
koalas
Koalas: pandas API on Apache Spark
APACHE-2.0 License
Bot releases are hidden (Show)
Koalas 1.8.2 is a maintenance release.
Koalas is officially included in PySpark as pandas API on Spark in Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Although moving to pandas API on Spark is recommended, Koalas 1.8.2 still works with Spark 3.2 (#2203).
Improvements and bug fixes
- _builtin_table import in groupby apply (changed in pandas>=1.3.0). (#2184)
Published by xinrong-meng over 3 years ago
Koalas 1.8.1 is a maintenance release. Koalas will be officially included in PySpark in the upcoming Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Improvements and bug fixes
- Remove the upperbound for numpy. (#2166)
- Allow Python 3.9 when the underlying PySpark is 3.1 and above. (#2167)
Along with the following fixes:
- Support x and y properly in plots (both matplotlib and plotly). (#2172)
- Fix Index.different to work properly. (#2173)
- Fix backward compatibility for Python version 3.5.*. (#2174)
Published by HyukjinKwon over 3 years ago
Koalas 1.8.0 is the last minor release because Koalas will be officially included in PySpark in the upcoming Apache Spark 3.2. In Apache Spark 3.2+, please use Apache Spark directly.
Categorical type and ExtensionDtype
We added the support of pandas' categorical type (#2064, #2106).
>>> s = ks.Series(list("abbccc"), dtype="category")
>>> s
0 a
1 b
2 b
3 c
4 c
5 c
dtype: category
Categories (3, object): ['a', 'b', 'c']
>>> s.cat.categories
Index(['a', 'b', 'c'], dtype='object')
>>> s.cat.codes
0 0
1 1
2 1
3 2
4 2
5 2
dtype: int8
>>> idx = ks.CategoricalIndex(list("abbccc"))
>>> idx
CategoricalIndex(['a', 'b', 'b', 'c', 'c', 'c'],
categories=['a', 'b', 'c'], ordered=False, dtype='category')
>>> idx.codes
Int64Index([0, 1, 1, 2, 2, 2], dtype='int64')
>>> idx.categories
Index(['a', 'b', 'c'], dtype='object')
and ExtensionDtype as type arguments to annotate return types (#2120, #2123, #2132, #2127, #2126, #2125, #2124):
def func() -> ks.Series[pd.Int32Dtype()]:
...
Other new features, improvements and bug fixes
We added the following new features:
DataFrame:
-
first(#2128) -
at_time(#2116)
Series:
-
at_time(#2130) -
first(#2128) -
between_time(#2129)
DatetimeIndex:
-
indexer_between_time(#2104) -
indexer_at_time(#2109) -
between_time(#2111)
Along with the following fixes:
- Support tuple to (DataFrame|Series).replace() (#2095)
- Check index_dtype and data_dtypes more strictly. (#2100)
- Return actual values via toPandas. (#2077)
- Add lines and orient to read_json and to_json to improve error message (#2110)
- Fix isin to accept numpy array (#2103)
- Allow multi-index column names for inferring return type schema with names. (#2117)
- Add a short JDBC user guide (#2148)
- Remove upper bound pandas 1.2 (#2141)
- Standardize exceptions of arithmetic operations on Datetime-like data (#2101)
Published by itholic over 3 years ago
Switch the default plotting backend to Plotly
We switched the default plotting backend from Matplotlib to Plotly (#2029, #2033). In addition, we added more Plotly methods such as DataFrame.plot.kde and Series.plot.kde (#2028).
import databricks.koalas as ks
kdf = ks.DataFrame({
'a': [1, 2, 2.5, 3, 3.5, 4, 5],
'b': [1, 2, 3, 4, 5, 6, 7],
'c': [0.5, 1, 1.5, 2, 2.5, 3, 3.5]})
kdf.plot.hist()

Plotting backend can be switched to matplotlib by setting ks.options.plotting.backend to matplotlib.
ks.options.plotting.backend = "matplotlib"
Add Int64Index, Float64Index, DatatimeIndex
We added more types of Index such as Index64Index, Float64Index and DatetimeIndex (#2025, #2066).
When creating an index, Index instance is always returned regardless of the data type.
But now Int64Index, Float64Index or DatetimeIndex is returned depending on the data type of the index.
>>> type(ks.Index([1, 2, 3]))
<class 'databricks.koalas.indexes.numeric.Int64Index'>
>>> type(ks.Index([1.1, 2.5, 3.0]))
<class 'databricks.koalas.indexes.numeric.Float64Index'>
>>> type(ks.Index([datetime.datetime(2021, 3, 9)]))
<class 'databricks.koalas.indexes.datetimes.DatetimeIndex'>
In addition, we added many properties for DatetimeIndex such as year, month, day, hour, minute, second, etc. (#2074) and added APIs for DatetimeIndex such as round(), floor(), ceil(), normalize(), strftime(), month_name() and day_name() (#2082, #2086, #2089).
Create Index from Series or Index objects
Index can be created by taking Series or Index objects (#2071).
>>> kser = ks.Series([1, 2, 3], name="a", index=[10, 20, 30])
>>> ks.Index(kser)
Int64Index([1, 2, 3], dtype='int64', name='a')
>>> ks.Int64Index(kser)
Int64Index([1, 2, 3], dtype='int64', name='a')
>>> ks.Float64Index(kser)
Float64Index([1.0, 2.0, 3.0], dtype='float64', name='a')
>>> kser = ks.Series([datetime(2021, 3, 1), datetime(2021, 3, 2)], index=[10, 20])
>>> ks.Index(kser)
DatetimeIndex(['2021-03-01', '2021-03-02'], dtype='datetime64[ns]', freq=None)
>>> ks.DatetimeIndex(kser)
DatetimeIndex(['2021-03-01', '2021-03-02'], dtype='datetime64[ns]', freq=None)
Extension dtypes support
We added basic extension dtypes support (#2039).
>>> kdf = ks.DataFrame(
... {
... "a": [1, 2, None, 3],
... "b": [4.5, 5.2, 6.1, None],
... "c": ["A", "B", "C", None],
... "d": [False, None, True, False],
... }
... ).astype({"a": "Int32", "b": "Float64", "c": "string", "d": "boolean"})
>>> kdf
a b c d
0 1 4.5 A False
1 2 5.2 B <NA>
2 <NA> 6.1 C True
3 3 NaN <NA> False
>>> kdf.dtypes
a Int32
b float64
c string
d boolean
dtype: object
The following types are supported per the installed pandas:
- pandas >= 0.24
Int8DtypeInt16DtypeInt32DtypeInt64Dtype
- pandas >= 1.0
BooleanDtypeStringDtype
- pandas >= 1.2
Float32DtypeFloat64Dtype
Binary operations and type casting are supported:
>>> kdf.a + kdf.b
0 5
1 7
2 <NA>
3 <NA>
dtype: Int64
>>> kdf + kdf
a b
0 2 8
1 4 10
2 <NA> 12
3 6 <NA>
>>> kdf.a.astype('Float64')
0 1.0
1 2.0
2 <NA>
3 3.0
Name: a, dtype: Float64
Other new features, improvements and bug fixes
We added the following new features:
koalas:
-
date_range(#2081) -
read_orc(#2017)
Series:
-
align(#2019)
DataFrame:
-
align(#2019) -
to_orc(#2024)
Along with the following fixes:
- PySpark 3.1.1 Support
- Preserve index for statistical functions with axis==1 (#2036)
- Use iloc to make sure it retrieves the first element (#2037)
- Fix numeric_only to follow pandas (#2035)
- Fix DataFrame.merge to work properly (#2060)
- Fix astype(str) for some data types (#2040)
- Fix binary operations Index by Series (#2046)
- Fix bug on pow and rpow (#2047)
- Support bool list-like column selection for loc indexer (#2057)
- Fix window functions to resolve (#2090)
- Refresh GitHub workflow matrix (#2083)
- Restructure the hierarchy of Index unit tests (#2080)
- Fix to delegate dtypes (#2061)
Published by HyukjinKwon over 3 years ago
Improved Plotly backend support
We improved plotting support by implementing pie, histogram and box plots with Plotly plot backend. Koalas now can plot data with Plotly via:
-
DataFrame.plot.pieandSeries.plot.pie(#1971)

-
DataFrame.plot.histandSeries.plot.hist(#1999)

-
Series.plot.box(#2007)

In addition, we optimized histogram calculation as a single pass in DataFrame (#1997) instead of launching each job to calculate each Series in DataFrame.
Operations between Series and Index
The operations between Series and Index are now supported as below (#1996):
>>> kser = ks.Series([1, 2, 3, 4, 5, 6, 7])
>>> kidx = ks.Index([0, 1, 2, 3, 4, 5, 6])
>>> (kser + 1 + 10 * kidx).sort_index()
0 2
1 13
2 24
3 35
4 46
5 57
6 68
dtype: int64
>>> (kidx + 1 + 10 * kser).sort_index()
0 11
1 22
2 33
3 44
4 55
5 66
6 77
dtype: int64
Support setting to a Series via attribute access
We have added the support of setting a column via attribute assignment in DataFrame, (#1989).
>>> kdf = ks.DataFrame({'A': [1, 2, 3, None]})
>>> kdf.A = kdf.A.fillna(kdf.A.median())
>>> kdf
A
0 1.0
1 2.0
2 3.0
3 2.0
Other new features, improvements and bug fixes
We added the following new features:
Series:
-
factorize(#1972) -
sem(#1993)
DataFrame
-
insert(#1983) -
sem(#1993)
In addition, we also implement new parameters:
- Add min_count parameter for Frame.sum. (#1978)
- Added ddof parameter for GroupBy.std() and GroupBy.var() (#1994)
- Support ddof parameter for std and var. (#1986)
Along with the following fixes:
- Fix stat functions with no numeric columns. (#1967)
- Fix DataFrame.replace with NaN/None values (#1962)
- Fix cumsum and cumprod. (#1982)
- Use Python type name instead of Spark's in error messages. (#1985)
- Use object.__setattr__ in Series. (#1991)
- Adjust Series.mode to match pandas Series.mode (#1995)
- Adjust data when all the values in a column are nulls. (#2004)
- Fix as_spark_type to not support "bigint". (#2011)
Published by xinrong-meng almost 4 years ago
Index operations support
We improved Index operations support (#1944, #1955).
Here are some examples:
-
Before
>>> kidx = ks.Index([1, 2, 3, 4, 5]) >>> kidx + kidx Int64Index([2, 4, 6, 8, 10], dtype='int64') >>> kidx + kidx + kidx Traceback (most recent call last): ... AssertionError: args should be single DataFrame or single/multiple Series>>> ks.Index([1, 2, 3, 4, 5]) + ks.Index([6, 7, 8, 9, 10]) Traceback (most recent call last): ... AssertionError: args should be single DataFrame or single/multiple Series -
After
>>> kidx = ks.Index([1, 2, 3, 4, 5]) >>> kidx + kidx + kidx Int64Index([3, 6, 9, 12, 15], dtype='int64')>>> ks.options.compute.ops_on_diff_frames = True >>> ks.Index([1, 2, 3, 4, 5]) + ks.Index([6, 7, 8, 9, 10]) Int64Index([7, 9, 13, 11, 15], dtype='int64')
Other new features and improvements
We added the following new features:
DataFrame:
-
swaplevel(#1928) -
swapaxes(#1946) -
dot(#1945) -
itertuples(#1960)
Series:
-
swaplevel(#1919) -
swapaxes(#1954)
Index:
-
to_list(#1948)
MultiIndex:
-
to_list(#1948)
GroupBy:
-
tail(#1949) -
median(#1957)
Other improvements and bug fixes
- Support DataFrame parameter in Series.dot (#1931)
- Add a best practice for checkpointing. (#1930)
- Remove implicit switch-ons of "compute.ops_on_diff_frames" (#1953)
- Fix Series._to_internal_pandas and introduce Index._to_internal_pandas. (#1952)
- Fix first/last_valid_index to support empty column DataFrame. (#1923)
- Use pandas' transpose when the data is expected to be small. (#1932)
- Fix tail to use the resolved copy (#1942)
- Avoid unneeded reset_index in DataFrameGroupBy.describe. (#1951)
- TypeError when Index.name / Series.name is not a hashable type (#1883)
- Adjust data column names before attaching default index. (#1947)
- Add plotly into the optional dependency in Koalas (#1939)
- Add plotly backend test cases (#1938)
- Don't pass stacked in plotly area chart (#1934)
- Set upperbound of matplotlib to avoid failure on Ubuntu (#1959)
- Fix GroupBy.descirbe for multi-index columns. (#1922)
- Upgrade pandas version in CI (#1961)
- Compare Series from the same anchor (#1956)
- Add videos from Data+AI Summit 2020 EUROPE. (#1963)
- Set PYARROW_IGNORE_TIMEZONE for binder. (#1965)
Published by ueshin almost 4 years ago
Better type support
We improved the type mapping between pandas and Koalas (#1870, #1903). We added more types or string expressions to specify the data type or fixed mismatches between pandas and Koalas.
Here are some examples:
-
Added
np.float32and"float32"(matched toFloatType)>>> ks.Series([10]).astype(np.float32) 0 10.0 dtype: float32 >>> ks.Series([10]).astype("float32") 0 10.0 dtype: float32 -
Added
np.datetime64and"datetime64[ns]"(matched toTimestampType)>>> ks.Series(["2020-10-26"]).astype(np.datetime64) 0 2020-10-26 dtype: datetime64[ns] >>> ks.Series(["2020-10-26"]).astype("datetime64[ns]") 0 2020-10-26 dtype: datetime64[ns] -
Fixed
np.intto matchLongType, notIntegerType.>>> pd.Series([100]).astype(np.int) 0 100.0 dtype: int64 >>> ks.Series([100]).astype(np.int) 0 100.0 dtype: int32 # This fixed to `int64` now. -
Fixed
np.floatto matchDoubleType, notFloatType.>>> pd.Series([100]).astype(np.float) 0 100.0 dtype: float64 >>> ks.Series([100]).astype(np.float) 0 100.0 dtype: float32 # This fixed to `float64` now.
We also added a document which describes supported/unsupported pandas data types or data type mapping between pandas data types and PySpark data types. See: Type Support In Koalas.
Return type annotations for major Koalas objects
To improve Koala’s auto-completion in various editors and avoid misuse of APIs, we added return type annotations to major Koalas objects. These objects include DataFrame, Series, Index, GroupBy, Window objects, etc. (#1852, #1857, #1859, #1863, #1871, #1882, #1884, #1889, #1892, #1894, #1898, #1899, #1900, #1902).
The return type annotations help auto-completion libraries, such as Jedi, to infer the actual data type and provide proper suggestions:
- Before

- After

It also helps mypy enable static analysis over the method body.
pandas 1.1.4 support
We verified the behaviors of pandas 1.1.4 in Koalas.
As pandas 1.1.4 introduced a behavior change related to MultiIndex.is_monotonic (MultiIndex.is_monotonic_increasing) and MultiIndex.is_monotonic_decreasing (pandas-dev/pandas#37220), Koalas also changes the behavior (#1881).
Other new features and improvements
We added the following new features:
DataFrame:
-
__neg__(#1847) -
rename_axis(#1843) -
spark.repartition(#1864) -
spark.coalesce(#1873) -
spark.checkpoint(#1877) -
spark.local_checkpoint(#1878) -
reindex_like(#1880)
Series:
-
rename_axis(#1843) -
compare(#1802) -
reindex_like(#1880)
Index:
-
intersection(#1747)
MultiIndex:
-
intersection(#1747)
Other improvements and bug fixes
- Use SF.repeat in series.str.repeat (#1844)
- Remove warning when use cache in the context manager (#1848)
- Support a non-string name in Series' boxplot (#1849)
- Calculate fliers correctly in Series.plot.box (#1846)
- Show type name rather than type class in error messages (#1851)
- Fix DataFrame.spark.hint to reflect internal changes. (#1865)
- DataFrame.reindex supports named columns index (#1876)
- Separate InternalFrame.index_map into index_spark_column_names and index_names. (#1879)
- Fix DataFrame.xs to handle internal changes properly. (#1896)
- Explicitly disallow empty list as index_spark_colum_names and index_names. (#1895)
- Use nullable inferred schema in function apply (#1897)
- Introduce InternalFrame.index_level. (#1890)
- Remove InternalFrame.index_map. (#1901)
- Force to use the Spark's system default precision and scale when inferred data type contains DecimalType. (#1904)
- Upgrade PyArrow from 1.0.1 to 2.0.0 in CI (#1860)
- Fix read_excel to support squeeze argument. (#1905)
- Fix to_csv to avoid duplicated option 'path' for DataFrameWriter. (#1912)
Published by itholic about 4 years ago
pandas 1.1 support
We verified the behaviors of pandas 1.1 in Koalas. Koalas now supports pandas 1.1 officially (#1688, #1822, #1829).
Support for non-string names
Now we support for non-string names (#1784). Previously names in Koalas, e.g., df.columns, df.colums.names, df.index.names, needed to be a string or a tuple of string, but it should allow other data types which are supported by Spark.
Before:
>>> kdf = ks.DataFrame([[1, 'x'], [2, 'y'], [3, 'z']])
>>> kdf.columns
Index(['0', '1'], dtype='object')
After:
>>> kdf = ks.DataFrame([[1, 'x'], [2, 'y'], [3, 'z']])
>>> kdf.columns
Int64Index([0, 1], dtype='int64')
Improve distributed-sequence default index
The performance is improved when creating a distributed-sequence as a default index type by avoiding the interaction between Python and JVM (#1699).
Standardize binary operations between int and str columns
Make behaviors of binary operations (+, -, *, /, //, %) between int and str columns consistent with respective pandas behaviors (#1828).
It standardizes binary operations as follows:
-
+: raiseTypeErrorbetween int column and str column (or string literal) -
*: act as spark SQLrepeatbetween int column(or int literal) and str columns; raiseTypeErrorif a string literal is involved -
-,/,//,%(modulo): raiseTypeErrorif a str column (or string literal) is involved
Other new features and improvements
We added the following new features:
DataFrame:
-
product(#1739) -
from_dict(#1778) -
pad(#1786) -
backfill(#1798)
Series:
-
reindex(#1737) -
explode(#1777) -
pad(#1786) -
argmin(#1790) -
argmax(#1790) -
argsort(#1793) -
backfill(#1798)
Index:
-
inferred_type(#1745) -
item(#1744) -
is_unique(#1766) -
asi8(#1764) -
is_type_compatible(#1765) -
view(#1788) -
insert(#1804)
MultiIndex:
-
inferred_type(#1745) -
item(#1744) -
is_unique(#1766) -
asi8(#1764) -
is_type_compatible(#1765) -
from_frame(#1762) -
view(#1788) -
insert(#1804)
GroupBy:
-
get_group(#1783)
Other improvements
- Fix DataFrame.mad to work properly (#1749)
- Fix Series name after binary operations. (#1753)
- Fix GroupBy.cum~ for matching with pandas' behavior (#1708)
- Fix cumprod to work properly with Integer columns. (#1750)
- Fix DataFrame.join for MultiIndex (#1771)
- Exception handling for from_frame properly (#1791)
- Fix iloc for slice(None, 0) (#1767)
- Fix Series.__repr__ when Series.name is None. (#1796)
- DataFrame.reindex supports koalas Index parameter (#1741)
- Fix Series.fillna with inplace=True on non-nullable column. (#1809)
- Input check in various APIs (#1808, #1810, #1811, #1812, #1813, #1814, #1816, #1824)
- Fix to_list work properly in pandas==0.23 (#1823)
- Fix Series.astype to work properly (#1818)
- Frame.groupby supports dropna (#1815)
Published by ueshin about 4 years ago
Non-named Series support
Now we added support for non-named Series (#1712). Previously Koalas automatically named a Series "0" if no name is specified or None is set to the name, whereas pandas allows a Series without the name.
For example:
>>> ks.__version__
'1.1.0'
>>> kser = ks.Series([1, 2, 3])
>>> kser
0 1
1 2
2 3
Name: 0, dtype: int64
>>> kser.name = None
>>> kser
0 1
1 2
2 3
Name: 0, dtype: int64
Now the Series will be non-named.
>>> ks.__version__
'1.2.0'
>>> ks.Series([1, 2, 3])
0 1
1 2
2 3
dtype: int64
>>> kser = ks.Series([1, 2, 3], name="a")
>>> kser.name = None
>>> kser
0 1
1 2
2 3
dtype: int64
More stable "distributed-sequence" default index
Previously "distributed-sequence" default index had sometimes produced wrong values or even raised an exception. For example, the codes below:
>>> from databricks import koalas as ks
>>> ks.options.compute.default_index_type = 'distributed-sequence'
>>> ks.range(10).reset_index()
did not work as below:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
pyspark.sql.utils.PythonException:
An exception was thrown from the Python worker. Please see the stack trace below.
Traceback (most recent call last):
...
File "/.../koalas/databricks/koalas/internal.py", line 620, in offset
current_partition_offset = sums[id.iloc[0]]
KeyError: 103
We investigated and made the default index type more stable (#1701). Now it unlikely causes such situations and it is stable enough.
Improve testing infrastructure
We changed the testing infrastructure to use pandas' testing utils for exact check (#1722). Now it compares even index/column types and names so that we will be able to follow pandas more strictly.
Other new features and improvements
We added the following new features:
DataFrame:
-
last_valid_index(#1705)
Series:
-
product(#1677) -
last_valid_index(#1705)
GroupBy:
-
cumcount(#1702)
Other improvements
- Refine Spark I/O. (#1667)
- Set
partitionByexplicitly into_parquet. - Add
modeandpartition_colstoto_csvandto_json. - Fix type hints to use
Optional.
- Set
- Make read_excel read from DFS if the underlying Spark is 3.0.0 or above. (#1678, #1693, #1694, #1692)
- Support callable instances to apply as a function, and fix groupby.apply to keep the index when possible (#1686)
- Bug fixing for hasnans when non-DoubleType. (#1681)
- Support axis=1 for DataFrame.dropna(). (#1689)
- Allow assining index as a column (#1696)
- Try to read pandas metadata in read_parquet if index_col is None. (#1695)
- Include pandas Index object in dataframe indexing options (#1698)
- Unified
PlotAccessorfor DataFrame and Series (#1662) - Fix SeriesGroupBy.nsmallest/nlargest. (#1713)
- Fix DataFrame.size to consider its number of columns. (#1715)
- Fix first_valid_index() for Empty object (#1704)
- Fix index name when groupby.apply returns a single row. (#1719)
- Support subtraction of date/timestamp with literals. (#1721)
- DataFrame.reindex(fill_value) does not fill existing NaN values (#1723)
Published by ueshin over 4 years ago
API extensions
We added support for API extensions (#1617).
You can register your custom accessors to DataFrame, Seires, and Index.
For example, in your library code:
from databricks.koalas.extensions import register_dataframe_accessor
@register_dataframe_accessor("geo")
class GeoAccessor:
def __init__(self, koalas_obj):
self._obj = koalas_obj
# other constructor logic
@property
def center(self):
# return the geographic center point of this DataFrame
lat = self._obj.latitude
lon = self._obj.longitude
return (float(lon.mean()), float(lat.mean()))
def plot(self):
# plot this array's data on a map
pass
...
Then, in a session:
>>> from my_ext_lib import GeoAccessor
>>> kdf = ks.DataFrame({"longitude": np.linspace(0,10),
... "latitude": np.linspace(0, 20)})
>>> kdf.geo.center
(5.0, 10.0)
>>> kdf.geo.plot()
...
See also: https://koalas.readthedocs.io/en/latest/reference/extensions.html
Plotting backend
We introduced plotting.backend configuration (#1639).
Plotly (>=4.8) or other libraries that pandas supports can be used as a plotting backend if they are installed in the environment.
>>> kdf = ks.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8]], columns=["A", "B", "C", "D"])
>>> kdf.plot(title="Example Figure") # defaults to backend="matplotlib"
>>> fig = kdf.plot(backend="plotly", title="Example Figure", height=500, width=500)
>>> ## same as:
>>> # ks.options.plotting.backend = "plotly"
>>> # fig = kdf.plot(title="Example Figure", height=500, width=500)
>>> fig.show()
Each backend returns the figure in their own format, allowing for further editing or customization if required.
>>> fig.update_layout(template="plotly_dark")
>>> fig.show()
Koalas accessor
We introduced koalas accessor and some methods specific to Koalas (#1613, #1628).
DataFrame.apply_batch, DataFrame.transform_batch, and Series.transform_batch are deprecated and moved to koalas accessor.
>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pdf):
... return pdf + 1 # should always return the same length as input.
...
>>> kdf.koalas.transform_batch(pandas_plus)
a b
0 2 5
1 3 6
2 4 7
>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_filter(pdf):
... return pdf[pdf.a > 1] # allow arbitrary length
...
>>> kdf.koalas.apply_batch(pandas_filter)
a b
1 2 5
2 3 6
or
>>> kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
>>> def pandas_plus(pser):
... return pser + 1 # should always return the same length as input.
...
>>> kdf.a.koalas.transform_batch(pandas_plus)
0 2
1 3
2 4
Name: a, dtype: int64
See also: https://koalas.readthedocs.io/en/latest/user_guide/transform_apply.html
Other new features and improvements
We added the following new features:
DataFrame:
-
tail(#1632) -
droplevel(#1622)
Series:
-
iteritems(#1603) -
items(#1603) -
tail(#1632) -
droplevel(#1630)
Other improvements
- Simplify Series.to_frame. (#1624)
- Make Window functions create a new DataFrame. (#1623)
- Fix Series._with_new_scol to use alias. (#1634)
- Refine concat to handle the same anchor DataFrames properly. (#1627)
- Add sort parameter to concat. (#1636)
- Enable to assign list. (#1644)
- Use SPARK_INDEX_NAME_FORMAT in combine_frames to avoid ambiguity. (#1650)
- Rename spark columns only when index=False. (#1649)
- read_csv: Implement reading of number of rows (#1656)
- Fixed ks.Index.to_series() to work properly with name paramter (#1643)
- Fix fillna to handle "ffill" and "bfill" properly. (#1654)
Published by ueshin over 4 years ago
Critical bug fix
We fixed a critical bug introduced in Koalas 1.0.0 (#1609).
If we call DataFrame.rename with columns parameter after some operations on the DataFrame, the operations will be lost:
>>> kdf = ks.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8]], columns=["A", "B", "C", "D"])
>>> kdf1 = kdf + 1
>>> kdf1
A B C D
0 2 3 4 5
1 6 7 8 9
>>> kdf1.rename(columns={"A": "aa", "B": "bb"})
aa bb C D
0 1 2 3 4
1 5 6 7 8
This should be:
>>> pdf1.rename(columns={"A": "aa", "B": "bb"})
aa bb C D
0 2 3 4 5
1 6 7 8 9
Other improvements
- Clean up InternalFrame and around anchor. (#1601)
- Fixing DataFrame.iteritems to return generator (#1602)
- Clean up groupby to use the anchor. (#1610)
Published by HyukjinKwon over 4 years ago
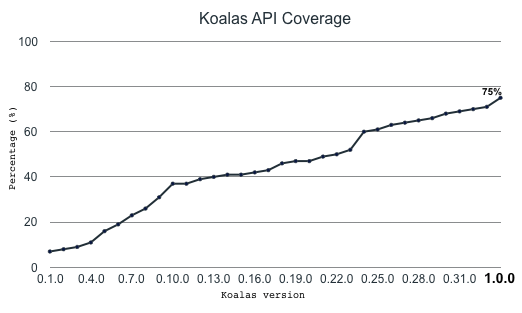
Better pandas API coverage
We implemented many APIs and features equivalent with pandas such as plotting, grouping, windowing, I/O, and transformation, and now Koalas reaches the pandas API coverage close to 80% in Koalas 1.0.0.
Apache Spark 3.0
Apache Spark 3.0 is now supported in Koalas 1.0 (#1586, #1558). Koalas does not require any change to use Spark 3.0. Apache Spark has more than 3400 fixes landed in Spark 3.0 and Koalas shares the most of fixes in many other components.
It also brings the performance improvement in Koalas APIs that execute Python native functions internally via pandas UDFs, for example, DataFrame.apply and DataFrame.apply_batch (#1508).
Python 3.8
With Apache Spark 3.0, Koalas supports the latest Python 3.8 which has many significant improvements (#1587), see also Python 3.8.0 release notes.
Spark accessor
spark accessor was introduced from Koalas 1.0.0 in order for the Koalas users to leverage the existing PySpark APIs more easily (#1530). For example, you can apply the PySpark functions as below:
import databricks.koalas as ks
import pyspark.sql.functions as F
kss = ks.Series([1, 2, 3, 4])
kss.spark.apply(lambda s: F.collect_list(s))
Better type hint support
In the early versions, it was required to use Koalas instances as the return type hints for the functions that return a pandas instances, which looks slightly awkward.
def pandas_div(pdf) -> koalas.DataFrame[float, float]:
# pdf is a pandas DataFrame,
return pdf[['B', 'C']] / pdf[['B', 'C']]
df = ks.DataFrame({'A': ['a', 'a', 'b'], 'B': [1, 2, 3], 'C': [4, 6, 5]})
df.groupby('A').apply(pandas_div)
In Koalas 1.0.0 with Python 3.7+, you can also use pandas instances in the return type as below:
def pandas_div(pdf) -> pandas.DataFrame[float, float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
In addition, the new type hinting is experimentally introduced in order to allow users to specify column names in the type hints as below (#1577):
def pandas_div(pdf) -> pandas.DataFrame['B': float, 'C': float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
See also the guide in Koalas documentation (#1584) for more details.
Wider support of in-place update
Previously in-place updates happen only within each DataFrame or Series, but now the behavior follows pandas in-place updates and the update of one side also updates the other side (#1592).
For example, the following updates kdf as well.
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.fillna(0, inplace=True)
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.loc[2] = 30
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kdf.loc[2, 'x'] = 30
If the DataFrame and Series are connected, the in-place updates update each other.
Less restriction on compute.ops_on_diff_frames
In Koalas 1.0.0, the restriction of compute.ops_on_diff_frames became much more loosened (#1522, #1554). For example, the operations such as below can be performed without enabling compute.ops_on_diff_frames, which can be expensive due to the shuffle under the hood.
df + df + df
df['foo'] = df['bar']['baz']
df[['x', 'y']] = df[['x', 'y']].fillna(0)
Other new features and improvements
DataFrame:
-
__bool__(#1526) -
explode(#1507) -
spark.apply(#1536) -
spark.schema(#1530) -
spark.print_schema(#1530) -
spark.frame(#1530) -
spark.cache(#1530) -
spark.persist(#1530) -
spark.hint(#1530) -
spark.to_table(#1530) -
spark.to_spark_io(#1530) -
spark.explain(#1530) -
spark.apply(#1530) -
mad(#1538) -
__abs__(#1561)
Series:
-
item(#1502, #1518) -
divmod(#1397) -
rdivmod(#1397) -
unstack(#1501) -
mad(#1503) -
__bool__(#1526) -
to_markdown(#1510) -
spark.apply(#1536) -
spark.data_type(#1530) -
spark.nullable(#1530) -
spark.column(#1530) -
spark.transform(#1530) -
filter(#1511) -
__abs__(#1561) -
bfill(#1580) -
ffill(#1580)
Index:
-
__bool__(#1526) -
spark.data_type(#1530) -
spark.column(#1530) -
spark.transform(#1530) -
get_level_values(#1517) -
delete(#1165) -
__abs__(#1561) -
holds_integer(#1547)
MultiIndex:
-
__bool__(#1526) -
spark.data_type(#1530) -
spark.column(#1530) -
spark.transform(#1530) -
get_level_values(#1517) -
delete(#1165 -
__abs__(#1561) -
holds_integer(#1547)
Along with the following improvements:
- Fix Series.clip not to create a new DataFrame. (#1525)
- Fix combine_first to support tupled names. (#1534)
- Add Spark accessors to usage logging. (#1540)
- Implements multi-index support in Dataframe.filter (#1512)
- Fix Series.fillna to avoid Spark jobs. (#1550)
- Support DataFrame.spark.explain(extended: str) case. (#1563)
- Support Series as repeats in Series.repeat. (#1573)
- Fix fillna to handle NaN properly. (#1572)
- Fix DataFrame.replace to avoid creating a new Spark DataFrame. (#1575)
- Cache an internal pandas object to avoid run twice in Jupyter. (#1564)
- Fix Series.div when div/floordiv np.inf by zero (#1463)
- Fix Series.unstack to support non-numeric type and keep the names (#1527)
- Fix hasnans to follow the modified column. (#1532)
- Fix explode to use internal methods. (#1538)
- Fix RollingGroupby and ExpandingGroupby to handle agg_columns. (#1546)
- Fix reindex not to update internal. (#1582)
Backward Compatibility
- Remove the deprecated pandas_wraps (#1529)
- Remove compute function. (#1531)
Published by ueshin over 4 years ago
apply and transform Improvements
We added supports to have positional/keyword arguments for apply, apply_batch, transform, and transform_batch in DataFrame, Series, and GroupBy. (#1484, #1485, #1486)
>>> ks.range(10).apply(lambda a, b, c: a + b + c, args=(1,), c=3)
id
0 4
1 5
2 6
3 7
4 8
5 9
6 10
7 11
8 12
9 13
>>> ks.range(10).transform_batch(lambda pdf, a, b, c: pdf.id + a + b + c, 1, 2, c=3)
0 6
1 7
2 8
3 9
4 10
5 11
6 12
7 13
8 14
9 15
Name: id, dtype: int64
>>> kdf = ks.DataFrame(
... {"a": [1, 2, 3, 4, 5, 6], "b": [1, 1, 2, 3, 5, 8], "c": [1, 4, 9, 16, 25, 36]},
... columns=["a", "b", "c"])
>>> kdf.groupby(["a", "b"]).apply(lambda x, y, z: x + x.min() + y + z, 1, z=2)
a b c
0 5 5 5
1 7 5 11
2 9 7 21
3 11 9 35
4 13 13 53
5 15 19 75
Spark Schema
We add spark_schema and print_schema to know the underlying Spark Schema. (#1446)
>>> kdf = ks.DataFrame({'a': list('abc'),
... 'b': list(range(1, 4)),
... 'c': np.arange(3, 6).astype('i1'),
... 'd': np.arange(4.0, 7.0, dtype='float64'),
... 'e': [True, False, True],
... 'f': pd.date_range('20130101', periods=3)},
... columns=['a', 'b', 'c', 'd', 'e', 'f'])
>>> # Print the schema out in Spark’s DDL formatted string
>>> kdf.spark_schema().simpleString()
'struct<a:string,b:bigint,c:tinyint,d:double,e:boolean,f:timestamp>'
>>> kdf.spark_schema(index_col='index').simpleString()
'struct<index:bigint,a:string,b:bigint,c:tinyint,d:double,e:boolean,f:timestamp>'
>>> # Print out the schema as same as DataFrame.printSchema()
>>> kdf.print_schema()
root
|-- a: string (nullable = false)
|-- b: long (nullable = false)
|-- c: byte (nullable = false)
|-- d: double (nullable = false)
|-- e: boolean (nullable = false)
|-- f: timestamp (nullable = false)
>>> kdf.print_schema(index_col='index')
root
|-- index: long (nullable = false)
|-- a: string (nullable = false)
|-- b: long (nullable = false)
|-- c: byte (nullable = false)
|-- d: double (nullable = false)
|-- e: boolean (nullable = false)
|-- f: timestamp (nullable = false)
GroupBy Improvements
We fixed many bugs of GroupBy as listed below.
- Fix groupby when as_index=False. (#1457)
- Make groupby.apply in pandas<0.25 run the function only once per group. (#1462)
- Fix Series.groupby on the Series from different DataFrames. (#1460)
- Fix GroupBy.head to recognize agg_columns. (#1474)
- Fix GroupBy.filter to follow complex group keys. (#1471)
- Fix GroupBy.transform to follow complex group keys. (#1472)
- Fix GroupBy.apply to follow complex group keys. (#1473)
- Fix GroupBy.fillna to use GroupBy._apply_series_op. (#1481)
- Fix GroupBy.filter and apply to handle agg_columns. (#1480)
- Fix GroupBy apply, filter, and head to ignore temp columns when ops from different DataFrames. (#1488)
- Fix GroupBy functions which need natural orderings to follow the order when opts from different DataFrames. (#1490)
Other new features and improvements
We added the following new feature:
SeriesGroupBy:
-
filter(#1483)
Other improvements
- dtype for DateType should be np.dtype("object"). (#1447)
- Make reset_index disallow the same name but allow it when drop=True. (#1455)
- Fix named aggregation for MultiIndex (#1435)
- Raise ValueError that is not raised now (#1461)
- Fix get dummies when uses the prefix parameter whose type is dict (#1478)
- Simplify DataFrame.columns setter. (#1489)
Published by HyukjinKwon over 4 years ago
Koalas documentation redesign
Koalas documentation was redesigned with a better theme, pydata-sphinx-theme. Please check the new Koalas documentation site out.

transform_batch and apply_batch
We added the APIs that enable you to directly transform and apply a function against Koalas Series or DataFrame. map_in_pandas is deprecated and now renamed to apply_batch.
import databricks.koalas as ks
kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1 # should always return the same length as input.
kdf.transform_batch(pandas_plus)
import databricks.koalas as ks
kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1] # allow arbitrary length
kdf.apply_batch(pandas_plus)
Please also check Transform and apply a function in Koalas documentation.
Other new features and improvements
We added the following new feature:
DataFrame:
-
truncate(#1408) -
hint(#1415)
SeriesGroupBy:
-
unique(#1426)
Index:
-
spark_column(#1438)
Series:
-
spark_column(#1438)
MultiIndex:
-
spark_column(#1438)
Other improvements
- Fix from_pandas to handle the same index name as a column name. (#1419)
- Add documentation about non-Koalas APIs (#1420)
- Hot-fixing the lack of keyword argument 'deep' for DataFrame.copy() (#1423)
- Fix Series.div when divide by zero (#1412)
- Support expand parameter if n is a positive integer in Series.str.split/rsplit. (#1432)
- Make Series.astype(bool) follow the concept of "truthy" and "falsey". (#1431)
- Fix incompatible behaviour with pandas for floordiv with np.nan (#1429)
- Use mapInPandas for apply_batch API in Spark 3.0 (#1440)
- Use F.datediff() for subtraction of dates as a workaround. (#1439)
Published by ueshin over 4 years ago
PyArrow>=0.15 support is back
We added PyArrow>=0.15 support back (#1110).
Note that, when working with pyarrow>=0.15 and pyspark<3.0, Koalas will set an environment variable ARROW_PRE_0_15_IPC_FORMAT=1 if it does not exist, as per the instruction in SPARK-29367, but it will NOT work if there is a Spark context already launched. In that case, you have to manage the environment variable by yourselves.
Spark specific improvements
Broadcast hint
We added broadcast function in namespace.py (#1360).
We can use it with merge, join, and update which invoke join operation in Spark when you know one of the DataFrame is small enough to fit in memory, and we can expect much more performant than shuffle-based joins.
For example,
>>> merged = df1.merge(ks.broadcast(df2), left_on='lkey', right_on='rkey')
>>> merged.explain()
== Physical Plan ==
...
...BroadcastHashJoin...
...
persist function and storage level
We added persist function to specify the storage level when caching (#1381), and also, we added storage_level property to check the current storage level (#1385).
>>> with df.cache() as cached_df:
... print(cached_df.storage_level)
...
Disk Memory Deserialized 1x Replicated
>>> with df.persist(pyspark.StorageLevel.MEMORY_ONLY) as cached_df:
... print(cached_df.storage_level)
...
Memory Serialized 1x Replicated
Other new features and improvements
We added the following new feature:
DataFrame:
-
to_markdown(#1377) -
squeeze(#1389)
Series:
-
squeeze(#1389) -
asof(#1366)
Other improvements
- Add a way to specify index column in I/O APIs (#1379)
- Fix
iloc.__setitem__with the other Series from the same DataFrame. (#1388) - Add support Series from different DataFrames for
loc/iloc.__setitem__. (#1391) - Refine
__setitem__for loc/iloc with DataFrame. (#1394) - Help misuse of options argument. (#1402)
- Add blog posts in Koalas documentation (#1406)
- Fix mod & rmod for matching with pandas. (#1399)
Published by HyukjinKwon over 4 years ago
Slice column selection support in loc
We continue to improve loc indexer and added the slice column selection support (#1351).
>>> from databricks import koalas as ks
>>> df = ks.DataFrame({'a':list('abcdefghij'), 'b':list('abcdefghij'), 'c': range(10)})
>>> df.loc[:, "b":"c"]
b c
0 a 0
1 b 1
2 c 2
3 d 3
4 e 4
5 f 5
6 g 6
7 h 7
8 i 8
9 j 9
Slice row selection support in loc for multi-index
We also added the support of slice as row selection in loc indexer for multi-index (#1344).
>>> from databricks import koalas as ks
>>> import pandas as pd
>>> df = ks.DataFrame({'a': range(3)}, index=pd.MultiIndex.from_tuples([("a", "b"), ("a", "c"), ("b", "d")]))
>>> df.loc[("a", "c"): "b"]
a
a c 1
b d 2
Slice row selection support in iloc
We continued to improve iloc indexer to support iterable indexes as row selection (#1338).
>>> from databricks import koalas as ks
>>> df = ks.DataFrame({'a':list('abcdefghij'), 'b':list('abcdefghij')})
>>> df.iloc[[-1, 1, 2, 3]]
a b
1 b b
2 c c
3 d d
9 j j
Support of setting values via loc and iloc at Series
Now, we added the basic support of setting values via loc and iloc at Series (#1367).
>>> from databricks import koalas as ks
>>> kser = ks.Series([1, 2, 3], index=["cobra", "viper", "sidewinder"])
>>> kser.loc[kser % 2 == 1] = -kser
>>> kser
cobra -1
viper 2
sidewinder -3
Other new features and improvements
We added the following new feature:
DataFrame:
-
take(#1292) -
eval(#1359)
Series:
-
dot(#1136) -
take(#1357) -
combine_first(#1290)
Index:
-
droplevel(#1340) -
union(#1348) -
take(#1357) -
asof(#1350)
MultiIndex:
-
droplevel(#1340) -
unique(#1342) -
union(#1348) -
take(#1357)
Other improvements
- Compute Index.is_monotonic/Index.is_monotonic_decreasing in a distributed manner (#1354)
- Fix SeriesGroupBy.apply() to respect various output (#1339)
- Add the support for operations between different DataFrames in groupby() (#1321)
- Explicitly don't support to disable numeric_only in stats APIs at DataFrame (#1343)
- Fix index operator against Series and Frame to use iloc conditionally (#1336)
- Make nunique in DataFrame to return a Koalas DataFrame instead of pandas' (#1347)
- Fix MultiIndex.drop() to follow renaming et al. (#1356)
- Add column axis in ks.concat (#1349)
- Fix iloc for Series when the series is modified. (#1368)
- Support MultiIndex for duplicated, drop_duplicates. (#1363)
Published by ueshin over 4 years ago
Slice support in iloc
We improved iloc indexer to support slice as row selection. (#1335)
For example,
>>> kdf = ks.DataFrame({'a':list('abcdefghij')})
>>> kdf
a
0 a
1 b
2 c
3 d
4 e
5 f
6 g
7 h
8 i
9 j
>>> kdf.iloc[2:5]
a
2 c
3 d
4 e
>>> kdf.iloc[2:-3:2]
a
2 c
4 e
6 g
>>> kdf.iloc[5:]
a
5 f
6 g
7 h
8 i
9 j
>>> kdf.iloc[5:2]
Empty DataFrame
Columns: [a]
Index: []
Documentation
We added links to the previous talks in our document. (#1319)
You can see a lot of useful talks from the previous events and we will keep updated.
https://koalas.readthedocs.io/en/latest/getting_started/videos.html
Other new features and improvements
We added the following new feature:
DataFrame:
-
stack(#1329)
Series:
-
repeat(#1328)
Index:
-
difference(#1325) -
repeat(#1328)
MultiIndex:
-
difference(#1325) -
repeat(#1328)
Other improvements
- DataFrame.pivot should preserve the original index names. (#1316)
- Fix _LocIndexerLike to handle a Series from index. (#1315)
- Support MultiIndex in DataFrame.unstack. (#1322)
- Support Spark UDT when converting from/to pandas DataFrame/Series. (#1324)
- Allow negative numbers for head. (#1330)
- Return a Koalas series instead of pandas' in stats APIs at Koalas DataFrame (#1333)
Published by HyukjinKwon over 4 years ago
pandas 1.0 support
We added pandas 1.0 support (#1197, #1299), and Koalas now can work with pandas 1.0.
map_in_pandas
We implemented DataFrame.map_in_pandas API (#1276) so Koalas can allow any arbitrary function with pandas DataFrame against Koalas DataFrame. See the example below:
>>> import databricks.koalas as ks
>>> df = ks.DataFrame({'A': range(2000), 'B': range(2000)})
>>> def query_func(pdf):
... num = 1995
... return pdf.query('A > @num')
...
>>> df.map_in_pandas(query_func)
A B
1996 1996 1996
1997 1997 1997
1998 1998 1998
1999 1999 1999
Standardize code style using Black
As a development only change, we added Black integration (#1301). Now, all code style is standardized automatically via running ./dev/reformat, and the style is checked as a part of ./dev/lint-python.
Other new features and improvements
We added the following new feature:
DataFrame:
-
query(#1273) -
unstack(#1295)
Other improvements
- Fix
DataFrame.describe()to support multi-index columns. (#1279) - Add util function validate_bool_kwarg (#1281)
- Rename data columns prior to filter to make sure the column names are as expected. (#1283)
- Add an faq about Structured Streaming. (#1298)
- Let extra options have higher priority to allow workarounds (#1296)
- Implement 'keep' parameter for
drop_duplicates(#1303) - Add a note when type hint is provided to DataFrame.apply (#1310)
- Add a util method to verify temporary column names. (#1262)
Published by ueshin over 4 years ago
head ordering
Since Koalas doesn't guarantee the row ordering, head could return some rows from distributed partition and the result is not deterministic, which might confuse users.
We added a configuration compute.ordered_head (#1231), and if it is set to True, Koalas performs natural ordering beforehand and the result will be the same as pandas'.
The default value is False because the ordering will cause a performance overhead.
>>> kdf = ks.DataFrame({'a': range(10)})
>>> pdf = kdf.to_pandas()
>>> pdf.head(3)
a
0 0
1 1
2 2
>>> kdf.head(3)
a
5 5
6 6
7 7
>>> kdf.head(3)
a
0 0
1 1
2 2
>>> ks.options.compute.ordered_head = True
>>> kdf.head(3)
a
0 0
1 1
2 2
>>> kdf.head(3)
a
0 0
1 1
2 2
GitHub Actions
We started trying to use GitHub Actions for CI. (#1254, #1265, #1264, #1267, #1269)
Other new features and improvements
We added the following new feature:
DataFrame:
- apply (#1259)
Other improvements
- Fix identical and equals for the comparison between the same object. (#1220)
- Select the series correctly in SeriesGroupBy APIs (#1224)
- Fixes
DataFrame/Series.clipfunction to preserve its index. (#1232) - Throw a better exception in
DataFrame.sort_valueswhen multi-index column is used (#1238) - Fix
fillnanot to change index values. (#1241) - Fix
DataFrame.__setitem__with tuple-named Series. (#1245) - Fix
corrto support multi-index columns. (#1246) - Fix output of
print()matches with pandas of Series (#1250) - Fix fillna to support partial column index for multi-index columns. (#1244)
- Add as_index check logic to groupby parameter (#1253)
- Raising NotImplementedError for elements that actually are not implemented. (#1256)
- Fix where to support multi-index columns. (#1249)
Published by HyukjinKwon over 4 years ago
iat indexer
We continued to improve indexers. Now, iat indexer is supported too (#1062).
>>> df = ks.DataFrame([[0, 2, 3], [0, 4, 1], [10, 20, 30]],
... columns=['A', 'B', 'C'])
>>> df
A B C
0 0 2 3
1 0 4 1
2 10 20 30
>>> df.iat[1, 2]
1
Other new features and improvements
We added the following new features:
koalas.Index
-
equals(#1216) -
identical(#1215) -
is_all_dates(#1205) -
append(#1163) -
to_frame(#1187)
koalas.MultiIndex:
-
equals(#1216) -
identical(#1215) -
swaplevel(#1105) -
is_all_dates(#1205) -
is_monotonic_increasing(#1183) -
is_monotonic_decreasing(#1183) -
append(#1163) -
to_frame(#1187)
koalas.DataFrameGroupBy
-
describe(#1168)
Other improvements
- Change default write mode to overwrite to be consistent with pandas (#1209)
- Prepare Spark 3 (#1211, #1181)
- Fix
DataFrame.idxmin/idxmax. (#1198) - Fix reset_index with the default index is "distributed-sequence". (#1193)
- Fix column name as a tuple in multi column index (#1191)
- Add favicon to doc (#1189)

