums -
cephtarget added toapps_groups.confto allow netdata monitor Ceph - the unified, distributed storage system, @k0ste -
refactored several internal data collection plugins to eliminate a few hundreds of index lookups per second.
-
netdata.confsettings that are loaded from disk, but were the same with the default ones, were generated commented when the server was asked to give its config. Now all loaded settings are generated uncommented. -
netdata simple patterns can now extract the the wildcarded part of the string they match (used in statsd synthetic charts)
-
netdata simple patterns can allow escaping spaces by prefixing them with a backslash.
New to netdata? Check its demo: https://my-netdata.io
netdata v1.8.0 released.
This release focuses on metrics streaming improvements and containers monitoring.
As always, this netdata is the fastest and the more stable netdata ever! Update now!
To install or update netdata, click here!
key streaming improvements
bug fix: streaming slaves consuming 100% CPU
netdata, as a slave, was not handling all the error cases properly, resulting in 100% cpu utilization of a single core, under certain conditions. Especially under FreeBSD and macOS slaves, these conditions were always met, so using FreeBSD or macOS as netdata slaves, was completely broken.
bug fix: missing alarm notifications on netdata masters
netdata was incorrectly messing cached alarm state data between the alarms of the mirrored hosts, resulting in alarm notifications not dispatched under certain conditions. This was affecting only netdata masters (ie. netdata servers with more than one host databases, with health monitoring enabled). The alarms were generated and were visible at the dashboards, but the notifications were not always sent.
bug fix: streamed charts with duplicate names
There was a minor issue with charts that were created with name aliases. When these charts were streamed from netdata slaves to netdata masters, they ended up with duplicate chart names (ie instead of type.name they had type.type.name).
key containers monitoring improvements
-
Container network interfaces are now moved to the container section and they are rendered from the container view point (i.e.
sent= what the container sent) - no moreveth*garbage on the dashboard. -
The interfaces also appear as
eth0(or whatever the container sees) and they are inside the container section of the dashboard. netdata maps eachveth*interface to the right container, using plaincgroupsfeatures, so this works for all container managers (docker, lxc, etc). -
Eliminated the nested containers shown under certain versions of
lxc. -
Also, containers and VMs now have summary gauges on the dashboard

key plugins improvements
python.d.plugin now supports HTTP keep-alive
netdata now uses urllib3 (shipped with netdata for both python v2 and v3) for URLService based plugins.
This enables HTTP keep-alive on all connections, which allows netdata to have permanent connections to third party web applications.
Fixed by @l2isbad
compatibility enhancements
- better support for Oracle Linux, by @schindlerd
- better support for Alpine Linux
- various fixes at the build procedure for macOS
-
fpingcan now run as non-root, in static binary netdata packages
netdata generic enhancements
-
netdata can now listen on UNIX domain sockets (
.sockfiles). This allows a local web server and netdata to communicate bypassing the network stack (for netdata setbind to = unix:/path/to/netdata.sock- this option supports multiple arguments, so netdata can listen to multiple unix sockets and tcp sockets, at the same time). -
netdata was assuming that the JSON representation of a chart would at most be 1024 bytes, and it was generating corrupted JSON output when any chart was exceeding that limit. Removed the limitation (ie. now there is no limit).
-
netdata was crashing while starting, if no usable disks were found.
-
systemd
netdata.servicenow allows setting negative netdata OOM score and restarts netdata if it crashes. The newnetdata.serviceis not automatically installed when updating netdata. Either delete/etc/systemd/system/netdata.serviceand then update/re-install netdata, or copy the file by hand. -
minor fixes at the installer, by @vincele
new plugins
- Added Intel CPU temperature charts on FreeBSD and macOS, by @vlvkobal
- Added CPU thermal throttling charts on Linux (useful on physical servers and possibly laptops)
- Added
chronyplugin, by @domschl - Added Stiebel Eltron plugin to collect metrics from heat pumps and hot water installations from Stiebel Eltron ISG @BrainDoctor
improved plugins
-
web_logbugfixes, enhancements and optimizations (includingsquidlogs), by @l2isbad -
web_lognow enables parsing HTTP/2 logs incustom_log_format, by @Funzinator -
redisbugfixes, by @l2isbad -
haproxybugfixes, by @l2isbad -
elasticsearchbugfixes and optimizations, by @l2isbad -
rabbitmqbugfixes and optimizations, by @l2isbad -
mdstatbugfixes, by @JeffHenson -
tomcatimprovements, by @Wing924 -
mysqlimprovements, by @alibo and @l2isbad -
dovecotimprovements -
postgresimprovements, by @facetoe -
cpufreqfixed a bug that preventedaccuratereporting of CPU frequencies.accurateworks with theacpi-cpufreqdriver and calculates the average CPU clock of the CPUs utilizing the accounting per frequency, as reported by the kernel, by @tycho -
cpuidleperformance improvements (faster under load) by @tycho -
fail2banbugfixes, by @l2isbad -
SNMPplugin new uses latestnet-snmpand the corrupted 64 bit counters encountered under certain node.js version is now fixed.
dashboard improvements
-
easypiechartsandgaugescan now render arbitrary ranges and animate clock wise or counter clock wise. -
traditionally netdata was using 1024 bits = 1 kilobit. It is fixed: 1000 bits = 1 kilobit.
-
netdata charts should now work on wordpress pages.
alarms and notifications
-
alarm-notify.shnow supports debug mode, showing the exact commands it runs to send notifications, whenexport NETDATA_ALARM_NOTIFY_DEBUG=1 -
alarm-notify.shnow supports setting the sender email address of the emails it sends. -
emails sent by
alarm-notify.shnow include headers to reduce the possibility of them being scored as spam, by @Ferroin -
network related alarms got new thresholds and improved badges
-
netdata now detects if the system has been suspended and pauses all alarms for 60 seconds on resume, to prevent false alarms (no more false alarms on laptops when they resume).
-
netdata alarms now support filtering based on hostname and O/S (linux, freebsd, macos). This means that netdata masters, can now support alarms for slaves of any O/S (i.e. a Linux netdata master can handle alarms for a FreeBSD slave).
-
netdata slack notifications now show the host sent the alarm. In the image below, the alarm is about
bangalore, and is sent bynetdata-build-server(at the lower left corner):
statsd
- the number of fractional points supported by statsd is now configurable (1 to 7).
- 95th percentile calculation on statsd histograms and timers, was incorrectly averaging the values. It is now fixed.
- statsd metrics with non ASCII text were processed by the statsd server, but were breaking JSON data generated by netdata. Fixed it by replacing all invalid characters.
Published by philwhineray over 7 years ago
New to netdata? Check its demo: https://my-netdata.io
This is release v1.7 of netdata.
netdata is still spreading fast: we are at 320.000 users and 132.000 servers! Almost 100k new users, 52k new installations and 800k docker pulls since the previous release 4 and a half months ago! netdata user base grows at about 1000 new users and 600 new servers per day! Thank you! You are awesome!
The next release (v1.8) will be focused on providing a global health monitoring service, for all netdata users, for free! Read more about it here. We need supporters for this cause. Join us!
highlights of netdata v1.7
-
netdata is now a (very fast) fully featured statsd server and the only one with automatic visualization: push a statsd metric and hit F5 on the netdata dashboard: your metric visualized. It also supports synthetic charts, defined by you, so that you can correlate and visualize your application the way you like it.
-
netdata got new installation options - it is now easier than ever to install netdata - we also distribute a statically linked netdata x86_64 binary, including key dependencies (like
bash,curl, etc) that can run everywhere a Linux kernel runs (CoreOS, CirrOS, etc). -
metrics streaming and replication has been improved significantly. All known issues have been solved and key enhancements have been added. headless collectors and proxies can now send metrics to backends when
data source = as collected. -
backends have got quite a few enhancements, including host tags, metrics filtering at the netdata side and sending of chart and dimension names instread of IDs; prometheus support has been re-written to utilize more prometheus features and provide more flexibility and integration options. IF YOU UPDATE FROM NETDATA 1.6 PLEASE CHECK YOUR DASHBOARDS, SINCE MANY METRICS HAVE CHANGED NAMES.
-
netdata now monitors ZFS (on Linux and FreeBSD), ElasticSearch, RabbitMQ, Go applications (via
expvar), ipfw (on FreeBSD 11), samba, squid logs (withweb_logplugin!). -
netdata dashboard loading times have been improved significantly (hit F5 a few times on a netdata dashboard - it is now amazingly fast), to support dashboards with thousands of charts.
-
netdata alarms now support custom hooks, so you can run whatever you like in parallel with netdata alarms.
-
As usual, this release brings dozens more improvements, enhancements and compatibility fixes.
netdata is now a fully featured statsd server
netdata is now a fully featured statsd server. It can collect statsd formatted metrics, visualize them on its dashboards, stream them to other netdata servers or archive them to backend time-series databases.
netdata statsd is fast. It can collect more than 1.200.000 metrics per second on modern hardware, more than 200Mbps of sustained statsd traffic. netdata statsd is inside netdata. This provides a distributed statsd implementation.
netdata also supports statsd synthetic charts: You can create dedicated sections on the dashboard to render the charts. You can control everything: the main menu, the submenus, the charts, the dimensions on each chart, etc.
Read more about netdata statsd
counters
- Scope: count the events of something (e.g. number of file downloads)
- Format:
name:INTEGER|corname:INTEGER|Corname|c - statsd increments the counter by the
INTEGERnumber supplied (positive, or negative).

gauges
- Scope: report the value of something (e.g. cache memory used by the application server)
- Format:
name:FLOAT|g - statsd remembers the last value supplied, and can increment or decrement the latest value if
FLOATbegins with+or-.

histograms
- Scope: statistics on a size of events (e.g. statistics on the sizes of files downloaded)
- Format:
name:FLOAT|h - statsd maintains a list of all the values supplied and provides statistics on them.

The same chart with sum unselected, to show the detail of the dimensions supported:

meters
This is identical to counter.
- Scope: count the events of something (e.g. number of file downloads)
- Format:
name:INTEGER|morname|mor justname - statsd increments the counter by the
INTEGERnumber supplied (positive, or negative).

sets
- Scope: count the unique occurrences of something (e.g. unique filenames downloaded, or unique users that downloaded files)
- Format:
name:TEXT|s - statsd maintains a unique index of all values supplied, and reports the unique entries in it.

timers
- Scope: statistics on the duration of events (e.g. statistics for the duration of file downloads)
- Format:
name:FLOAT|ms - statsd maintains a list of all the values supplied and provides statistics on them.

The same chart with the sum unselected:

dashboard improvements
There have been significant optimizations to the loading times of the dashboard. The dashboard loads instantly now, even when there are several hundreds of charts in it (hit F5 on the dashboard - it is super fast).
For those who know: we eliminated most browser reflows, by refactoring the way the charts are initialized and splitting initialization in 2 phases. Unfortunately we had to re-shape gauge and easypiecharts, so pay some attention to your custom dashboards after updating.
We now use natural sorting on the dashboard elements (i.e. instead of 1, 10, 2, 3 we get 1, 2, 3, 10).
There have been dozens of performance improvements on the netdata dashboard. Like all the previous releases, this release makes netdata the fastest netdata so far!
new installation methods
- Single line installation on Linux
- Static 64bit packages for Linux
- Improved support for Red Hat Enterprise Linux @racciari,
- Improved support for Amazon Machine Image
- Improved support for Centos @n0coast
- Many more installer/updater improvements @nielsAD, @mfurlend
Streaming
- improved self cleanup of obsolete charts and hosts at a central netdata.
- host tags are now propagated from netdata to netdata while streaming metrics.
- log error when multiple clients are streaming the metrics of the same host.
- dozens more streaming improvements and bugfixes.
Backends
- New prometheus backend, supporting all the features of the others backends netdata supports. The new format changed the names of metrics, so if you use grafana or other tools you will have to update your queries.
- Prometheus and opentsdb now support host tags (advanced ephemeral nodes monitoring)
- Metrics sent to backends with data source
average,sumorvolume(from the netdata database) are now more accurate. - Added
contrib/nc-backend.sh, a script that can act as a fallback backend for graphite, opentsdb and compatibles. - netdata nodes without a database (slaves and proxies) can now send
as collectedmetrics to backends.
New and improved plugins
-
Go apps monitoring via
expvar! @kralewitz - ElasticSearch monitoring ! @l2isbad
- RabbitMQ monitoring ! @l2isbad
- ipfw monitoring under FreeBSD 11 ! @vlvkobal
- ZFS monitoring under FreeBSD (@vlvkobal) and Linux !
- samba monitoring ! @ntlug
-
web_logplugin can now monitor squid logs too ! @l2isbad -
web_logplugin can now monitor apache cache logs too (removed oldapache_cacheplugin) @l2isbad - many more
web_logimprovements -web_logis now a lot more powerful! @l2isbad -
python.d.pluginLogServicenow supports monitoring web log files matching a pattern @l2isbad - disk monitoring under Linux now utilizes
/dev/mappernames. It also has improved docker compatibility. -
haproxyimprovements @l2isbad -
dns_query_timeplugin to monitor the response time of nameservers @l2isbad - Fronius Solar @BrainDoctor
- better support for monitoring Proxmox/qemu @efaden and libvirt/qemu VMs
-
cpufreqimprovements @l2isbad -
smartd_logimprovements @pkoenig10 -
bind_rndcrewritten @l2isbad -
lighttpdimprovements (part of theapacheplugin) -
isc_dhcpdimprovements @l2isbad -
fpingimprovements -
apps.pluginimprovements (added many more applications to monitor, notably hadoop and friends, improved compatibility) -
freeipmiimprovements -
mdstatimprovements @l2isbad -
mysqlimprovements @alibo -
redisimprovements @l2isbad -
postgresrds fixes @facetoe -
fail2banimprovements @l2isbad -
idlejitterrewritten -
openvpnimprovements @l2isbad -
numaimprovements @Benje06
New and improved alarms
-
alarm-notify.shnow supports custom notification methods (you can hook whatever you like to netdata alarms). - email notifications are now multipart (have both HTML and text versions in them)
- low memory alarm now excludes ZFS ARC.
- improved discord notifications.
- improved telegraf notifications @alibo
-
lighttpdalarm -
mongodbalarm @jnogol
Other improvements
- memory mode
ramutilizes KSM (kernel memory deduper). - many memory mode
mapimprovements for faster operation with huge databases. - netdata is now even faster on FreeBSD, thank to several optimization made by @vlvkobal
- netdata can now be compiled with
clang, even on FreeBSD - netdata can now be compiled on FreeBSD 10.3
Published by philwhineray over 7 years ago
New to netdata? Check its demo: https://my-netdata.io




Release announced on twitter, hacker news, reddit r/linux, reddit r/sysadmin, reddit r/linuxadmin, reddit r/freebsd reddit r/devops reddir r/homelab facebook
birthday release: 1 year netdata
netdata was first published on March 30th, 2016.
It has been a crazy year since then:
Central netdata is here!
This is the first release that supports real-time streaming of metrics between netdata servers.
netdata can now be:
- autonomous host monitoring (like it always has been)
- headless data collector (collect and stream metrics in real-time to another netdata)
- headless proxy (collect metrics from multiple netdata and stream them to another netdata)
- store and forward proxy (like headless proxy, but with a local database)
- central database (metrics from multiple hosts are aggregated)
metrics databases can be configured on all nodes and each node maintaining a database may have a different retention policy and possibly run (even different) alarms on them.
There are 4 settings that control what netdata can be:
-
[global].memory modeinnetdata.conf, controls if a netdata will maintain a local database and the type of it. For more information check Running a dedicated central netdata server. -
[web].modeinnetdata.conf, controls if netdata will expose its API, and the type of web server to enable (single or multi-threaded). Check netdata.conf configuration for streaming. -
[stream].enabledinstream.conf, controls if netdata will stream its metrics to another netdata. Check stream.conf for sending metrics. -
[API KEY].enabledinstream.conf, controls if netdata will accept metrics from other netdata. Check stream.conf for receiving metrics.
Using the above, we support a lot of different configurations, like these:
| target | memorymode | webmode | streamenabled | send tobackend | localalarms | localdashboard |
|---|---|---|---|---|---|---|
| headless collector | none |
none |
yes |
not possible | not possible | no |
| headless proxy | none |
not none
|
yes |
not possible | not possible | no |
| proxy with db | not none
|
not none
|
yes |
possible | possible | yes |
| central netdata | not none
|
not none
|
no |
possible | possible | yes |
monitoring ephemeral nodes
netdata now supports monitoring autoscaled ephemeral nodes, that are started and stopped on demand (their IP is not known).
When the ephemeral nodes start streaming metrics to the central netdata, the central netdata will show register them at my-netdata menu on the dashboard, like this:
You can see this live at https://build.my-netdata.io (this server may not always be available for demo).
For more information check: monitoring ephemeral nodes.
monitoring ephemeral containers and VM guests
netdata now cleans up container, guest VM, network interfaces and mounted disk metrics, disabling automatically their alarms too.
For more information check monitoring ephemeral containers.
apps.plugin ported for FreeBSD
Vladimir Kobal has ported apps.plugin to FreeBSD.
netdata can now provide Applications, Users and User Groups under FreeBSD too:
Also, the CPU utilization of netdata under FreeBSD, is now a lot less compared to netdata v1.5.
See it live at our FreeBSD demo server.
web_log plugin
Ilya Mashchenko has done a wonderful job creating a unified web log parsing plugin for all kinds of web server logs. With it, netdata provides real-time performance information and health monitoring alarms for web applications and web sites!
Requests by http status:

Requests by http status code family:

Requests by http status code:

Requests bandwidth:

Requests timings:

URL patterns of interest (you configure the patterns):

Requests by http method:

Requests by IP version:

Number of unique clients:

and a lot more, including alarms:
| alarm | description | minimumrequests | warning | critical |
|---|---|---|---|---|
1m_redirects |
The ratio of HTTP redirects (3xx except 304) over all the requests, during the last minute. Detects if the site or the web API is suffering from too many or circular redirects. (i.e. oops! this should not redirect clients to itself) | 120/min | > 20% | > 30% |
1m_bad_requests |
The ratio of HTTP bad requests (4xx) over all the requests, during the last minute. Detects if the site or the web API is receiving too many bad requests, including 404, not found. (i.e. oops! a few files were not uploaded) |
120/min | > 30% | > 50% |
1m_internal_errors |
The ratio of HTTP internal server errors (5xx), over all the requests, during the last minute. Detects if the site is facing difficulties to serve requests. (i.e. oops! this release crashes too much) | 120/min | > 2% | > 5% |
5m_requests_ratio |
The percentage of successful web requests of the last 5 minutes, compared with the previous 5 minutes. Detects if the site or the web API is suddenly getting too many or too few requests. (i.e. too many = oops! we are under attack)(i.e. too few = oops! call the network guys) | 120/5min | > double or < half | > 4x or < 1/4x |
web_slow |
The average time to respond to requests, over the last 1 minute, compared to the average of last 10 minutes. Detects if the site or the web API is suddenly a lot slower. (i.e. oops! the database is slow again) | 120/min | > 2x | > 4x |
1m_successful |
The ratio of successful HTTP responses (1xx, 2xx, 304) over all the requests, during the last minute. Detects if the site or the web API is performing within limits. (i.e. oops! help us God!) | 120/min | < 85% | < 75% |
For more information check: the spectacles of a web server log file.
backends
netdata can now archive metrics to JSON backends (both push, by @lfdominguez, and pull modes).
IPMI monitoring
netdata now has an IPMI plugin (based on freeipmi) for monitoring server hardware.
The plugin creates (up to) 8 charts, based on the information collected from IPMI:
- number of sensors by state
- number of events in SEL
- Temperatures CELCIUS
- Temperatures FAHRENHEIT
- Voltages
- Currents
- Power
- Fans
It also supports alarms (including the number of sensors in critical state):

For more information, check monitoring IPMI.
New Plugins
Ilya Mashchenko builds python data collection plugins for netdata at an wonderfull rate! He rocks!
- web_log for monitoring in real-time all kinds of web server log files @l2isbad
- freeipmi for monitoring IPMI (server hardware)
- nsd (the name server daemon) @383c57
- mongodb @l2isbad
- smartd_log (monitoring disk S.M.A.R.T. values) @l2isbad
Improved Plugins
- nfacct reworked and now collects connection tracker information using netlink.
- ElasticSearch re-worked @l2isbad
- mysql re-worked to allow faster development of custom mysql based plugins (MySQLService) @l2isbad
- SNMP
- tomcat @NMcCloud
- ap (monitoring hostapd access points)
- php_fpm @l2isbad
- postgres @l2isbad
- isc_dhcpd @l2isbad
- bind_rndc @l2isbad
- numa
- apps.plugin improvements and freebsd support @vlvkobal
- fail2ban @l2isbad
- freeradius @l2isbad
- nut (monitoring UPSes)
- tc (Linux QoS) now works on qdiscs instead of classes for the same result (a lot faster) @t-h-e
- varnish @l2isbad
New and Improved Alarms
- web_log, many alarms to detect common web site/API issues
- fping, alarms to detect packet loss, disconnects and unusually high latency
-
cpu, cpu utilization alarm now ignores
nice
New and improved alarm notification methods
- HipChat to allow hosted HipChat @frei-style
- discordapp @lowfive
Dashboard Improvements
- dashboard now works on HiDPi screens
- dashboard now shows version of netdata
- dashboard now resets charts properly
- dashboard updated to use latest gauge.js release
Other Improvements
- thanks to @rlefevre netdata now uses a lot of different high resolution system clocks.
netdata has received a lot more improvements from many more contributors! (it was really a lot of work to dig into git log to collect all the above, so forgive me if I forgot to mention a few contributions and contributors).
Thank you all!
Published by ktsaou over 7 years ago
New to netdata? Check its demo: http://my-netdata.io
Release announced on twitter, hacker news, reddit r/linux, reddit r/sysadmin, reddit r/linuxadmin, reddit r/freebsd
Yet another release that makes netdata the fastest netdata ever!
This is probably the release with the largest changeset so far. A lot of work, by a lot of people made this release possible!
FreeBSD, MacOS and FreeNAS
Vladimir Kobal has done a magnificent work porting netdata to FreeBSD and MacOS.
Everything works:
- cpu and interrupts, memory, disks (performance and space monitoring)
- network interfaces and softnet
- IPv4 and IPv6 metrics
- processes and context switches
- IPC (queues, semaphores, shared memory)
- and of course all the netdata external plugins
Wow! Check it live on FreeBSD, at https://freebsd.my-netdata.io/
Backends
netdata supports data archiving to backend databases:
- Graphite
- OpenTSDB
- Prometheus
and of course all the compatible ones (KairosDB, InfluxDB, Blueflood, etc)

With this feature netdata can interface with your existing devops infrastructure and allow you to visualize its metrics with other tools, like grafana.
New Plugins
Ilya Mashchenko has created most of the python data collection plugins in this release! He rocks!
- Systemd Services (real-time monitoring of the resource utilization of all systemd services, using cgroups!)
- FPing (network latency and jitter monitoring with netdata!)
- Postgres databases @facetoe, @moumoul
- Vanish disk cache (v3 and v4) @l2isbad
- ElasticSearch @l2isbad
- HAproxy @l2isbad
- FreeRadius @l2isbad, @lgz
- mdstat (RAID) @l2isbad
- ISC bind (via rndc) @l2isbad
- ISC dhcpd @l2isbad, @lgz
- Fail2Ban @l2isbad
- OpenVPN status log @l2isbad, @lgz
- NUMA memory @tycho
- CPU Idle States @tycho
- gunicorn @deltaskelta
- ECC memory hardware errors
- IPC semaphores
-
uptime ( with a nice badge too:
 )
)
Improved Plugins
- netfilter conntrack
- MySQL/MariaDB (replication) @l2isbad
- ipfs @pjz
- cpufreq @tycho
- hddtemp @l2isbad
- sensors @l2isbad
- nginx @leolovenet
- nginx_log @paulfantom
- phpfpm @leolovenet
- redis @leolovenet
- dovecot @justohall
- cgroups
- disk space
- apps.plugin
- /proc/interrupts @rlefevre
- /proc/softirqs @rlefevre
- /proc/vmstat (system memory charts)
- /proc/net/snmp6 (IPv6 charts)
- /proc/self/meminfo (system memory charts)
- /proc/net/dev (network interfaces)
- tc (linux QoS)
New and Improved Alarms
- MySQL/MariaDB alarms (incl. replication)
- IPFS alarms
- HAproxy alarms
- UDP buffer alarms
- TCP AttemptFails
- ECC memory alarms
- netfilter connections alarms
New Alarm Notification Methods
- messagebird.com @tech-no-logical
- pagerduty.com @jimcooley
- pushbullet.com @tperalta82
- twilio.com @shadycuz
- HipChat
- kafka
Shell Integration
Shell scripts can now query netdata easily!
eval "$(curl -s 'http://localhost:19999/api/v1/allmetrics')"
after this command, all the netdata metrics are exposed to shell. Check:
# source the metrics
eval "$(curl -s 'http://localhost:19999/api/v1/allmetrics')"
# let's see if there are variables exposed by netdata for system.cpu
set | grep "^NETDATA_SYSTEM_CPU"
NETDATA_SYSTEM_CPU_GUEST=0
NETDATA_SYSTEM_CPU_GUEST_NICE=0
NETDATA_SYSTEM_CPU_IDLE=95
NETDATA_SYSTEM_CPU_IOWAIT=0
NETDATA_SYSTEM_CPU_IRQ=0
NETDATA_SYSTEM_CPU_NICE=0
NETDATA_SYSTEM_CPU_SOFTIRQ=0
NETDATA_SYSTEM_CPU_STEAL=0
NETDATA_SYSTEM_CPU_SYSTEM=1
NETDATA_SYSTEM_CPU_USER=4
NETDATA_SYSTEM_CPU_VISIBLETOTAL=5
# let's see the total cpu utilization of the system
echo ${NETDATA_SYSTEM_CPU_VISIBLETOTAL}
5
# what about alarms?
set | grep "^NETDATA_ALARM_SYSTEM_SWAP_"
NETDATA_ALARM_SYSTEM_SWAP_RAM_IN_SWAP_STATUS=CRITICAL
NETDATA_ALARM_SYSTEM_SWAP_RAM_IN_SWAP_VALUE=53
NETDATA_ALARM_SYSTEM_SWAP_USED_SWAP_STATUS=CLEAR
NETDATA_ALARM_SYSTEM_SWAP_USED_SWAP_VALUE=51
# let's get the current status of the alarm 'ram in swap'
echo ${NETDATA_ALARM_SYSTEM_SWAP_RAM_IN_SWAP_STATUS}
CRITICAL
# is it fast?
time curl -s 'http://localhost:19999/api/v1/allmetrics' >/dev/null
real 0m0,070s
user 0m0,000s
sys 0m0,007s
# it is...
# 0.07 seconds for curl to be loaded, connect to netdata and fetch the response back...
The _VISIBLETOTAL variable sums up all the dimensions of each chart.
The format of the variables is:
NETDATA_${chart_id^^}_${dimension_id^^}="${value}"
The value is rounded to the closest integer, since shell script cannot process decimal numbers.
Dashboard Improvements
- dashboard is now faster on firefox, safari, opera, edge (edge is still the slowest)
- dashboard charts legends now have bigger fonts
- SHIFT + mousewheel to zoom charts, works on all browsers
- perfect-scrollbar on the dashboard
- dashboard 4K resolution fixes
- dashboard compatibility fixes for embedding charts in third party web sites
- charts on custom dashboards can have common min/max even if they come from different netdata servers
- alarm log is now saved and loaded back so that the alarm history is available at the dashboard
Other Improvements
- python.d.plugin has received way to many improvements from many contributors!
- charts.d.plugin can now be forked to support multiple independent instances
- registry has been re-factored to lower its memory requirements (required for the public registry)
- simple patterns in cgroups, disks and alarms
- netdata-installer.sh can now correctly install netdata in containers
- supplied logrotate script compatibility fixes
- spec cleanup @breed808
- clocks and timers reworked @rlefevre
netdata has received a lot more improvements from many more contributors! (it was really a lot of work to dig into git log to collect all the above, so forgive me if I forgot to mention a few contributions and contributors).
Thank you all!
Published by ktsaou about 8 years ago
New to netdata? Check its demo: http://my-netdata.io
Release announced on Hacker News
Release announced on reddit r/linux
Release announced on reddit r/sysadmin
Release announced on twitter
At a glance
- the fastest netdata ever (with a better look too)!
- improved IoT and containers support!
- alarms improved in almost every way!
- new plugins:
- softnet netdev,
- extended TCP metrics,
- UDPLite
- NFS v2, v3 client (server was there already),
- NFS v4 server & client,
- APCUPSd,
- RetroShare
- improved plugins:
- mysql,
- cgroups,
- hddtemp,
- sensors,
- phpfm,
- tc (QoS)
In detail
improved alarms!
Many new alarms have been added to detect common kernel configuration errors and old alarms have been re-worked to avoid notification floods.
Alarms now support:
-
notification hysteresis (both static and dynamic)

-
notification self-cancellation, and
-
dynamic thresholds based on current alarm status

Also, a new alarms log:

improved alarm notifications
netdata now supports:
- email notifications
- slack.com notifications on slack channels
- pushover.net notifications (mobile push notifications)
- telegram.org notifications
For all the above methods, netdata supports role-based notifications, with multiple recipients for each role and severity filtering per recipient!
Also, netdata support HTML5 notifications, while the dashboard is open in a browser window (no need to be the active one).

All notifications (HTML5, emails, slack, pushover, telegram) are now clickable to get to the chart that raised the alarm.
other improvements
-
improved IoT support!
netdata builds and runs with musl libc and runs on systems based on busybox.
-
improved containers support!
netdata runs on alpine linux (a low profile linux distribution used in containers).
-
Dozens of other improvements and bugfixes
netdata 1.4.0 - download release tarfiles from http://firehol.org/download/netdata/releases/v1.4.0
Published by ktsaou about 8 years ago
New to netdata? Check its demo: http://my-netdata.io
At a glance
- netdata has health monitoring / alarms!
- netdata generates badges that can be embeded anywhere!
- netdata plugins are now written in python!
- new plugins: redis, memcached, nginx_log, ipfs, apache_cache
IMPORTANT:
Since netdata now uses python plugins, new packages are
required to be installed on a system to allow it work.
For more information, please check the installation page.
In detail
netdata has alarms!
Based on the POLL we made on github, health monitoring was the winner. So here it is!
netdata now has a powerful health monitoring system embedded.

netdata has badges!
netdata can generate badges with live information from the collected metrics.
netdata plugins are now written in python!
Thanks to the great work of Paweł Krupa (@paulfantom), most BASH plugins have been ported to python.
The new python.d.plugin supports both python2 and python3 and data collection from multiple sources for all modules.
The following pre-existing modules have been ported to python:
- apache
- cpufreq
- example
- exim
- hddtemp
- mysql
- nginx
- phpfm
- postfix
- sensors
- squid
- tomcat
The following new modules have been added:
- apache_cache
- dovecot
- ipfs
- memcached
- nginx_log
- redis
other data collectors
Thanks to @simonnagl netdata now reports disk space usage.
other improvements
-
dashboards now transfer certain settings from server to server when changing servers via the my-netdata menu.
The settings transferred are the dashboard theme, the online help status and current pan and zoom timeframe of the dashboard.
-
API improvements:
- reduction functions now support 'min', 'sum' and 'incremental-sum'.
- netdata now offers a multi-threaded and a single threaded web server (single threaded is better for IoT).
-
apps.plugin improvements:
- can now run with command line argument 'without-files' to prevent it from enumating all the open files/sockets/pipes of all running processes.
- apps.plugin now scales the collected values to match the
the total system usage. - apps.plugin can now report guest CPU usage per process.
- repeating errors are now logged once per process.
-
netdata now runs with IDLE process priority (lower than nice 19)
-
netdata now instructs the kernel to kill it first when it starves for memory.
-
netdata listens for signals:
- SIGHUP to netdata instructs it to re-open its log files (new logrotate file added too).
- SIGUSR1 to netdata saves the database
- SIGUSR2 to netdata reloads health / alarms configuration
-
netdata can now bind to multiple IPs and ports.
-
netdata now has new systemd service file (it starts as user netdata and does not fork).
-
Dozens of other improvements and bugfixes
netdata 1.3.0 - download release tarfiles from http://firehol.org/download/netdata/releases/v1.3.0
Published by ktsaou over 8 years ago
Netdata demo sites: http://my-netdata.io
At a glance
- netdata now is 30% faster !
- netdata now has a registry (my-netdata dashboard menu) !
- netdata now monitors Linux Containers (cgroups, docker, lxc, etc) !
IMPORTANT:
This version requires libuuid. The package you need to build netdata is:
- uuid-dev (debian/ubuntu), or
- libuuid-devel (centos/fedora/redhat)
In detail
netdata is now 30% faster !
- Patches submitted by @fredericopissarra improved overall netdata performance by 10%.
- A new improved search function in the internal indexes made all searches faster by 50%, resulting in about 20% better performance for the core of netdata.
- More efficient threads locking in key components contributed to the overall speed up.
netdata now has a central registry !
The central registry tracks all your netdata servers and bookmarks them for you at the my-netdata menu on all dashboards.
Every netdata can act as a registry, but there is also a global registry provided for free for all netdata users!
netdata now monitors Linux Containers !
docker, lxc, or anything else. For each container it monitors CPU, RAM, DISK I/O (network interfaces were already monitored).
Other improvements
- apps.plugin: now uses linux capabilities by default without setuid to root
- netdata has now an improved signal handler thanks to @simonnagl
- API: new improved CORS support
- SNMP: counter64 support fixed
- MYSQL: more charts, about QCache, MyISAM key cache, InnoDB buffer pools, open files
- DISK charts now show mount point when available
- Dashboard: improved support for older web browsers and mobile web browsers (thanks to @simonnagl)
- Multi-server dashboards now allow de-coupled refreshes for each chart, so that if one netdata has a network latency the other charts are not affected
- Dozens of other improvements, optimizations and bug-fixes.
netdata 1.2.0 - download release tarfiles also from http://firehol.org/download/netdata/releases/v1.2.0
Published by ktsaou over 8 years ago
netdata 1.1.0 - download release tarfiles from http://firehol.org/download/netdata/releases/v1.1.0
Dozens of commits that improve netdata in several ways:
Data collection
- added IPv6 monitoring
- added SYNPROXY DDoS protection monitoring
- apps.plugin: added charts for users and user groups
- apps.plugin: grouping of processes now support patterns
- apps.plugin: now it is faster, after the new features added
- better auto-detection of partitions for disk monitoring
- better fireqos intergation for QoS monitoring
- squid monitoring now uses squidclient
- SNMP monitoring now supports 64bit counters
API
- fixed issues in CSV output generation
- netdata can now be restricted to listen on a specific IP (API and web server)
Core
- added error log flood protection
Web Dashboard
- better error handling when the netdata server is unreachable
- each chart now has a toolbox
- on-line help support
- check for netdata updates button
- added example /tv.html dashboard
- now compiles with musl libc (alpine linux)
Packaging
- added debian packaging
- support non-root installations
- the installer generates uninstall script
Published by ktsaou over 8 years ago
netdata 1.0.0 - download release tarfiles from http://firehol.org/download/netdata/releases/v1.0.0
Published by ktsaou over 8 years ago
Published by ktsaou about 9 years ago