
HarvestText
文本挖掘和预处理工具(文本清洗、新词发现、情感分析、实体识别链接、关键词抽取、知识抽取、句法分析等),无监督或弱监督方法
MIT License
HarvestText
HarvestText : A Toolkit for Text Mining and Preprocessing
HarvestText
:
-
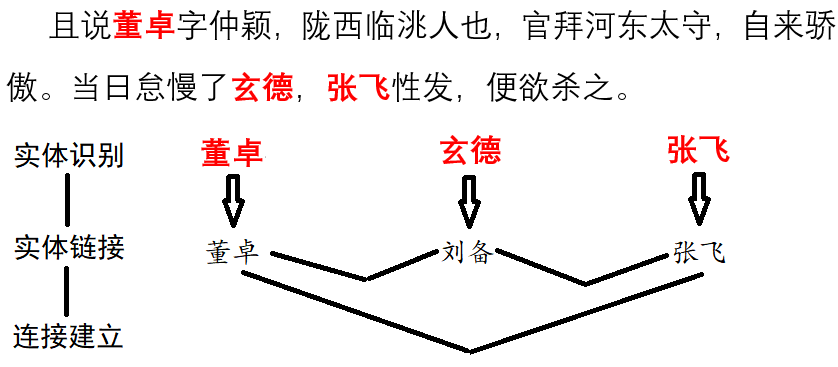
-
2018[]
matplotlib
README
:
- [](#)
-
- [](#)
- URL, email,
- [](#)
-
- [](#)
-
- [()](./examples/entity_discover/entity_discover.ipynb)
- [](#)[](./examples/entity_discover/entity_discover.ipynb)
- [](#)
-
- [](#)
- IT
- [](#)
-
- [](#)
-
- [()](#)
-
- [](#)
- TextTiling/
- [](#)
-
- [](#)
-
pip
pip install --upgrade harvesttext
setup.py:
python setup.py install
from harvesttext import HarvestText
ht = HarvestText()
#
pip install pattern
# python <= 3.8
pip install pyhanlp
para = ""
entity_mention_dict = {'':['',''],'':['',''],'':[''],'':[''],'':[''],'':['']}
entity_type_dict = {'':'','':'','':'','':'','':'','':''}
ht.add_entities(entity_mention_dict,entity_type_dict)
print("\nSentence segmentation")
print(ht.seg(para,return_sent=True)) # return_sent=False
print("\nPOS tagging with entity types")
for word, flag in ht.posseg(para):
print("%s:%s" % (word, flag),end = " ")
: :uj : :c : :uj : :x :r :v :ns :a :uj : :x :r :d :v : : :ul :x :r :v :n :m :x :d :v :n :uj : :d :v :ul :d
for span, entity in ht.entity_linking(para):
print(span, entity)
[0, 2] ('', '##') [3, 5] ('', '##') [6, 8] ('', '##') [9, 11] ('', '##') [19, 21] ('', '##') [26, 28] ('', '##') [28, 31] ('', '##') [47, 49] ('', '##')
print(ht.cut_sentences(para))
['', '']
""keep_all=Trueel_keep_all()
"""A""B"xx/yyxx/yy linking_strategy()
@emailhtml %20
print("")
ht0 = HarvestText()
#
text1 = "@QXM:[][] //@QXM:[good][good]"
print("@")
print("", text1)
print("", ht0.clean_text(text1))
@
@QXM:[][] //@QXM:[good][good]
# URL
text1 = "## ....http://t.cn/8FLopdQ"
print("URL")
print("", text1)
print("", ht0.clean_text(text1, remove_url=True))
URL
## ....http://t.cn/8FLopdQ
## ....
#
text1 = "[email protected]"
print("")
print("", text1)
print("", ht0.clean_text(text1, email=True))
[email protected]
# URL
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL")
print("", text1)
print("", ht0.clean_text(text1, norm_url=True, remove_url=False))
URL
www.%E4%B8%AD%E6%96%87%20and%20space.com
www. and space.com
text1 = "www. and space.com"
print("URL[request]")
print("", text1)
print("", ht0.clean_text(text1, to_url=True, remove_url=False))
URL[request]
www. and space.com
www.%E4%B8%AD%E6%96%87%20and%20space.com
# HTML
text1 = "<a c> ''"
print("HTML")
print("", text1)
print("", ht0.clean_text(text1, norm_html=True))
HTML
<a c> ''
<a c> ''
#
text1 = ""
print("")
print("", text1)
print("", ht0.clean_text(text1, t2s=True))
# markdown
text1 = "[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)"
print("markdown")
print("", text1)
print("", ht0.clean_text(text1, t2s=True))
markdown
[HarvestText : A Toolkit for Text Mining and Preprocessing](https://github.com/blmoistawinde/HarvestText)
HarvestText : A Toolkit for Text Mining and Preprocessing
ht0 = HarvestText()
sent = ""
print(ht0.named_entity_recognition(sent))
{'': '', '': '', '': ''}
ht0 = HarvestText()
para = ""
entity_mention_dict = {'': ['', ''], "":[""]}
entity_type_dict = {'': '', "":""}
ht0.add_entities(entity_mention_dict, entity_type_dict)
for arc in ht0.dependency_parse(para):
print(arc)
print(ht0.triple_extraction(para))
[0, '', '', '', 3]
[1, '', 'u', '', 0]
[2, '', '', '', 3]
[3, '', '', '', 4]
[4, '', 'v', '', -1]
[5, '', 'ns', '', 8]
[6, '', 'd', '', 8]
[7, '', 'u', '', 6]
[8, '', 'n', '', 4]
[9, '', 'w', '', 4]
print(ht0.triple_extraction(para))
[['', '', '']]
V0.7tolerance
def entity_error_check():
ht0 = HarvestText()
typed_words = {"":[""]}
ht0.add_typed_words(typed_words)
sent0 = ""
print(sent0)
print(ht0.entity_linking(sent0, pinyin_tolerance=0))
"""
[([0, 2], ('', '##')), [(3, 5), ('', '##')]]
"""
sent1 = ""
print(sent1)
print(ht0.entity_linking(sent1, pinyin_tolerance=1))
"""
[([0, 2], ('', '##')), [(3, 5), ('', '##')]]
"""
sent2 = ""
print(sent2)
print(ht0.entity_linking(sent2, char_tolerance=1))
"""
[([0, 2], ('', '##')), [(3, 5), ('', '##')]]
"""
sent3 = ""
print(sent3)
print(ht0.get_linking_mention_candidates(sent3, pinyin_tolerance=1, char_tolerance=1))
"""
('', defaultdict(<class 'list'>, {(0, 2): {''}, (3, 5): {''}}))
"""
print("\nsentiment dictionary")
sents = ["",
"",
"",
""]
sent_dict = ht.build_sent_dict(sents,min_times=1,pos_seeds=[""],neg_seeds=[""])
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
sentiment dictionary :1.000000 :0.000000 :-1.000000
print("\nsentence sentiment")
sent = ""
print("%f:%s" % (ht.analyse_sent(sent),sent))
0.600000:
SO-PMI[0,1][-1,1]scale
print("\nsentiment dictionary using default seed words")
docs = ["",
"",
"",
""
]
# scale: [-1,1]
# pos_seeds, neg_seeds, get_qh_sent_dict()
print("scale=\"0-1\", 100.5")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="0-1")
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
sentiment dictionary using default seed words
scale="0-1", 100.5
:1.000000
:0.153846
:0.000000
0.449412:
0.364910:
print("scale=\"+-1\", 0")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
print("%s:%f" % ("",sent_dict[""]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
scale="+-1", 0
:1.000000
:0.000000
:-1.000000
0.349305:
-0.159652:
add_entities
docs = ["",
"",
"",
""]
inv_index = ht.build_index(docs)
print(ht.get_entity_counts(docs, inv_index)) #
# {'': 3, '': 2, '': 2}
print(ht.search_entity("", docs, inv_index)) #
# ['', '', '']
print(ht.search_entity(" ", docs, inv_index)) #
# ['']
#
subdocs = ht.search_entity("## ", docs, inv_index)
print(subdocs) #
# ['', '']
inv_index2 = ht.build_index(subdocs)
print(ht.get_entity_counts(subdocs, inv_index2, used_type=[""])) #
# {'': 2, '': 1}
(networkx) (networkx.Graph)
#
ht.add_new_entity("", "", "")
docs = ["",
""]
G = ht.build_entity_graph(docs)
print(dict(G.edges.items()))
G = ht.build_entity_graph(docs, used_types=[""])
print(dict(G.edges.items()))
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
ht0.add_entities(entity_mention_dict, entity_type_dict)
sanguo1 = get_sanguo()[0]
stopwords = get_baidu_stopwords()
docs = ht0.cut_sentences(sanguo1)
G = ht0.build_word_ego_graph(docs,"",min_freq=3,other_min_freq=2,stopwords=stopwords)
(networkx) Textrank(maxlen)
print("\nText summarization")
docs = ["",
"",
"",
""]
for doc in ht.get_summary(docs, topK=2):
print(doc)
print("\nText summarization()")
for doc in ht.get_summary(docs, topK=3, avoid_repeat=True):
print(doc)
Text summarization
Text summarization()
textrankHarvestTextjiebajieba_tfidf
(example)
# text
print("")
kwds = ht.extract_keywords(text, 5, method="jieba_tfidf")
print("jieba_tfidf", kwds)
kwds = ht.extract_keywords(text, 5, method="textrank")
print("textrank", kwds)
jieba_tfidf ['', '', '', '', '']
textrank ['', '', '', '', '']
| P@5 | R@5 | F@5 | |
|---|---|---|---|
| textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_textrank | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
demo
-
get_qh_sent_dict: http://nlp.csai.tsinghua.edu.cn/site2/index.php/13-sms -
get_baidu_stopwords: https://wenku.baidu.com/view/98c46383e53a580216fcfed9.html -
get_qh_typed_words: THUNLP http://thuocl.thunlp.org/['IT', '', '', '', '', '', '', '', ''] -
get_english_senti_lexicon: -
get_jieba_dict: jieba
def load_resources():
from harvesttext.resources import get_qh_sent_dict,get_baidu_stopwords,get_sanguo,get_sanguo_entity_dict
sdict = get_qh_sent_dict() # {"pos":[...],"neg":[...]}
print("pos_words:",list(sdict["pos"])[10:15])
print("neg_words:",list(sdict["neg"])[5:10])
stopwords = get_baidu_stopwords()
print("stopwords:", list(stopwords)[5:10])
docs = get_sanguo() #
print("16:\n",docs[-1][-16:])
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
print(" ",entity_mention_dict[""])
print(" ",entity_type_dict[""])
print(" ", entity_type_dict[""])
print(" ", entity_type_dict[""])
load_resources()
pos_words: ['', '', '', '', '']
neg_words: ['', '', '', '', '']
stopwords: ['apart', '', '', 'probably', 'think']
16:
['', '', '']
def using_typed_words():
from harvesttext.resources import get_qh_typed_words,get_baidu_stopwords
ht0 = HarvestText()
typed_words, stopwords = get_qh_typed_words(), get_baidu_stopwords()
ht0.add_typed_words(typed_words)
sentence = "THUOCL"
print(sentence)
print(ht0.posseg(sentence,stopwords=stopwords))
using_typed_words()
THUOCL
[('THUOCL', 'eng'), ('', 'IT'), ('', 'm'), ('', 'nz'), ('', 'n'), ('', 'n'), ('', 'v'), ('', 'b'), ('', 'n'), ('', 'n'), ('', ''), ('', 'v'), ('', 'n'), ('', 'IT'), ('', 'n')]
IT,
para = ""
#(pd.DataFrame)
new_words_info = ht.word_discover(para)
#new_words_info = ht.word_discover(para, threshold_seeds=[""])
new_words = new_words_info.index.tolist()
print(new_words)
[""]
auto_param=False
:param max_word_len:
:param min_freq:
:param min_entropy:
:param min_aggregation:
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
http://www.matrix67.com/blog/archives/5044
def new_word_register():
new_words = ["","666"]
ht.add_new_words(new_words) # ""
ht.add_new_entity("", mention0="", type0="") #
print(ht.seg("666", return_sent=True))
for word, flag in ht.posseg("666"):
print("%s:%s" % (word, flag), end=" ")
666
:r : :v :ud :d 666:
**
# find_with_rules()
from harvesttext.match_patterns import UpperFirst, AllEnglish, Contains, StartsWith, EndsWith
text0 = "Pythonrequests"
ht0 = HarvestText()
found_entities = ht0.find_entity_with_rule(text0, rulesets=[AllEnglish()], type0="")
print(found_entities)
print(ht0.posseg(text0))
{'Python', 'requests'}
[('', 'r'), ('', 'v'), ('Python', ''), ('', 'x'), ('', 'c'), ('requests', ''), ('', 'n'), ('', 'd'), ('', 'v'), ('', 'n')]
TextTiling/
ht0 = HarvestText()
text = """13919
201932419
80
185"""
print("[5]")
print(text+"\n")
print("[3]")
predicted_paras = ht0.cut_paragraphs(text, num_paras=3)
print("\n".join(predicted_paras)+"\n")
[5]
13919
201932419
80
185
[3]
13919
201932419
80185
seq_chars``align_boundary=False``examples/basic.py``cut_paragraph()
print("")
text2 = extract_only_chinese(text)
predicted_paras2 = ht0.cut_paragraphs(text2, num_paras=5, seq_chars=10, align_boundary=False)
print("\n".join(predicted_paras2)+"\n")
from harvesttext import loadHT,saveHT
para = ""
saveHT(ht,"ht_model1")
ht2 = loadHT("ht_model1")
#
ht2.clear()
print("cut with cleared model")
print(ht2.seg(para))
QA = NaiveKGQA(SVOs, entity_type_dict=entity_type_dict)
questions = ["","","","",
"",""]
for question0 in questions:
print(""+question0)
print(""+QA.answer(question0))
HarvestText
# "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""".lower()
ht_eng = HarvestText(language="en")
sentences = ht_eng.cut_sentences(test_text) #
print("\n".join(sentences))
print(ht_eng.seg(sentences[-1])) # []
print(ht_eng.posseg(sentences[0], stopwords={"in"}))
#
sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=["familiar"], neg_seeds=["lonely"],
min_times=1, stopwords={'in', 'to'})
print("sentiment analysis")
for sent0 in sentences:
print(sent0, "%.3f" % ht_eng.analyse_sent(sent0))
#
print("Segmentation")
print("\n".join(ht_eng.cut_paragraphs(test_text, num_paras=2)))
#
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1)
in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
@misc{zhangHarvestText,
author = {Zhiling Zhang},
title = {HarvestText: A Toolkit for Text Mining and Preprocessing},
journal = {GitHub repository},
howpublished = {\url{https://github.com/blmoistawinde/HarvestText}},
year = {2023}
}
More
issuesStar~
repo